SQL Statements
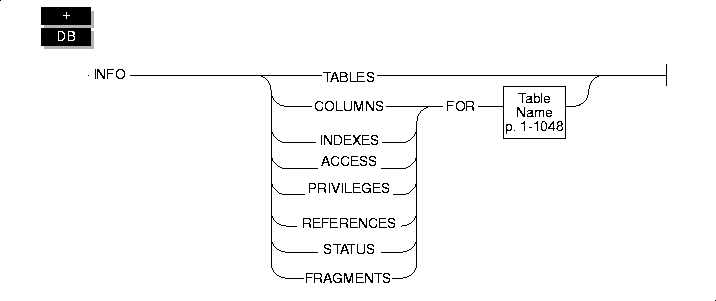
INFO
Use the INFO statement to display a variety of information about databases and tables.
Syntax
Usage
You can use keywords in the INFO statement to display the following information.
Instead of using the INFO statement, you can use the Info options on the SQL menu or the TABLE menu to display the same and additional information.
TABLES Keyword
Use the TABLES keyword to display a list of the tables and views in the current database. The name of a table can appear in one of the following ways:
INFO statement requesting table information for the stores7 database
Display of table information
In this display, the TABLES keyword provides information for the user-defined tables and views of the stores7 database. It does not display the system catalog tables and system catalog views.
COLUMNS Keyword
Use the COLUMNS keyword to display the names and data types of the columns in a specified table and whether null values are allowed. The following examples show an INFO statement and the resulting display of information about the columns in a table:
INFO statement requesting column information
Display of column information
The COLUMNS keyword provides information for built-in data types (such as INTEGER, CHAR, and DATETIME) as well as user-defined data types (such as collection types, row types, and opaque types).
INDEXES Keyword
Use the INDEXES keyword to display the following information for each index on a table: the index name, the index owner, the index type (unique or duplicate), whether the index is clustered, the index access method used (functional, B-tree, and so on), and the names of the columns that are indexed.
The following examples show an INFO statement and the resulting display of information about the indexes of a table.
INFO statement requesting index information
Display of index information
FRAGMENTS Keyword
Use the FRAGMENTS keyword to display the dbspace names where fragments are located for a specified table. The following examples show an INFO statement and the resulting display of fragments for a table that is fragmented with a round-robin distribution scheme. An INFO statement that is executed on a table that is fragmented with an expression-based distribution scheme would show the expressions and the dbspaces.
INFO statement requesting fragment information
Display of fragment information
Displaying Privileges, References, and Status
You can use keywords in your INFO statement to display information about the access privileges (including the References privilege) or the status of a table.
ACCESS or PRIVILEGES Keyword
Use the ACCESS or PRIVILEGES keywords to display user access privileges for a specified table. The following examples show an INFO statement and the resulting display of user privileges for a table:
INFO statement requesting privileges information
Display of privileges information
REFERENCES Keyword
Use the REFERENCES keyword to display the References privilege for users for the columns of a specified table. The following examples show an INFO statement and the resulting display:
INFO statement requesting References privilege information
Display of References privilege information
The output indicates that the user betty can reference columns col1, col2, and col3 of the specified table; the user wilma can reference all the columns in the table; and public cannot access any columns in the table.
If you want information about database-level privileges, you must use a SELECT statement to access the sysusers system catalog table.
See the GRANT and REVOKE statements for more information about database and table-access privileges.
STATUS Keyword
Use the STATUS keyword to display information about the owner, row length, number of rows and columns, and creation date for a specified table. The following example displays status information for the cust_calls table:
INFO statement requesting status information
Display of status information
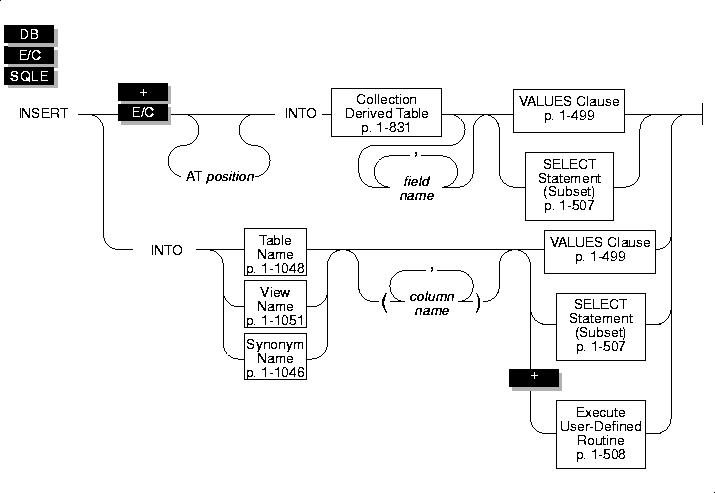
INSERT
Use the INSERT statement to insert one or more new rows into a table or view, or one or more elements into an SPL or INFORMIX-ESQL/C collection variable.
Syntax
Usage
Use the INSERT statement to create either of the following types of objects:
For information on how to insert an element into a collection variable, see "Inserting Into a Collection Variable". The other sections of this INSERT statement describe how to create a row in a table.
To insert data into a table, you must either own the table or have the Insert privilege for the table (see the GRANT statement on page 1-461). To insert data into a view, you must have the required Insert privilege, and the view must meet the requirements explained in "Inserting Rows Through a View".
If you insert data into a table that has data integrity constraints associated with it, the inserted data must meet the constraint criteria. If it does not, the database server returns an error.
If you are using effective checking, and the checking mode is set to IMMEDIATE, all specified constraints are checked at the end of each INSERT statement. If the checking mode is set to DEFERRED, all specified constraints are not checked until the transaction is committed.
Specifying Columns
If you do not explicitly specify one or more columns, data is inserted into columns using the column order that was established when the table was created or last altered. The column order is listed in the syscolumns system catalog table.
You can use the DESCRIBE statement with an INSERT statement to determine the column order and the data type of the columns in a table. (For more information about the DESCRIBE statement, see page 1-338.) 
The number of columns specified in the INSERT INTO clause must equal the number of values supplied in the VALUES clause or by the SELECT statement, either implicitly or explicitly. If you specify columns, the columns receive data in the order in which you list them. The first value following the VALUES keyword is inserted into the first column listed, the second value is inserted into the second column listed, and so on.
Inserting Rows Through a View
You can insert data through a single-table view if you have the Insert privilege on the view. To do this, the defining SELECT statement can select from only one table, and it cannot contain any of the following components:
Columns in the underlying table that are unspecified in the view receive either a default value or a null value if no default is specified. If one of these columns does not specify a default value, and a null value is not allowed, the insert fails.
You can use data-integrity constraints to prevent users from inserting values into the underlying table that do not fit the view-defining SELECT statement. For further information, refer to the WITH CHECK OPTION discussion under the CREATE VIEW statement on page 1-289.
If several users are entering sensitive information into a single table, the USER function can limit their view to only the specific rows that each user inserted. The following example contains a view and an INSERT statement that achieve this effect:
Inserting Rows with a Cursor
If you associate a cursor with an INSERT statement, you must use the OPEN, PUT, and CLOSE statements to carry out the INSERT operation. For databases that have transactions but are not ANSI compliant, you must issue these statements within a transaction.
If you are using a cursor that is associated with an INSERT statement, the rows are buffered before they are written to the disk. The insert buffer is flushed under the following conditions:
When the insert buffer is flushed, the client processor performs appropriate data conversion before it sends the rows to the database server. When the database server receives the buffer, it converts any user-defined data types and then begins to insert the rows one at a time into the database. If an error is encountered while the database server inserts the buffered rows into the database, any buffered rows following the last successfully inserted rows are discarded.
Inserting Rows into a Database Without Transactions
If you are inserting rows into a database without transactions, you must take explicit action to restore inserted rows after a failure. For example, if the INSERT statement fails after you insert some rows, the successfully inserted rows remain in the table. You cannot recover automatically from a failed insert.
Inserting Rows into a Database with Transactions
If you are inserting rows into a database with transactions, and you are using explicit transactions, use the ROLLBACK WORK statement to undo the insertion. If you do not execute BEGIN WORK before the insert, and the insert fails, the database server automatically rolls back any database modifications made since the beginning of the insert.
If you are inserting rows into an ANSI-compliant database, transactions are implicit, and all database modifications take place within a transaction. In this case, if an INSERT statement fails, use the ROLLBACK WORK statement to undo the insertions.
When you use INFORMIX-Universal Server within an explicit transaction, and the update fails, the database server automatically undoes the effects of the update.
Rows that you insert within a transaction remain locked until the end of the transaction. The end of a transaction is either a COMMIT WORK statement, where all modifications are made to the database, or a ROLLBACK WORK statement, where none of the modifications are made to the database. If many rows are affected by a single INSERT statement, you can exceed the maximum number of simultaneous locks permitted. To prevent this situation, either insert fewer rows per transaction or lock the page, or the entire table, before you execute the INSERT statement.
VALUES Clause
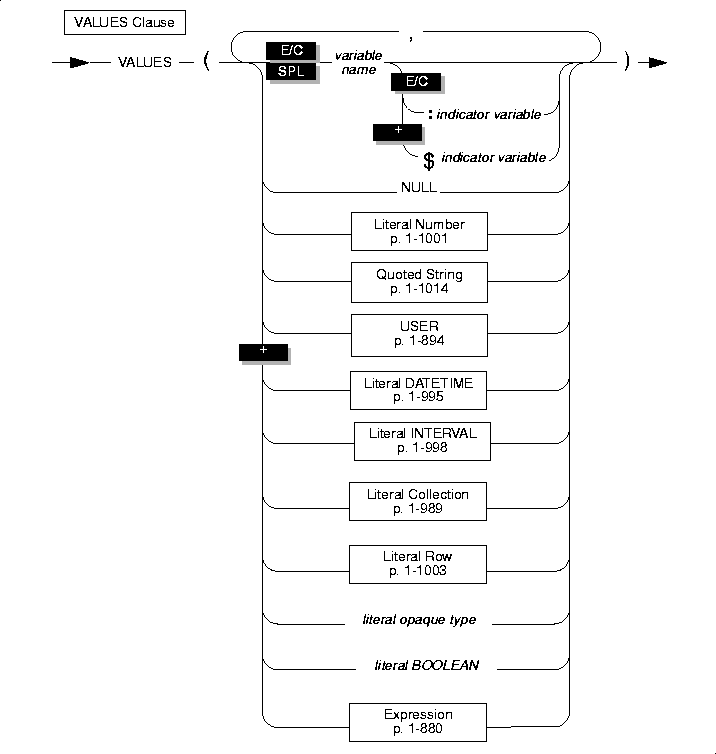
|
When you use the VALUES clause, you can insert only one row at a time. Each value that follows the VALUES keyword is assigned to the corresponding column listed in the INSERT INTO clause (or in column order if a list of columns is not specified).
If you are inserting a quoted string into a column, the maximum length of the string is 256 bytes. If you insert a value greater than 256, the database server returns an error.
If you are using variables, you can insert quoted strings longer than 256 bytes into a table.
Data Type Compatibility and Casting
The value that you insert into a column does not have to be of the same data type as the column that receives it. However, these two data types must be compatible. Two data types are compatible if the database server has some way to cast one data type to another. A cast is the mechanism by which the database server converts one data type to another. For a summary of the casting that the database server provides, see Chapter 2 of the Informix Guide to SQL: Reference. For information on how to create a user-defined cast, see the CREATE CAST statement in this manual and the Extending INFORMIX-Universal Server: Data Types manual.
Inserting Values into Character Columns
 With INFORMIX-ESQL/C, if you use a host variable to insert a value in a character column (CHAR, VARCHAR, or LVARCHAR) of a database that is ANSI compliant, the string within the host variable must be null terminated. The database server generates an error if you try to insert a string that is not null terminated. For more information, refer to the chapter on character data types in the INFORMIX-ESQL/C Programmer's Manual. With INFORMIX-ESQL/C, if you use a host variable to insert a value in a character column (CHAR, VARCHAR, or LVARCHAR) of a database that is ANSI compliant, the string within the host variable must be null terminated. The database server generates an error if you try to insert a string that is not null terminated. For more information, refer to the chapter on character data types in the INFORMIX-ESQL/C Programmer's Manual.
Inserting Values into TEXT and BYTE Columns
You can use the INSERT statement on tables with TEXT or BYTE columns if you:
For example, the following INSERT statement inserts a new row into the catalog table:
For example, the following INSERT statement inserts the same new row into the catalog table:
You cannot use literal values within an INSERT statement to put simple large-object data within a TEXT or BYTE column. To insert values into a TEXT or BYTE column, you can use any of the following methods:
For more information, see the description of LOAD in this chapter.
For more information, see the chapter on simple large objects in the INFORMIX-ESQL/C Programmer's Manual.
Inserting Values into SERIAL and SERIAL8 Columns
If you want to insert consecutive serial values in a SERIAL or SERIAL8 column in the table, specify a zero for a SERIAL or SERIAL8 column in the INSERT statement. When a SERIAL or SERIAL8 column is set to zero, the database server assigns the next highest value. If you want to enter an explicit value in a SERIAL or SERIAL8 column, specify the nonzero value after you first verify that the value does not duplicate one already in the table. If the SERIAL or SERIAL8 column is uniquely indexed or has a unique constraint, and you try to insert a value that duplicates one already in the table, an error occurs. For more information about the SERIAL and SERIAL8 data types, see Chapter 2 of the Informix Guide to SQL: Reference.
Inserting Values into Opaque-Type Columns
Some opaque data types require special processing when they are inserted. For example, if an opaque data type contains spatial or multirepresentational data, it might provide a choice of how to store the data: inside the internal structure or, for very large objects, in a smart large object.
This processing is accomplished by calling a user-defined support function called assign(). When you execute the INSERT statement on a table whose rows contains one of these opaque types, the database server automatically invokes the assign() function for the type. The assign() function can make the decision of how to store the data. For more information about the assign() support function, see the Extending INFORMIX-Universal Server: Data Types manual.
Inserting Values into Collection Columns
You can use the VALUES clause to insert literal values into a collection column, which can be a LIST, MULTISET, or SET. For example, suppose you define the tab1 table as follows:
The following INSERT statement adds literal values as a row in the tab1 table:
The collection column, list1, in the tab1 row has three elements, each element is an unnamed row type with an INTEGER field and a CHAR(5) field. For more information on the syntax for literal collection values, see "Literal DATETIME".
You can use ESQL/C host variables to insert:
Use a collection variable as a variable name in the VALUES clause to insert an entire collection. For example, the following ESQL/C code fragment inserts the elements of the a_set host variable into the set_col column of the tab_a table:
To insert non-literal values into a collection column, you must first insert the elements in a collection variable and then specify the collection variable in the SET clause of an UPDATE statement. For information on how to insert values into a collection variable, see "Inserting Into a Collection Variable".
Inserting Values into Row-Type Columns
You can use the VALUES clause to insert literal and nonliteral values in a named row type or unnamed row type column. For example, suppose you define the following named row type and table:
The following INSERT statement inserts literal values in the name and address columns of the employee table:
The INSERT statement uses ROW constructors to generate values for the name column (an unnamed row type) and the address column (a named row type). When you specify a value for a named row type, you must use the CAST AS keyword or the double colon (::) operator, in conjunction with the name of the named row type, to cast the value to the named row type.
For more information on the syntax for ROW constructors, see "Constructor Expressions" in the Expression segment. For information on literal values for named row types and unnamed row types, see the Literal Row segment on page 1-1003.
You can use ESQL/C host variables to insert non-literal values as:
Use a row variable as a variable name in the VALUES clause to insert values for all fields in a row column at one time.
To insert nonliteral values in a row-type column, you can first insert the elements in a row variable and then specify the collection variable in the SET clause of an UPDATE statement.
When you use a row variable in the VALUES clause, the row variable must contain values for each field value. For information on how to insert values in a row variable, see "Inserting into a Row Variable".
Using Expressions in the VALUES Clause
You can insert any type of expression into a column. For example, you can insert a cast expression or a function that returns the current date, date and time, login name of the current user, or database server name of the current Universal Server instance.
The TODAY keyword returns the system date. The CURRENT keyword returns the system date and time. The USER keyword returns an eight-character string that contains the login account name of the current user. The SITENAME or DBSERVERNAME keyword returns the database server name where the current database resides. The following example uses the CURRENT and USER keywords to insert a new row into the cust_calls table:
For more information, see the Expression segment on page 1-880.
Inserting Nulls with the VALUES Clause
When you execute an INSERT statement, a null value is inserted into any column for which you do not provide a value as well as for all columns that do not have default values associated with them, which are not listed explicitly. You also can use the NULL keyword to indicate that a column should be assigned a null value. The following example inserts values into three columns of the orders table:
In this example, a null value is explicitly entered in the order_date column, and all other columns of the orders table that are not explicitly listed in the INSERT INTO clause are also filled with null values.
Subset of SELECT Statement
You can insert the rows of data that result from a SELECT statement into a table if the insert data is selected from another table or tables.
If this statement has a WHERE clause that does not return rows, sqlca returns SQLNOTFOUND (100) for ANSI-compliant databases. In databases that are not ANSI compliant, sqlca returns (0). When you insert as a part of a multistatement prepare, and no rows are inserted, sqlca returns SQLNOTFOUND (100) for both ANSI databases and databases that are not ANSI compliant. The following SELECT clauses are not supported:
In addition, the FROM clause of the SELECT statement cannot contain the same table name as the table into which you are inserting rows, as shown in the following example:
For detailed information on SELECT statement syntax, see page 1-596.
Using INSERT as a Dynamic Management Statement
You can use the INSERT statement to handle situations where you need to write code that can insert data whose structure is unknown at the time you compile. For more information, refer to the dynamic management section of the INFORMIX-ESQL/C Programmer's Manual manual.
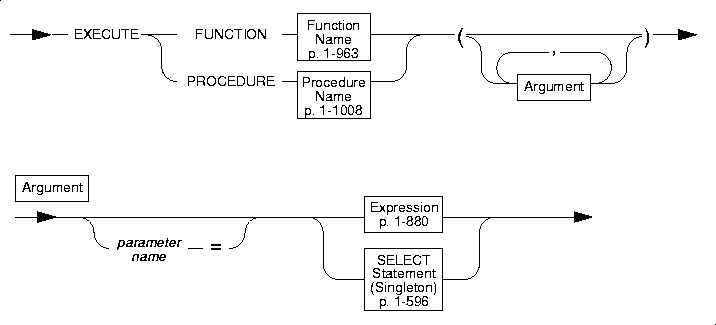
Inserting Data with a User-Defined Routine
You can execute the following types of routines to generate values to be inserted into a column:
Inserting Data With a User-Defined Function
You can specify the EXECUTE FUNCTION statement instead of a VALUES clause in the INSERT statement to insert into a table values that a user-defined function returns. The values that the user-defined function returns must match those expected by the column list in number and data type.
An external function can only return one value. Make sure that you specify only one column in the column list of the INSERT statement. This column must have a compatible data type with the value that the external function returns.The external function can be an iterator function.
An SPL function can return one or more values. Make sure that the number of values that the function returns matches the number of columns in the table or the number of columns that you list in the column list of the INSERT statement. The columns into which you insert the values must have compatible data types with the values that the SPL function returns.
Inserting Data With a Legacy Stored Procedure
Universal Server supports use of the EXECUTE PROCEDURE statement in an INSERT statement to insert the rows of data that result from a call to a legacy stored procedure. The values that the stored procedure returns must match those expected by the column list in number and data type. The number and data types of the columns must match those that the column list expects. Informix recommends that you use the EXECUTE FUNCTION statement to insert data from all new user-defined functions.

Inserting Into a Collection Variable
The INSERT statement with the Collection Derived Table segment allows you to insert elements into a collection variable. The Collection Derived Table segment identifies the collection variable in which to insert the elements. For more information on syntax of the Collection Derived Table segment, see page 1-831.
In an INFORMIX-ESQL/C program, declare a host variable of type collection for a collection variable. This collection variable can be typed or untyped.
In an SPL routine, declare a variable of type COLLECTION, LIST, MULTISET, or SET for a collection variable. This collection variable can be typed or untyped.
To insert new elements, follow these steps:
1. Create a collection variable in your SPL routine or ESQL/C program.
2. Add collection element(s) to the collection variable with the INSERT statement and the Collection Derived Table segment.
3. Once the collection variable contains the correct elements, you then use the INSERT or UPDATE statement on a table or view name to save the collection variable in a collection column (SET, MULTISET, or LIST).
The INSERT statement and the Collection Derived Table segment allow you to perform the following operations on a collection variable:
Use the INSERT statement with the Collection Derived Table segment.
- Insert one or more elements into the collection
Associate the INSERT statement and the Collection Derived Table segment with a cursor to declare a collection cursor for the collection variable.
The INSERT statement and the Collection Derived Table segment allow you to insert one element in a collection. For SET and MULTISET collections, the position of the new element is undefined because the elements of these collections are not ordered. However, LIST collections have elements that are ordered. If the column is the LIST type, you can use the AT clause to specify the position within the list at which you wish to add the new element. For more information, see "AT Clause".
Suppose the ESQL/C host variable a_multiset has the following declaration:
The following INSERT statement adds a new MULTISET element of 142,323 to a_multiset:
When you insert elements into a client collection variable, you cannot specify a SELECT statement or an EXECUTE FUNCTION statement in the VALUES clause of the INSERT. For information on how to use collection host variables in an ESQL/C program, see the INFORMIX-ESQL/C Programmer's Manual.
You can perform a similar insert with an SPL routine, as in the following example:
You can insert into the collection variable a_multiset without using a cursor, because the collection variable contains a MULTISET. The elements of a MULTISET are not listed in a particular order, and the position of the new element that is inserted is undefined. For more information on how to use SPL collection variables, see Chapter 14 in the Informix Guide to SQL: Tutorial.
After you insert a new value into a collection variable, you need to store the new collection in the database. For more information, see "Saving the Collection Variable". You can also use a collection variable as a variable name in the VALUES clause to insert elements into a collection. For more information, see "Inserting Values into Collection Columns".
AT Clause
By default, Universal Server adds a new element at the end of a LIST collection. The AT clause does provide the ability to insert LIST elements at a specified position. If you specify a position that is greater than the number of elements in the list, Universal Server adds the element to the end of the list. You must specify a position value of at least one because the first element in the list is at position 1.
Suppose the ESQL/C host variable a_list has the following declaration:
The following INSERT statement adds a new list element of 9 as the new third element of a_list:
Suppose that before this INSERT, a_list contained the elements {1,8,4,5,2}. After this INSERT, this variable contains the elements {1,8,9,4,5,2}. For more information on how to insert values into ESQL/C collection variables , see the chapter on complex data types in the INFORMIX-ESQL/C Programmer's Manual.
You can perform a similar insert with an SPL routine, as the following example shows:
Suppose that before this INSERT, a_list contained the elements {1,8,4,5,2}. After this INSERT, a_list contains the elements {1,8,9,4,5,2}. The new element 9 has been inserted at position 3 in the list. For more information on how to insert values into SPL collection variables, see Chapter 14 in the Informix Guide to SQL: Tutorial.
After you insert a new value into a collection variable, you need to store the new collection in the database. For more information, see "Saving the Collection Variable".
Saving the Collection Variable
The collection variable stores the elements of the collection. However, it has no intrinsic connection with a database column. Once the collection variable contains the correct elements, you must then save the variable into the collection column with one of the following SQL statements:
 Inserting into a Row Variable
The INSERT statement does not support a row variable in the Collection Derived Table segment. However, you can use the UPDATE statement to insert new field values into a row variable. For example, the following ESQL/C code fragment inserts a new row into the rectangles table (which "Inserting Values into Row-Type Columns" defines): Inserting into a Row Variable
The INSERT statement does not support a row variable in the Collection Derived Table segment. However, you can use the UPDATE statement to insert new field values into a row variable. For example, the following ESQL/C code fragment inserts a new row into the rectangles table (which "Inserting Values into Row-Type Columns" defines):
For more information, see "Updating a Row Variable".
References
See the SELECT statement in this manual. See also the CLOSE, DECLARE, DESCRIBE, EXECUTE, FLUSH, OPEN, PREPARE, and PUT statements in Chapter 1 of this manual for specific information about dynamic management statements. See also the FOREACH statement in Chapter 2 of this manual.
In the Informix Guide to SQL: Tutorial, see the discussion of inserting data in Chapter 4 and Chapter 6. In the Guide to GLS Functionality, see the discussion of the GLS aspects of the INSERT statement.
For information on how to access row and collections with ESQL/C host variables, see the chapter on complex types in the INFORMIX-ESQL/C Programmer's Manual. For information on how to access row and collections with SPL variables, see Chapter 14 in the Informix Guide to SQL: Tutorial.
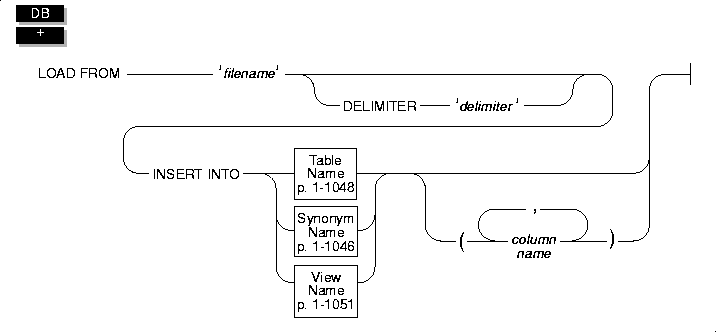
LOAD
Use the LOAD statement to insert data from an operating-system file into an existing table, synonym, or view.
Syntax
Usage
The LOAD statement adds new rows to the table. It does not overwrite existing data. You cannot add a row that has the same key as an existing row.
To use the LOAD statement, you must have Insert privileges for the table where you want to insert data. For information on database-level and table-level privileges, see the GRANT statement on page 1-461.
The LOAD FROM File
The LOAD FROM file contains the data to add to a table. You can use the file that the UNLOAD statement creates as the LOAD FROM file.
If you do not include a list of columns in the INSERT INTO clause, the fields in the file must match the columns that are specified for the table in number, order, and data type.
Each line of the file must have the same number of fields. You must define field lengths that are less than or equal to the length that is specified for the corresponding column. Specify only values that can convert to the data type of the corresponding column. The following table indicates how your Informix product expects you to represent the data types in the LOAD file (when they use the default locale, U.S. English).
If you are using a nondefault locale, the formats of DATE, DATETIME, MONEY, and numeric column values in the LOAD FROM file must be compatible with the formats that the locale supports for these data types. For more information, see the Guide to GLS Functionality.
If you include any of the following special characters as part of the value of a field, you must precede the character with a backslash (\):
Do not use the backslash character (\) as a field delimiter. It serves as an escape character to inform the LOAD statement that the next character is to be interpreted as part of the data.
The following example shows the contents of a hypothetical input file named new_custs:
This data file conveys the following information:
The null values are shown by two delimiter characters with nothing between them.
The following statement loads the values from the new_custs file into the customer table owned by jason:
For more information about the format of the input file, see the discussion of the dbload utility in the Informix Migration Guide.
Loading Character Data
The fields that correspond to character columns can contain more characters than the defined maximum allows for the field. The extra characters are ignored.
If you are loading columns that are the VARCHAR data type, note the following information:
These restrictions on character columns also apply to NCHAR and NVARCHAR columns. For more information on these data types, see the Guide to GLS Functionality.
Loading Simple Large Objects
The database server loads simple large objects (BYTE and TEXT columns) directly from the LOAD FROM file. Keep the following restrictions in mind when you load BYTE and TEXT data:
For TEXT columns, the database server handles any required code-set conversions for the data. For more information, see the Guide to GLS Functionality.
If you are unloading files that contain simple-large-object data types, objects smaller than 10 kilobytes are stored temporarily in memory. You can adjust the 10-kilobyte setting to a larger setting with the DBBLOBBUF environment variable. Simple large objects that are larger than the default or the setting of the DBBLOBBUF environment variable are stored in a temporary file. For additional information about the DBBLOBBUF environment variable, see the Informix Guide to SQL: Reference.
Loading Smart Large Objects
The database server loads smart large objects (BLOB and CLOB columns) from a separate operating-system file on the client computer. It copies all smart-large-object values into a single file. Each BLOB or CLOB value is appended to the current file. The database server might create several files if the values are extremely large or there any many values.
In a LOAD FROM file, a CLOB or BLOB column value appears as follows:
In this format, start_off is the starting offset of the smart-large-object value within the file, end_off is the length of the BLOB or CLOB value, and client_path is the pathname for the client file. For example, to load a CLOB value that is 2048 bytes long and stored at the beginning of the /usr/apps/clob_val file, the database server expects the following value in the LOAD FROM file to appear as follows:
The preceding example assumes a default field delimiter of the vertical bar.
Loading Complex Types
In a LOAD FROM file, complex types appear as follows:
For example, to load the SET values {1, 3, 4} into a column whose data type is SET(INTEGER NOT NULL), the corresponding field of the LOAD FROM file appears as:
For example, to load the ROW values (1, 'abc'), the corresponding field of the LOAD FROM file appears as:
The preceding examples use the default field separator, the vertical bar (|).
Loading Opaque-Type Columns
Some opaque data types require special processing when they are inserted. For example, if an opaque data type contains spatial or multirepresentational data, it might provide a choice of how to store the data: inside the internal structure or, for very large objects, in a smart large object.
This processing is accomplished by calling a user-defined support function called assign(). When you execute the LOAD statement on a table whose rows contains one of these opaque types, the database server automatically invokes the assign() function for the type. The assign() function can make the decision of how to store the data. For more information about the assign() support function, see the Extending INFORMIX-Universal Server: Data Types manual.
DELIMITER Clause
Use the DELIMITER clause to specify the delimiter that separates the data contained in each column in a row in the LOAD FROM file. If you omit this clause, your Informix product checks the DBDELIMITER environment variable.
If the DBDELIMITER environment variable has not been set, the default delimiter is the vertical bar (|). See Chapter 3 in the Informix Guide to SQL: Reference for information about how to set the DBDELIMITER environment variable.
You can specify TAB (CTRL-I) or <blank> (= ASCII 32) as the delimiter symbol. You cannot use the following items as the delimiter symbol:
The following statement identifies the semicolon (;) as the delimiter character:
INSERT INTO Clause
Use the INSERT INTO clause to specify the table, synonym, or view in which to load the new data. (See the discussion of Synonym Name, Table Name, and View Name that begins on page 1-1046 for details.)
You must specify the column names only if one of the following conditions is true:
The following example identifies the price and discount columns as the only columns in which to add data:
References
See the UNLOAD and INSERT statements in this manual.
In the Informix Migration Guide, see the task-oriented discussion of the LOAD statement and other utilities for moving data.
In the Guide to GLS Functionality, see the discussion of the GLS aspects of the LOAD statement.
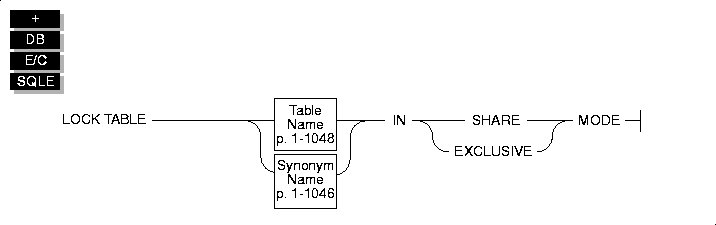
LOCK TABLE
Use the LOCK TABLE statement to control access to a table by other processes.
Syntax
Usage
You can lock a table if you own the table or have the Select privilege on the table or on a column in the table, either from a direct grant or from a grant to PUBLIC. The LOCK TABLE statement fails if the table is already locked in exclusive mode by another process, or if an exclusive lock is attempted while another user has locked the table in share mode.
The SHARE keyword locks a table in shared mode. Shared mode allows other processes read access to the table but denies write access. Other processes cannot update or delete data if a table is locked in shared mode.
The EXCLUSIVE keyword locks a table in exclusive mode. Exclusive mode denies other processes both read and write access to the table.
Exclusive-mode locking automatically occurs when you execute the ALTER INDEX, CREATE INDEX, DROP INDEX, RENAME COLUMN, RENAME TABLE, and ALTER TABLE statements.
Databases with Transactions
If your database was created with transactions, the LOCK TABLE statement succeeds only if it executes within a transaction. You must issue a BEGIN WORK statement before you can execute a LOCK TABLE statement.
Transactions are implicit in an ANSI-compliant database. The LOCK TABLE statement succeeds whenever the specified table is not already locked by another process.
The following guidelines apply to the use of the LOCK TABLE statement within transactions:
The following example shows how to change the locking mode of a table in a database that was created with transaction logging:
Databases Without Transactions
In a database that was created without transactions, table locks set by using the LOCK TABLE statement are released after any of the following occurrences:
To change the lock mode on a table, release the lock with the UNLOCK TABLE statement and then issue a new LOCK TABLE statement.
The following example shows how to change the lock mode of a table in a database that was created without transactions:
References
See the BEGIN WORK, SET ISOLATION, SET LOCK MODE, COMMIT WORK, ROLLBACK WORK, and UNLOCK TABLE statements in this manual.
In the Informix Guide to SQL: Tutorial, see the discussion of locks in Chapter 7.
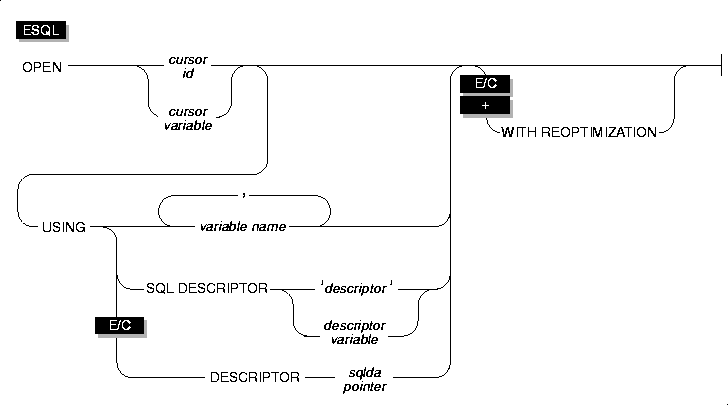
OPEN
Use the OPEN statement to activate a cursor.
Syntax
Usage
The OPEN statement activates the following types of cursors:
You create a cursor with the DECLARE statement (see page 1-303). When the program opens the cursor with OPEN, the associated SELECT, INSERT, or EXECUTE FUNCTION statement is passed to the database server, which begins execution. The specific actions that the database server takes differ, depending on whether the cursor is associated with an INSERT statement (an insert cursor), or with a SELECT statement (a select cursor) or EXECUTE FUNCTION statement (a function cursor). When the program has retrieved or inserted all the rows it needs, close the cursor by using the CLOSE statement.
When you associate the SELECT, INSERT, or EXECUTE FUNCTION statement directly with a cursor (that is, you do not use PREPARE to prepare it before the DECLARE statement), associated with a cursor is by the OPEN statement implicitly prepares the statement. The total number of prepared objects and open cursors that are allowed in one program at any time is limited by the available memory. You can use the FREE statement to free the cursor and release the database server resources.
You receive an error code if you try to open a cursor that is already open.
Opening a Select Cursor
When you open a select cursor (a read-only or an update cursor), the SELECT statement is passed to the database server along with any values that the USING clause of the OPEN statement specifies. (If the statement was previously prepared, the statement passed to the database server when it was prepared.) The database server processes the query to the point of locating or constructing the first row of the active set.
The following example illustrates a simple OPEN statement for a select cursor:
If you are working in a database with explicit transactions, you must open an update cursor within a transaction. This requirement is waived if you declared the cursor using the WITH HOLD keyword. (See the DECLARE statement on page 1-303.)
Because the database server is seeing the query for the first time, it might detect errors in the query. In this case, the database server does not actually return the first row of data, but it sets a return code in the SQLCODE field of the sqlca structure (sqlca.sqlcode).
The SQLCODE value is either negative or zero, as the following table describes.
If the SELECT statement is valid, but no rows match its search criteria, the first FETCH statement returns a value of 100 (SQLNOTFOUND), which means no rows were found.
Opening a Function Cursor
When you open a function cursor, the EXECUTE FUNCTION statement is passed to the database server along with any values that the USING clause of the OPEN statement specifies. The values in the USING clause are passed as arguments to the user-defined function that the EXECUTE FUNCTION executes. This user-defined function must be declared to accept values. (If the statement was previously prepared, the statement was passed to the database server when it was prepared.) The database server executes the user-defined function to the point where it returns the first set of values.
The following example illustrates a simple OPEN statement for a function cursor in INFORMIX-ESQL/C:
In the above example, the database server is seeing the EXECUTE FUNCTION statement for the first time when it executes the OPEN function. Therefore, it might detect syntactic errors in the statement. In this case, the database server does not actually return the first row of data, but it sets a return code in the SQLCODE field of the sqlca structure (sqlca.sqlcode).
The SQLCODE value is either negative or zero, as the following table describes.
If the EXECUTE FUNCTION statement is valid, but the user-defined function returns no rows, the first FETCH statement returns a value of 100 (SQLNOTFOUND), which means no values returned.
Opening an Insert Cursor
When you open an insert cursor, the cursor passes the INSERT statement to the database server, which checks the validity of the keywords and column names. The database server also allocates memory for an insert buffer to hold new data. (See the DECLARE statement on page 1-303.)
An OPEN statement for an insert cursor cannot include a USING clause. The following INFORMIX-ESQL/C example illustrates an OPEN statement with an insert cursor:
When you reopen an insert cursor that is already open, you effectively flush the insert buffer; any rows that are stored in the insert buffer are written into the database table. The database server first closes the cursor, which causes the flush and then reopens the cursor. See the discussion of the PUT statement on page 1-555 for information about checking errors and counting inserted rows.
Opening a Collection Cursor
You can declare both select and insert cursors on collection variables. Such cursors are called collection cursors. You can use the OPEN statement to open these cursors. The OPEN statement allocates resources that the collection cursor needs. (For more information, see the DECLARE statement on page 1-303.)
You can use the name of a collection variable in the USING clause of the OPEN statement. For more information on the USING clause, see page 1-533. For more information on the use of OPEN...USING with a collection variable, see "Fetching From a Collection Cursor" and "Inserting into a Collection Cursor".
USING Clause
The USING clause of the OPEN statement is required when the cursor is associated with a prepared statement that includes question-mark (?) placeholders, as follows:
(See the PREPARE statement on page 1-541.) You can supply values for these parameters in one of the following ways:
Naming Variables in USING
If you know the number of parameters to be supplied at runtime and their data types, you can define the parameters that are needed by the statement as host variables in your program. You pass parameters to the database server by opening the cursor with the USING keyword, followed by the names of the variables. These variables are matched with the SELECT or EXECUTE FUNCTION statement question-mark (?) parameters in a one-to-one correspondence, from left to right.
You must supply one host variable name for each placeholder. The data type of each variable must be compatible with the corresponding value that the prepared statement requires. The following example illustrates the USING clause of the OPEN statement with a SELECT statement in an INFORMIX-ESQL/C code fragment:
The following example illustrates the USING clause of the OPEN statement with an EXECUTE FUNCTION statement in an INFORMIX-ESQL/C code fragment:
You cannot include indicator variables in the list of variable names. To use an indicator variable, you must include the SELECT or EXECUTE FUNCTION statement as part of the DECLARE statement.
USING SQL DESCRIPTOR Clause
If you do not know the number of parameters to be supplied at runtime or their data types, you can associate input values from a system-descriptor area. A system-descriptor area describes the data type and memory location of one or more values.
You can also use an sqlda structure to dynamically supply parameters. However, a system-descriptor area conforms to the X/Open standards.
To specify a system-descriptor area as the location of parameters, use the USING SQL DESCRIPTOR clause of the OPEN statement. This clause allows you to associate input values from a system-descriptor area when you open a cursor.
The following example shows the OPEN...USING SQL DESCRIPTOR statement:
The COUNT field in the system-descriptor area corresponds to the number of dynamic parameters in the prepared statement. The value of COUNT must be less than or equal to the value of the occurrences that were specified when the system-descriptor area was allocated with the ALLOCATE DESCRIPTOR statement. You can obtain the value of a field with the GET DESCRIPTOR statement and set the value with the SET DESCRIPTOR statement.
For further information, refer to the discussion of the system-descriptor area in the INFORMIX-ESQL/C Programmer's Manual.
USING DESCRIPTOR Clause
If you do not know the number of parameters to be supplied at runtime or their data types, you can associate input values from an sqlda structure. An sqlda structure lists the data type and memory location of one or more values to replace question-mark (?) placeholders. To specify an sqlda structure as the location of parameters, use the USING DESCRIPTOR clause of the OPEN statement. This clause allows you to associate input values from an sqlda structure when you open a cursor.
The following example shows the OPEN...USING DESCRIPTOR statement in INFORMIX-ESQL/C:
The sqld value specifies the number of input values that are described in occurrences of sqlvar. This number must correspond to the number of dynamic parameters in the prepared statement.
For further information, refer to the sqlda discussion in the INFORMIX-ESQL/C Programmer's Manual.
WITH REOPTIMIZATION Clause
The WITH REOPTIMIZATION clause allows you to reoptimize your query-design plan. When you prepare a SELECT statement or an EXECUTE FUNCTION statement, Universal Server uses a query-design plan to optimize that query. If you later modify the data that is associated with a prepared SELECT statement or the data that is associated with an EXECUTE FUNCTION statement, you can compromise the effectiveness of the query-design plan for that statement. In other words, if you change the data, you can deoptimize your query. To ensure optimization of your query, you can prepare the SELECT or EXECUTE FUNCTION statement again or open the cursor again using the WITH REOPTIMIZATION clause.
Informix recommends that you use the WITH REOPTIMIZATION clause because it provides the following advantages over preparing a statement again:
The WITH REOPTIMIZATION clause also makes your database server optimize your query-design plan before processing the OPEN cursor statement. The following example shows the WITH REOPTIMIZATION clause in INFORMIX-ESQL/C:
Reopening a Cursor
The database server evaluates the values that are named in the USING clause of the OPEN statement only when it opens the select or function cursor. While the cursor is open, subsequent changes to program variables in the USING clause do not change the active set of the cursor.
A subsequent OPEN statement closes the cursor and then reopens it. When the database server reopens the cursor, it creates a new active set that is based on the current values of the variables in the USING clause. If the program variables have changed since the previous OPEN statement, reopening the cursor can generate an entirely different active set.
Even if the values of the variables are unchanged, the values in the active set can be different, in the following situations:
The database server can process most queries dynamically. For these queries, the database server does not pre-fetch all rows when it opens the select or function cursor. Therefore, if other users are modifying the table at the same time that the cursor is being processed, the active set might reflect the results of these actions.
However, for some queries, the database server evaluates the entire active set when it opens the cursor. These queries include those with the following features:
For these queries, any changes that other users make to the table while the cursor is being processed are not reflected in the active set.
Relationship Between OPEN and FREE
The database server allocates resources to prepared statements and open cursors. If you release resources with a FREE cursor id or FREE cursor variable statement, you cannot use the cursor unless you declare the cursor again. If you execute a FREE statement id or FREE statement id variable statement, you cannot open the cursor that is associated with the statement id or statement id variable unless you prepare the statement id or statement id variable again.
References
See the CLOSE, DECLARE and FREE statements in this manual for general information about cursors. See the PUT and FLUSH statements in this manual for information about insert cursors. See the FETCH statement in this manual for information about select and function cursors.
See the ALLOCATE DESCRIPTOR, DEALLOCATE DESCRIPTOR, DESCRIBE, EXECUTE, FETCH, GET DESCRIPTOR, PREPARE, PUT, and SET DESCRIPTOR statements in this manual for more information about dynamic SQL statements.
In the Informix Guide to SQL: Tutorial, see the discussion of the OPEN statement in Chapter 5. Refer also to the INFORMIX-ESQL/C Programmer's Manual for more information about the system-descriptor area and the sqlda structure.
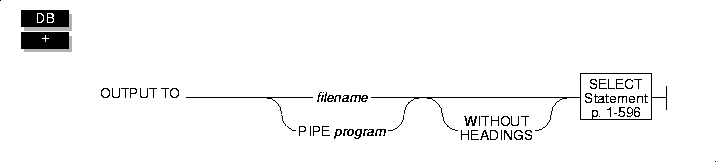
OUTPUT
Use the OUTPUT statement to send query results directly to an operating-system file or to pipe it to another program.
Syntax
Usage
You can send the results of a query to an operating-system file by specifying the full pathname for the file. If the file already exists, the output overwrites the current contents, as the following example shows:
You can display the results of a query without column headings by using the WITHOUT HEADINGS keywords, as the following example shows:
You also can use the keyword PIPE to send the query results to another program, as the following example shows:
References
See the SELECT and UNLOAD statements in this manual.
|