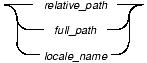| Informix Guide to GLS Functionality Introduction |
|
This section describes the conventions that this manual uses. These conventions make it easier to gather information from this and other volumes in the documentation set.
The following conventions are discussed:
This manual uses the following conventions to introduce new terms, illustrate screen displays, describe command syntax, and so forth.
 Tip: When you are instructed to "enter" characters or to "execute" a command, immediately press RETURN after the entry. When you are instructed to "type" the text or to "press" other keys, no RETURN is required.
Tip: When you are instructed to "enter" characters or to "execute" a command, immediately press RETURN after the entry. When you are instructed to "type" the text or to "press" other keys, no RETURN is required.
Icon Conventions
Throughout the documentation, you will find text that is identified by several different types of icons. This section describes these icons.
Comment icons identify three types of information, as the following table describes. This information always appears in italics.
Feature, product, and platform icons identify paragraphs that contain feature-specific, product-specific, or platform-specific information.
These icons can apply to an entire section or to one or more paragraphs within a section. If an icon appears next to a section heading, the information that applies to the indicated feature, product, or platform ends at the next heading at the same or higher level. A  symbol indicates the end of feature-, product-, or platform-specific information that appears within one or more paragraphs within a section.
symbol indicates the end of feature-, product-, or platform-specific information that appears within one or more paragraphs within a section.
Compliance icons indicate paragraphs that provide guidelines for complying with a standard.
| Icon | Description |
|---|---|
|
| Identifies information that is specific to an ANSI-compliant database |
|
| Identifies information that is an Informix extension to ANSI SQL-92 entry-level standard SQL |
These icons can apply to an entire section or to one or more paragraphs within a section. If an icon appears next to a section heading, the information that applies to the indicated feature, product, or platform ends at the next heading at the same or higher level. A symbol indicates the end of feature-, product-, or platform-specific information that appears within one or more paragraphs within a section.
This section describes conventions for syntax diagrams. Each diagram displays the sequences of required and optional keywords, terms, and symbols that are valid in a given statement or segment, as Figure 1 shows.
Each syntax diagram begins at the upper-left corner and ends at the upper-right corner with a vertical terminator. Between these points, any path that does not stop or reverse direction describes a possible form of the statement.
Syntax elements in a path represent terms, keywords, symbols, and segments that can appear in your statement. The path always approaches elements from the left and continues to the right, except in the case of separators in loops. For separators in loops, the path approaches counterclockwise. Unless otherwise noted, at least one blank character separates syntax elements.
You might encounter one or more of the following elements on a path.
Figure 2 shows a syntax diagram that uses most of the path elements that the previous table lists.
To use this diagram to construct a statement, start at the top left with the keyword DELETE FROM. Then follow the diagram to the right, proceeding through the options that you want.
Figure 2 illustrates the following steps:
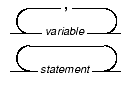
This section defines and illustrates the format of commands that are available in Informix products. These commands have their own conventions, which might include alternative forms of a command, required and optional parts of the command, and so forth.
Each diagram displays the sequences of required and optional elements that are valid in a command. A diagram begins at the upper-left corner with a command. It ends at the upper-right corner with a vertical line. Between these points, you can trace any path that does not stop or back up. Each path describes a valid form of the command. You must supply a value for words that are in italics.
You might encounter one or more of the following elements on a command-line path.
Figure 3 shows a command-line diagram that uses some of the elements that are listed in the previous table.
To construct a command correctly, start at the top left with the command. Follow the diagram to the right, including the elements that you want. The elements in the diagram are case sensitive.
Figure 3 illustrates the following steps:
Examples of SQL code occur throughout this manual. Except where noted, the code is not specific to any single Informix application development tool. If only SQL statements are listed in the example, they are not delimited by semicolons. For instance, you might see the code in the following example:
To use this SQL code for a specific product, you must apply the syntax rules for that product. For example, if you are using DB-Access, you must delimit multiple statements with semicolons. If you are using an SQL API, you must use EXEC SQL at the start of each statement and a semicolon (or other appropriate delimiter) at the end of the statement.
Tip: Ellipsis points in a code example indicate that more code would be added in a full application, but it is not necessary to show it to describe the concept being discussed.
For detailed directions on using SQL statements for a particular application development tool or SQL API, see the manual for your product.
Throughout this manual, examples show how single-byte and multibyte characters appear. Because multibyte characters are usually ideographic (such as Japanese or Chinese characters), this manual does not use the actual multibyte characters. Instead, it uses ASCII characters to represent both single-byte and multibyte characters. This section provides general information about how this manual represents multibyte and single-byte characters abstractly.
This manual represents single-byte characters as a series of lowercase letters. The format for representing one single-byte character abstractly is:
In this format, a stands for any single-byte character, not for the letter "a" itself.
The format for representing a string of single-byte characters is as follows:
In this format, a stands for the first character in the string, and z stands for the last character in the string. For example, if the string Ludwig consists of single-byte characters, the following format represents this 6-character string abstractly:
 Tip: The letter "s" does not appear in alphabetical sequences that represent strings of single-byte characters. The manual reserves the letter "s" as a symbol that represents a single-byte white-space character. For further information, see White Space in Strings.
Tip: The letter "s" does not appear in alphabetical sequences that represent strings of single-byte characters. The manual reserves the letter "s" as a symbol that represents a single-byte white-space character. For further information, see White Space in Strings.
Multibyte Characters
This manual does not attempt to show the actual appearance of multibyte characters in text, examples, or diagrams. Instead, the following convention shows abstractly how multibyte characters are stored:
One to four identical uppercase letters, each followed by a different superscript number, represent one multibyte character. The superscripts show the first to the nth byte of the multibyte character, where n has values between two and four. For example, the following symbols represent a multibyte character that consists of two bytes:
The following notation represents a multibyte character that consists of four bytes (the maximum length of a multibyte character):
The following example shows a string of multibyte characters in an SQL statement:
This statement creates a database whose name consists of five multibyte characters, each of which is two bytes long. For more information on how to use multibyte characters in SQL identifiers, see Naming Database Objects.
If you are using a multibyte code set, a given string might be composed of both single-byte and multibyte characters. To represent these mixed strings, this manual simply combines the formats for multibyte and single-byte characters.
For example, suppose that you have a string with four characters. The first and fourth characters are single-byte characters, and the second and third characters are multibyte characters that consist of two bytes each. The following format represents this string:
White space is a series of one or more space characters. A GLS locale defines what characters are considered to be space characters. For example, both the TAB and blank might be defined as space characters in one locale, but certain combinations of the CTRL key and another character might be defined as space characters in a different locale.
The convention for representing single-byte white spaces in this manual is the letter "s." The following notation represents one single-byte white space:
In the ASCII code set, an example of a single-byte white space is the blank character (ASCII code number 32). To represent a string that consists of two ASCII blank characters, the manual uses the following notation:
The following notation represents a multibyte white-space character:
In this format, s1 represents the first byte of the white-space character, and sn represents the last byte of the white-space character, where n has values between two and four. For example, the following notation represents one 4-byte white-space character:
Combinations of characters and white spaces can occur in quoted strings, in CHAR columns that contain fewer characters than the defined length of the column, and in other situations. For example, if a CHAR(5) column in a single-byte code set contains a string of three characters, the string is extended with two white spaces so that its length is equal to the defined length of the column, as follows:
The following example shows the representation for a string of five characters (three characters of data and two trailing white spaces) in a multibyte code set where each of the characters and white-space characters consists of two bytes:
Sometimes a string can contain both single-byte and multibyte white-space characters. In the following example, the string is composed of these elements: three single-byte characters (abc), a single-byte white-space character (s), a multibyte white-space character (s1s2), two single-byte white-space characters (ss), and one multibyte white-space character (s1s2):