The hierarchical structure of an R-tree index is similar to that of a B-tree index, although the data stored in the index is quite different.
The R-tree access method organizes data in a tree-shaped structure called an R-tree index. The index uses a bounding box, which is a rectilinear shape that completely contains the bounded object or objects. Bounding boxes can enclose data objects or other bounding boxes.
Bounding boxes are usually stored as a set of coordinates of equal dimension as the bounded object. While it is useful for performance reasons to choose the bounding box that is as small as possible, the R-tree access method does not require it. The minimum bounding box is often, however, the most efficient one. For example, the minimum bounding box for a two-dimensional circle is a square whose side is equal to the diameter of the circle. The minimum bounding box for a three-dimensional sphere is a cube whose edge is equal to the diameter of the sphere.
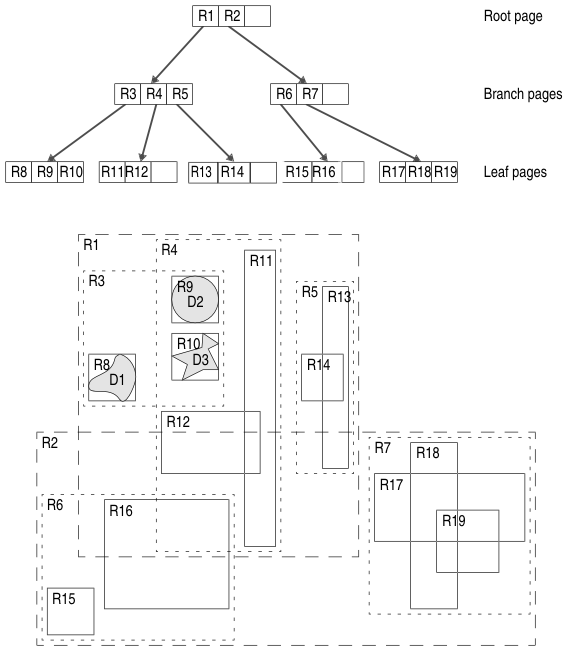
The lower part of Figure 1 shows a set of bounding boxes that enclose data objects and other bounding boxes. In the diagram, the data objects are shaded.
As the figure shows, bounding boxes can enclose a single data object or one or more bounding boxes. For example, bounding box R8, which is at the leaf level of the tree, contains the data object D1. Bounding box R3, which is at the branch level of the tree, contains the bounding boxes R8, R9, and R10. Bounding box R1, which is at the root level, contains the bounding boxes R3, R4, and R5.
The R-tree access method evaluates the index entries (data objects and bounding boxes) as opaque objects (strings of bytes). The R-tree access method uses the support and strategy functions to interpret these objects.
For R-tree indexes created with Version 9.21 or later of the database server, if the datablade module you are working with is appropriately set up, default R-tree indexes no longer store a copy of the data object in leaf pages. Instead, the leaf pages store bounding box representations of the data object. This type of R-tree index is called a bounding-box-only R-tree index.
The advantages of bounding-box-only R-tree indexes are the following:
You might want to override this behavior if your table contains other large columns in addition to the column being indexed with the R-tree index. For more information about the BOUNDING_BOX_INDEX index parameter, see R-Tree Index Parameters.
Functional R-tree indexes are not bounding-box-only indexes; they store the data objects themselves in leaf pages.
R-tree indexes built in Version 9.20 of the database server continue to work correctly in Version 9.21. If, however, you build a new bounding-box-only R-tree index in Version 9.21 of the database server, this index will not work correctly if you revert to Version 9.20 of the database server.
An R-tree index is arranged as a hierarchy of pages. The topmost level of the hierarchy is the root page. Intermediate levels, when needed, are branch pages. Each branch page contains entries that refer to a subset of pages, or a subtree, in the next level of the index. The bottom level of the index contains a set of leaf pages. Each leaf page contains a list of index entries that refer back to rows in the indexed table. Each index entry also includes a copy of the bounding-box of the indexed key from the table, or data object. The pages of an R-tree index do not usually contain the maximum possible number of index entries.
An R-tree index is height-balanced, which means that all paths down the tree, from the root page to any leaf page, traverse the same number of levels. This also means that all leaf nodes are at the same level.
Each page in an R-tree index structure is a physical disk page. The R-tree index is designed to minimize the number of pages that need to be fetched from disk during the execution of a query, since disk I/O is often the most costly part.
The upper section of Figure 1 shows how the data objects and the bounding boxes (described in Bounding Boxes) stored in an R-tree index structure are related. The root page contains entries for bounding boxes R1 and R2. Together, these two bounding boxes enclose all the objects in the index.
The bounding boxes of an index page can overlap. However, a data object appears only once in the index even if it falls inside more than one bounding box at the branch levels. For example, data object D2 appears only once in the index that Figure 1 shows, even though it falls inside bounding boxes R9, R3, R4, and R1.
The reason data objects appear only once in an R-tree index is to keep the index small. If each object had to be replicated in several index pages, the size of the R-tree index would be larger than it needs to be.
An index entry in a leaf page consists of:
The size of an index entry in a leaf page is the size of the data object plus 20 bytes.
An index entry in a root or branch page consists of:
The size of an index entry in a root or branch page is the size of the bounding box plus 12 bytes.
Each type of page in an R-tree index (leaf, branch, or root) also has an overhead of 20 bytes plus the size of the overall bounding box of the page.
The number of levels needed to support an R-tree index depends on the number of index entries each index page can hold. The number of entries per index page depends, in turn, on the size of the key value. The number of entries per page determines the branching factor of the tree. More entries per page, or a higher branching factor, means that fewer levels are needed for the same number of leaf pages as well as fewer leaf pages for a given number of base table keys. For any reasonable branching factor, almost all the space that an R-tree index needs is used by leaf pages.
The next sections describe a search and an update of an R-tree index that results from a search or update of the indexed table.
Home | [ Top of Page | Previous Page | Next Page | Contents | Index ]