Home |
Previous Page | Next Page Data Manipulation > Using Complex Data Types > Row Types >
The database server supports the following
kinds of row types.
- Row Type
- Description
- Named row type
- A named row type is identified by its name. With the CREATE
ROW TYPE statement, you create a template of a row type. You can
then use this template to take the following actions:
- Use type inheritance
- Define columns that all have the same row type
- Assign a named
row type to a table with the OF TYPE clause of the CREATE TABLE
statement
- Unnamed row type
- An unnamed row type is identified by its structure. With the
ROW keyword, you create a row type. This row type contains fields
but has no user-defined name. Therefore, if you want a second column
to have the same row type, you must specify all fields.
All row types use the same internal format to store their values.
For more information, see the IBM Informix: Guide to SQL Reference.
Tip:
The internal format of a row type is often referred to
as its binary representation.
The DataBlade API supports the SQL row types
with the following data type structures:
- A row descriptor (MI_ROW_DESC)
provides information about the row type.
- A row structure (MI_ROW)
holds the binary representation of the field values in the row type.
Important:
The fields of a row type are comparable to the columns
in the row of a table. This similarity means that you use the same DataBlade API data type
structures to access row types that you do to access columns in
a row.
Using
a Row Descriptor
A row descriptor, MI_ROW_DESC,
is a DataBlade API structure that describes the type of data in each field
of a row type. The following table summarizes the memory operations
for a row descriptor.
| Memory Duration |
Memory Operation |
Function Name |
| Current memory duration |
Constructor |
mi_row_desc_create( ) |
| Destructor |
mi_row_desc_free( ) |
Tip:
A row descriptor can describe a row type or a row in a
table. Therefore, you use the same DataBlade API functions to handle memory
operations for a row descriptor when it describes a row type or
a table row.
Server Only
In a C UDR, the row structure and row descriptor are part
of the same data type structure. The row structure is just a data
buffer in the row descriptor that holds the column values of a row.
A one-to-one correspondence exists between the row descriptor (which mi_row_desc_create( ) allocates)
and its row structure (which mi_row_create( ) allocates).
Therefore:
- When the mi_row_desc_create( ) function
creates a new row descriptor, it assigns a NULL-valued
pointer to the data buffer.
- The mi_row_desc_free( ) function
frees both the row descriptor and its associated row
structure.
End of Server Only
Client Only
In a client LIBMI application, a row
structure and a row descriptor are separate data type structures.
A one-to-many correspondence can exist between a row descriptor and
its associated row structures. When you call mi_row_desc_free( ),
you free only the specified row descriptor.
End of Client Only
Table 22 lists
the DataBlade API accessor functions that obtain information about fields
of a row type (or columns of a row) from the row descriptor.
Table 22. Field and Column Information in the Row Descriptor
| Column Information |
DataBlade API
Accessor Functions |
| The number of
columns and/or fields in the row descriptor |
mi_column_count( ) |
| The name of the
column or field, given its position in the row |
mi_column_name( ) |
| The column identifier,
which is the position of the column or field within the row, given
its name |
mi_column_id( ) |
| The precision (total
number of digits) of a column or field data type |
mi_column_precision( ) |
| The scale of a
column or field data type |
mi_column_scale( ) |
| Whether a column or field in the
row descriptor has the NOT NULL constraint |
mi_column_nullable( ) |
| The type identifier of
the column or field data type |
mi_column_type_id( ) |
| The type descriptor of
the column or field data type |
mi_column_typedesc( ) |
Important:
To DataBlade API modules, the row descriptor (MI_row_DESC)
is an opaque C data structure. Do not access its internal fields
directly. The internal structure of MI_ROW_DESC may
change in future releases. Therefore, to create portable code, always
use the accessor functions for this structure to obtain column information.
The row descriptor stores column information in several parallel
arrays.
| Column Array |
Contents |
| Column-type ID array |
Each element is a pointer to
a type identifier (MI_TYPEID) that indicates the data type of the
column. |
| Column-type-descriptor array |
Each element is a pointer to
a type descriptor (MI_TYPE_DESC) that describes the data type of
the column. |
| Column-scale array |
Each element is the scale of the column
data type. |
| Column-precision array |
Each element is the precision of the
column data type. |
| Column-nullable array |
Each element has either of the following values:
- MI_TRUE: The column can contain SQL NULL values.
- MI_FALSE: The column cannot contain SQL NULL values.
|
All
of the column arrays in the row descriptor have zero-based indexes.
Within the row descriptor, each column has a column identifier,
which is a zero-based position of the column (or field) in the column
arrays. When you need information about a column (or field), specify
its column identifier to one of the row-descriptor accessor functions
in Table 22.
Tip:
The
system catalog tables refer to the unique number that identifies
a column definition as its "column identifier." However,
the DataBlade
API refers to this number as a "column number" and
the position of a column within the row structure as a "column
identifier." These two terms do not refer to the same value.
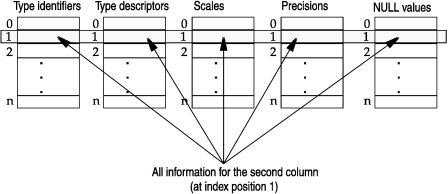
Figure 23 shows how the information
at index position 1 of these arrays holds the column information for the second
column in a row descriptor.
Figure 23. Column Arrays in the Row Descriptor
To access information for the nth column,
provide an index value of n-1 to the appropriate
accessor function in Table 22. The
following calls to the mi_column_type_id( ) and mi_column_nullable( ) functions
obtain from a row descriptor that row_desc identifies
the type identifier (col_type) and whether
the column is nullable (col_nullable) for
the second column:
MI_ROW_DESC *row_desc;
MI_TYPEID *col_type;
mi_integer col_nullable;
...
col_type = mi_column_type_id(row_desc, 1);
col_nullable = mi_column_nullable(row_desc, 1);
To obtain
the number of columns in the row descriptor (which is also the number
of elements in the column arrays), use the mi_column_count( ) function.
Using
a Row Structure
The DataBlade API always
holds fields of a row type in a row structure (MI_ROW structure).
Each row structure stores the data from a single row-type column
in a table. The following table summarizes the memory operations
for a row structure.
| Memory Duration |
Memory Operation |
Function Name |
| Current memory duration |
Constructor |
mi_row_create( ),
mi_streamread_row( ) |
| Destructor |
mi_row_free( ) |
Tip:
A row structure can hold values for the fields of a row
type or the columns of a row in a table. Use the same DataBlade API functions
to handle memory operations for a row structure when it holds values
for a row type or a table row.
Server Only
In a C UDR, the row structure and row descriptor are part
of the same data type structure. The mi_row_create( ) function
just adds a data buffer, which holds the column values of a row,
to the row descriptor. A one-to-one correspondence exists between
the row descriptor (which mi_row_desc_create( ) allocates)
and its row structure (which mi_row_create( ) allocates).
If you call mi_row_create( ) twice
with the same row descriptor, the second call overwrites the row
values of the first call.
The mi_row_free( ) function frees
the memory associated with the data buffer and assigns a NULL-valued
pointer to this buffer in the row descriptor.
End of Server Only
Client Only
In a client LIBMI application, a row
structure and a row descriptor are separate data type structures.
A one-to-many correspondence exists between a row descriptor and its
associated row structures. When you call mi_row_create( ) a
second time with the same row descriptor, you obtain a second row
structure. The mi_row_free( ) function frees
a row structure.
End of Client Only
The
following DataBlade API functions obtain field values from an existing
row structure.
| DataBlade API Function |
Description |
mi_value( ),
mi_value_by_name( ) |
Returns
a row structure as a column value when the function returns an MI_ROW_VALUE
value status
The row structure holds the
fields of the row type. |
Tip:
A row structure can hold the fields of a row type or the
columns of a database row. You use the same DataBlade
API functions to
handle memory operations for a row structure when it holds row-type
fields as when it describes columns of a row. For more information
on how to obtain column values from a row, see
Obtaining Column Values.