| Informix Guide to SQL: Syntax SQL Statements |
|
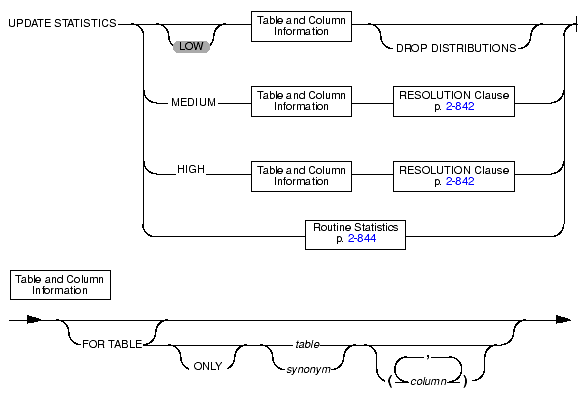
Use the UPDATE STATISTICS statement to:
|
You cannot update the statistics used by the optimizer for a table or UDR that is external to the current database. That is, you cannot update statistics on remote database objects.
If you do not specify any clause that begins with the FOR keyword, statistics are updated for every table and SPL routine in the current database, including the system catalog tables. Similarly, if you use a clause that begins with the FOR keyword, but do not specify a table or SPL routine name, the database server updates the statistics for all tables, including temporary tables, or all SPL routines in the current database.
If you use the FOR TABLE clause without a specific table name to build distributions on all of the tables in the database, distributions will also be built on all of the temporary tables in your session.
Although a change to the database might obsolete the corresponding statistics in the systables, syscolumns, sysindexes, and sysdistrib system catalog tables, the database server does not automatically update them.
Issue an UPDATE STATISTICS statement in the following situations to ensure that the stored distribution information reflects the state of the database:
If your application makes many modifications to the data in a particular table, update the system catalog table data for that table routinely with the UPDATE STATISTICS statement to improve query efficiency. The term many modifications is relative to the resolution of the distributions. If the data changes do not change the distribution of column values, you do not need to execute UPDATE STATISTICS.
![]() In Enterprise Decision Server, the UPDATE STATISTICS statement does not update, maintain, or collect statistics on indexes. The statement does not update the syscolumns and sysindexes tables. Any information about indexes, the syscolumns, and the sysindexes tables in the following pages does not apply to Enterprise Decision Server.
In Enterprise Decision Server, the UPDATE STATISTICS statement does not update, maintain, or collect statistics on indexes. The statement does not update the syscolumns and sysindexes tables. Any information about indexes, the syscolumns, and the sysindexes tables in the following pages does not apply to Enterprise Decision Server. 
Use the ONLY keyword to collect data for one table in a hierarchy of typed tables. If you do not specify the ONLY keyword and the table that you specify has subtables, the database server creates distributions for that table and every table under it in the hierarchy.
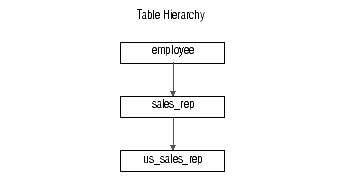
For example, assume your database has the typed table hierarchy that appears in Figure 2-2, which shows a supertable named employee that has a subtable named sales_rep. The sales_rep table, in turn, has a subtable named us_sales_rep.
When the following statement executes, the database server generates statistics on both the sales_rep and us_sales_rep tables:
In contrast, the following example generates statistical data for each column in table sales_rep but does not act on tables employee or us_sales_rep:
Because neither of the previous examples mentioned the level at which to update the statistical data, the database server uses the low mode by default.
In Dynamic Server, when you execute the UPDATE STATISTICS statement in any mode, the database server reads through index pages to:
If pages are found with the delete flag marked as 1, the corresponding keys are removed from the B-tree cleaner list.
This operation is particularly useful if a system crash causes the B-tree cleaner list (which exists in shared memory) to be lost. To remove the B-tree items that have been marked as deleted but are not yet removed from the B-tree, run the UPDATE STATISTICS statement. For information on the B-tree cleaner list, see your Administrator's Guide.
Use the LOW mode option to generate and update statistical data regarding table, row, and page count statistics in the systables system catalog table.
If you do not specify a mode, the database server uses low by default.
![]() In Dynamic Server, the LOW mode option updates index and column statistics for specified columns also. The database server generates and updates this statistical data in the syscolumns, and sysindexes tables.
In Dynamic Server, the LOW mode option updates index and column statistics for specified columns also. The database server generates and updates this statistical data in the syscolumns, and sysindexes tables.
When you use the low mode, the database server generates the least amount of information about the column. If you want the UPDATE STATISTICS statement to do minimal work, specify a column that is not part of an index.
The following example updates statistics on the customer_num column of the customer table.
Because the low mode does not update data in the sysdistrib system catalog table, all distributions associated with the customer table remain intact, even those that already exist on the customer_num column.
Use the DROP DISTRIBUTIONS option to force the removal of distribution information from the sysdistrib system catalog table.
When you specify the DROP DISTRIBUTIONS option, the database server removes the distribution data that exists for the column or columns you specify. If you do not specify any columns, the database server removes all the distribution data for that table.
You must have the DBA privilege or be the owner of the table to use this option.
The following example shows how to remove distributions for the customer_num column in the customer table:
As the example shows, you drop the distribution data at the same time you update the statistical data that the low mode option generates.
Use the MEDIUM mode option to update the same statistics that you can perform with the low mode and also generate statistics about the distribution of data values for each specified column. The database server places distribution information in the sysdistrib system catalog table
If you use the MEDIUM mode option, the database server scans tables at least once and takes longer to execute on a given table than the LOW mode option.
The constructed distribution is statistically significant. When you use the MEDIUM mode option, the data for the distributions is obtained by sampling a percentage of data rows. Because the data obtained by sampling is usually much smaller than the actual number of rows, this mode executes more quickly than the HIGH mode.
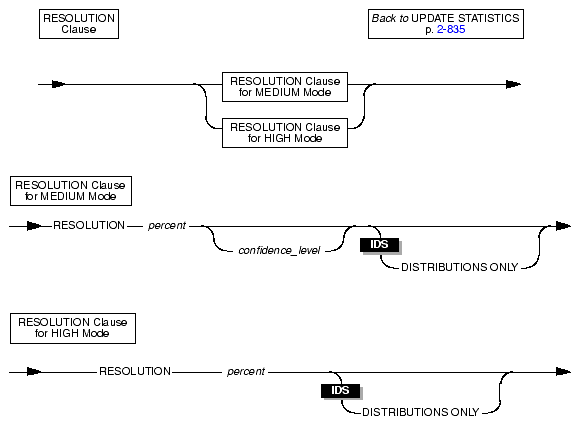
Because the data is obtained by sampling, the results might vary (that is, different sample rows might produce different distribution results). If the results vary significantly, you can adjust the resolution percent or confidence level to obtain more consistent results.
If you do not specify a RESOLUTION clause, the default percentage of data distributed to every bin is 2.5. If you do not specify a value for confidence_level, the default confidence is 0.95. This value can be roughly interpreted to mean that 95 percent of the time, the estimate is equivalent to that obtained from high distributions.
You must have the DBA privilege or be the owner of the table to create medium distributions.
For more on the similarities between the Medium and High Modes, see the Resolution Clause.
Use the HIGH mode option to update the same statistics that you can perform with the low mode and also generate statistics about the distribution of data values for each specified column. The database server places distribution information in the sysdistrib system catalog table.
The constructed distribution is exact. Because of the time required to gather this information, this mode executes more slowly than the LOW and MEDIUM modes.
You must have the DBA privilege or be the owner of the table to create high distributions.
If you do not specify a RESOLUTION clause, the default percentage of data distributed to every bin is 0.5.
If you use the HIGH mode option to update statistics, the database server can take considerable time to gather the information across the database, particularly a database with large tables. The HIGH keyword might scan each table several times (for each column). To minimize processing time, specify a table name and column names within that table.
For more on the similarities between the Medium and High Modes, see the "Resolution Clause."
Use the Resolution clause to adjust the size of the distribution bin, designate whether or not to avoid calculating data on indexes, and with the Medium mode, to adjust the confidence level.
|
A distribution is a mapping of the data in a column into a set of column values. The contents of the column are divided into bins or ranges, each of which contains an equal portion of the column data. For example, if one bin holds 2 percent of the data, 50 of these 2-percent bins hold all the data. A bin contains the particular range of data values that reflects the appropriate percentage of entries in the column.
The optimizer estimates the effect of a WHERE clause by examining, for each column included in the WHERE clause, the proportionate occurrence of data values contained in the column.
You cannot create distributions for BYTE or TEXT columns. If you include a BYTE or TEXT column in an UPDATE STATISTICS statement that specifies medium or high distributions, no distributions are created for those columns. Distributions are constructed for other columns in the list, and the statement does not return an error.
The amount of space that the DBUPSPACE environment variable specifies determines the number of times the database server scans the designated table to construct a distribution.
In Dynamic Server, when you specify the DISTRIBUTIONS ONLY option, you do not update index information. This option does not affect existing index information.
Use this option to avoid the examination of index information that can consume considerable processing time.
This option does not affect the recalculation of information on tables, such as the number of pages used, the number of rows, and fragment information. UPDATE STATISTICS needs this data to construct accurate column distributions and requires little time and system resources to collect it.
Use the Routine Statistics portion of the UPDATE STATISTICS statement to update the optimized execution plans for SPL routines in the sysprocplan system catalog table.

|
The following table explains the keywords that you can use when you update routine statistics.
The sysprocplan system catalog table stores execution plans for SPL routines. Two actions update the sysprocplan system catalog table:
If you change a table that an SPL routine references, you can run UPDATE STATISTICS to reoptimize on demand, rather than waiting until the next time an SPL routine that uses the table executes.
To collect statistics for a column that holds a user-defined data type, you must specify either medium or high mode. When you execute UPDATE STATISTICS, the database server does not collect values for the colmin and colmax columns of the syscolumns table for columns that hold user-defined data types.
To drop statistics for a column that holds one of these data types, you must execute UPDATE STATISTICS in the low mode and use the DROP DISTRIBUTIONS option. When you use this option, the database server removes the row in the sysdistrib system catalog table that corresponds to the tableid and column. In addition, the database server removes any large objects that might have been created for storing the statistics information.
UPDATE STATISTICS collects statistics for opaque data types only if you have defined user-defined routines for statcollect(), statprint(), and the selectivity functions. You must have usage permissions on these routines.
In some cases, UPDATE STATISTICS also requires an sbspace as specified by the SYSSBSPACENAME onconfig parameter. For information about the statistics routines, refer to the DataBlade API Programmer's Manual. For information about SYSSBSPACENAME, refer to your Administrator's Reference.
When you upgrade a database to use with a newer database server, you can use the UPDATE STATISTICS statement to convert the indexes to the form that the newer database server uses. You can choose to convert the indexes one table at a time or for the entire database at one time. Follow the conversion guidelines that are outlined in the Informix Migration Guide.
When you use the UPDATE STATISTICS statement to convert the indexes to use with a newer database server, the indexes are implicitly dropped and re-created. The only time that an UPDATE STATISTICS statement causes table indexes to be implicitly dropped and recreated is when you upgrade a database for use with a newer database server.
The more specific you make the list of objects that UPDATE STATISTICS examines, the faster it completes execution. Limiting the number of columns distributed speeds the update. Similarly, precision affects the speed of the update. If all other keywords are the same, LOW works fastest, but HIGH examines the most data.
Related statements: SET EXPLAIN and SET OPTIMIZATION
For a discussion of the performance implications of UPDATE STATISTICS, see your Performance Guide.
For a discussion of how to use the dbschema utility to view distributions created with UPDATE STATISTICS, see the Informix Migration Guide.