This section provides general information about the structure of B-tree index pages. It is designed as an overview for the interested reader. For more information on B-tree indexes, see your IBM Informix Performance Guide.
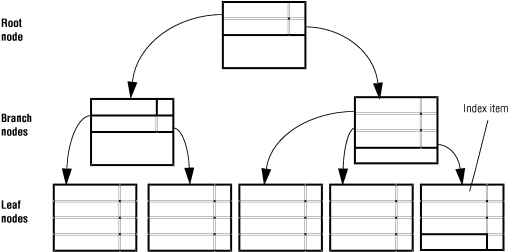
The database server uses a B-tree structure to organize index information. Figure 14 shows that a fully developed B-tree index is composed of the following three different types of index pages or nodes:
A branch node contains pointers to leaf nodes or other branch nodes.
A leaf node contains index items and horizontal pointers to other leaf nodes.
Each node serves a different function. The following sections describe each node and the role that it plays in indexing.
The fundamental unit of an index is the index item. An index item contains a key value that represents the value of the indexed column for a particular row. An index item also contains rowid information that the database server uses to locate the row in a data page.
A node is an index page that stores a group of index items. For the three types of nodes, see Definition of B-Tree Terms.
This section presents an overview of how the database server creates and fills an index.
When you create an index for an empty table, the database server allocates a single index page. This page represents the root node and remains empty until you insert data in the table.
At first, the root node functions in the same way as a leaf node. For each row that you insert into the table, the database server creates and inserts an index item in the root node. Figure 15 illustrates how a root node appears before it fills.

When the root node becomes full of index items, the database server splits the root node by performing the following steps:
As you add new rows to a table, the database server adds index items to the leaf nodes. When a leaf node fills, the database server creates a new leaf node, moves part of the contents of the full index node to the new node, and adds a node pointer to the new leaf node in the root node.
For example, suppose that leaf node 3 in Figure 16 becomes full. When this situation occurs, the database server adds yet another leaf node. The database server moves part of the records from leaf node 3 to the new leaf node, as Figure 16 shows.

Eventually, as you add rows to the table, the database server fills the root node with node pointers to all the existing leaf nodes. When the database server splits yet another leaf node, and the root node has no room for an additional node pointer, the following process occurs.
The database server splits the root node and divides its contents among two newly created branch nodes. As index items are added, more and more leaf nodes are split, causing the database server to add more branch nodes. Eventually, the root node fills with pointers to these branch nodes. When this situation occurs, the database server splits the root node again. The database server then creates yet another branch level between the root node and the lower branch level. This process results in a four-level tree, with one root node, two branch levels, and one leaf level. The B-tree structure can continue to grow in this way to a maximum of 20 levels.
Branch nodes can point either to other branch nodes below them (for large indexes of four levels or more) or to leaf nodes. In Figure 17, the branch node points to leaf nodes only. The first item in the left branch node contains the same key value as the largest item in the leftmost leaf node and a node pointer to it. The second item contains the largest item in the next leaf node and a node pointer to it. The third item in the branch node contains only a pointer to the next higher leaf node. Depending on the index growth, this third item can contain the actual key value in addition to the pointer at a later point during the lifespan of the index.

Duplicate key values occur when the value of an indexed column is identical for multiple rows. For example, suppose that the third and fourth leaf nodes of a B-tree structure contain the key value Smith. Suppose further that this value is duplicated six times, as Figure 18 illustrates.

The first item on the third leaf page contains the duplicate key value, Smith, and the rowid information for the first physical row in the table that contains the duplicate key value. To conserve space, the second item does not repeat the key value Smith but instead contains just the rowid information. This process continues throughout the page; no other key values are on the leaf, only rowid information.
The first item on the fourth leaf page again contains the duplicated key value and rowid information. Subsequent items contain only rowid information.
Now consider the branch node. The third item in the branch node contains the same key value and rowid as the largest item in the third leaf node and a node pointer to it. The fourth item would contain only a node pointer to the fourth leaf node, thus saving the space of an additional duplicate key value.
To increase concurrency, the database server supports key-value locking in the B-tree index. Key-value locking locks only the value of the key instead of the physical location in the B-tree index.
One of the most important uses for key-value locking is to assure that a unique key remains unique through the end of the transaction that deleted it. Without this protection mechanism, user A might delete a unique key within a transaction, and user B might insert a row with the same key before the transaction commits. This scenario makes rollback by user A impossible. Key-value locking prevents user B from inserting the row until the end of user A's transaction.
With Repeatable Read isolation level, the database server is required to protect the read set. The read set consists of the rows that meet the filters in the WHERE clause of the query. To guarantee that the rows do not change, the database server obtains a lock on the index item that is adjacent to the right-most item of the read set.
When the database server physically removes an index item from a node and frees an index page, the freed page is reused.
When you create an index, you can specify how densely or sparsely filled you want the index. The index fill factor is a percentage of each index page that will be filled during the index build. Use the FILLFACTOR option of the CREATE INDEX statement or the FILLFACTOR configuration parameter to set the fill factor. This option is particularly useful for indexes that you do not expect to grow after they are built. For additional information about the FILLFACTOR option of the CREATE INDEX statement, see the IBM Informix Guide to SQL: Syntax.
For data types other than VARCHAR, the length of an index item is calculated by adding the length of the key value plus 5 bytes for each rowid information associated with the key value.
The key values in an index are typically of fixed length. If an index holds the value of one or more columns of the VARCHAR data type, the length of the key value is at least the sum of the length-plus-one of each VARCHAR value in the key.
In Dynamic Server, the maximum length of a key value is 390 bytes. The combined size of VARCHAR columns that make up a key must be less than 390, minus an additional byte for each VARCHAR column. For example, the key length of the index that the database server builds for the following statements equals 390, or ((255+1) + (133+1)):
CREATE TABLE T1 (c1 varchar(255, 10), c2 varchar(133, 10)); CREATE INDEX I1 on T1(c1, c2);
A functional index is one in which all keys derive from the results of a function. If you have a column of pictures, for example, and a function to identify the predominant color, you can create an index on the result of the function. Such an index would enable you to quickly retrieve all pictures having the same predominant color, without re-executing the function.
A functional index uses the same B-tree structure as any other B-tree index. The only difference is that the determining function is applied during an insert or an update whenever the column that is the argument to the function changes. For more information on the nature of functional indexes, refer to your IBM Informix Performance Guide.
To create a functional index, use the CREATE FUNCTION and CREATE INDEX statements. For more information on these statements, refer to the IBM Informix Guide to SQL: Syntax.
Home | [ Top of Page | Previous Page | Next Page | Contents | Index ]