| Informix Guide to SQL: Syntax Segments |
|
An expression is one or more pieces of data that is contained in a table or derived from data in the table. Typically you use expressions to express values in data manipulation statements. Use the Expression segment whenever you see a reference to an expression in a syntax diagram.
For an alphabetical listing of the built-in functions in this segment, see List of Expressions.

|
This segment describes SQL expressions. The following table shows the different types of SQL expressions as shown in the diagram for Syntax and states the purpose of each type.
You can also use host variables or SPL variables as expressions. For a complete list of SQL expressions, see List of Expressions.
Each category of SQL expression includes many individual expressions. The following table lists all the SQL expressions in alphabetical order and states the purpose of each expression. The columns in this table have the following meanings:
Each expression listed in the following table is supported on all database servers unless otherwise noted. When an expression is not supported on all database servers, the Name column notes in parentheses the database server or servers that do support the expression.
The following sections describe the syntax and usage of each expression that appears in the preceding table.
You can combine expressions with arithmetic operators to make complex expressions. To combine expressions, connect them with the following binary arithmetic operators.
| Arithmetic Operation | Arithmetic Operator | Operator Function |
|---|---|---|
| Addition | + | plus() |
| Subtraction | - | minus() |
| Multiplication | * | times() |
| Division | / | divide() |
The following examples use binary arithmetic operators:
If you combine a DATETIME value with one or more INTERVAL values, all the fields of the INTERVAL value must be present in the DATETIME value; no implicit EXTEND function is performed. In addition, you cannot use YEAR to MONTH intervals with DAY to SECOND intervals.
The binary arithmetic operators have associated operator functions, as the preceding table shows. Connecting two expressions with a binary operator is equivalent to invoking the associated operator function on the expressions. For example, the following two statements both select the product of the total_price column and 2. In the first statement, the * operator implicitly invokes the times() function.
You cannot combine expressions that use aggregate functions with column expressions.
The database server provides the operator functions associated with the relational operators for all built-in data types.You can define new versions of these binary arithmetic operator functions to handle your own user-defined data types. For more information, see Extending Informix Dynamic Server 2000.
Informix also provides the following unary arithmetic operators:.
| Arithmetic Operation | Arithmetic Operator | Operator Function |
|---|---|---|
| Positive | + | positive() |
| Negative | - | negate() |
The unary arithmetic operators have the associated operator functions that the preceding table shows. You can define new versions of these arithmetic operator functions to handle your own user-defined data types. For more information on how to write versions of operator functions, see Extending Informix Dynamic Server 2000.
If any value that participates in an arithmetic expression is null, the value of the entire expression is null, as shown in the following example:
If either ship_charge or ship_weight is null, the value returned for the expression ship_charge/ship_weight is also null. If the expression ship_charge/ship_weight is used in a condition, its truth value is unknown.
You can use the concatenation operator (||) to concatenate two expressions. For example, the following examples are some possible concatenated-expression combinations. The first example concatenates the zipcode column to the first three letters of the lname column. The second example concatenates the suffix .dbg to the contents of a host variable called file_variable. The third example concatenates the value returned by the TODAY function to the string Date.
![]() You cannot use the concatenation operator in an embedded-language-only statement. The ESQL/C-only statements appear in the following list:
You cannot use the concatenation operator in an embedded-language-only statement. The ESQL/C-only statements appear in the following list:
You can use the concatenation operator in the SELECT, INSERT, EXECUTE FUNCTION (or EXECUTE PROCEDURE) statement in the DECLARE statement.
You can use the concatenation operator in the SQL statement or statements in the PREPARE statement. 
The concatenation operator (||) has an associated operator function called concat(). You can define a concat() function to handle your own string-based user-defined data types. For more information, see Extending Informix Dynamic Server 2000.
|
| Element | Purpose | Restrictions | Syntax |
|---|---|---|---|
| target_data_type | Data type that results after the cast is applied | See Rules for the Target Data Type. | Data type, p. 4-53 |
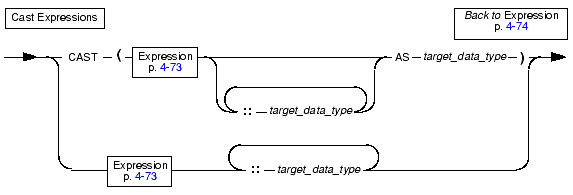
You can use the CAST AS keywords or the double-colon cast operator (::) to cast an expression to another data type. Both the operator and the keywords invoke a cast from the data type of the expression to the target data type. To invoke an explicit cast you must use either the cast operator or the CAST AS keywords. If you use the cast operator or CAST AS keywords, but no explicit or implicit cast was defined to perform the conversion between two data types, the statement returns an error.
You must observe the following rules and restrictions regarding the target data type parameter.
The following examples show two different ways to convert the sum of x and y to a user-defined data type, user_type. The two methods produce identical results. Both require the existence of an explicit or implicit cast from the type returned by x + y to the user-defined type.
The following examples show two different ways of finding the integer equivalent of the expression expr. Both require the existence of an implicit or explicit cast from the data type of expr to the INTEGER data type.
In the following example, the user casts a BYTE column to the BLOB type and copies the BLOB data to an operating-system file:
In the following example, the user casts a TEXT column to a CLOB value and then updates a CLOB column in the same table to have the CLOB value derived from the TEXT column:
The possible syntax for column expressions is shown in the following diagram.

|
The following examples show column expressions:
Use a table or alias name whenever it is necessary to distinguish between columns that have the same name but are in different tables. The SELECT statements that the following example shows use customer_num from the
customer and orders tables. The first example precedes the column names with table names. The second example precedes the column names with table aliases.
Dot notation allows you to qualify an SQL identifier with another SQL identifier. You separate the identifiers with the period (.) symbol. For example, you can qualify a column name with any of the following SQL identifiers:
The previous forms of dot notation are called column projections.
You can also use dot notation to directly access the fields of a row column, as follows:
This use of dot notation is called a field projection. For example, suppose you have a column called rect with the following definition:
The following SELECT statement uses dot notation to access field length of the rect column:
If you want to select all fields of a column that has a row type, you can specify the column name without dot notation. For example, you can select all fields of the rect column as follows:
You can also use asterisk notation to project all the fields of a column that has a row type. For example, if you want to use asterisk notation to select all fields of the rect column, you can enter the following statement:
Asterisk notation is a shorthand form of dot notation that is easier than specifying each field of the rect column individually:
Asterisk notation is not necessary with row-type columns because you can specify just the column name itself to project all of its fields. However, asterisk notation is quite helpful with row-type expressions such as subqueries and user-defined functions that return row-type values. For further information see Using Dot Notation with Row-Type Expressions.
You can use asterisk notation with columns and expressions of row type in the select list of a SELECT statement only. You cannot use asterisk notation with columns and expressions of row type in any other clause of a SELECT statement.
Selecting Nested FieldsWhen the row type that defines a column itself contains other row types, the column contains nested fields. You use dot notation to access these nested fields within a column. For example, assume that the address column of the employee table contains the fields street, city, state, and zip. In addition, the zip field contains the nested fields: z_code and z_suffix. A query on the zip field returns values for the z_code and z_suffix fields. However, you can specify that a query returns only specific nested fields. The following example shows how to use dot notation to construct a SELECT statement that returns rows for the z_code field of the address column only.
The database server uses the following precedence rules to interpret dot notation:
When the meaning of a particular identifier is ambiguous, the database server uses precedence rules to determine which database object the identifier specifies. Consider the following two tables:
In the following SELECT statement, the expression c.d references column d of table c (rather than field d of column c in table b) because a table identifier has a higher precedence than a column identifier:
For more information about precedence rules and how to use dot notation with row columns, see the Informix Guide to SQL: Tutorial.
Using Dot Notation with Row-Type ExpressionsYou can use dot notation whenever a column has a row data type. However, in addition to column expressions, you can use dot notation with any expression that evaluates to a row type. For example, you can use dot notation in a subquery in an INSERT statement if the subquery returns a single row of values. Assume that you have created a row type named row_t:
Also assume that you have created a typed table named tab1 that is based on the row_t row type:
Assume also that you have inserted the following values into table tab1:
Finally, assume that you have created another table named tab2:
Now you can use dot notation to insert the value from just the part_id column of table tab1 into the tab2 table:
The asterisk form of dot notation is not necessary when you want to select all fields of a row type column because you can just specify the column name itself to select all of its fields. However, the asterisk form of dot notation can be quite helpful when you use a subquery as in the preceding example or when you call a user-defined function to return row type values.
Suppose that you create a user-defined function named new_row that returns row type values, and you want to call this function to insert the row type values into a table. Asterisk notation makes it easy to specify that all the row type values produced by the new_row function are to be inserted into the table:
References to the fields of a row-type column or a row-type expression are not allowed in fragment expressions. A fragment expression is an expression that defines a table fragment or an index fragment in statements like CREATE TABLE, CREATE INDEX, and ALTER FRAGMENT.
You can use subscripts on CHAR, VARCHAR, NCHAR, NVARCHAR, BYTE, and TEXT columns. The subscripts indicate the starting and ending character positions that are contained in the expression. Together the column subscripts define a column substring. The column substring is the portion of the column that is contained in the expression.
For example, if a value in the lname column of the customer table is Greenburg, the following expression evaluates to burg:
![]() For information on the GLS aspects of column subscripts and substrings, see the Informix Guide to GLS Functionality.
For information on the GLS aspects of column subscripts and substrings, see the Informix Guide to GLS Functionality.
In Dynamic Server, you can use the rowid column that is associated with a table row as a property of the row. The rowid column is essentially a hidden column in nonfragmented tables and in fragmented tables that were created with the WITH ROWIDS clause. The rowid column is unique for each row, but it is not necessarily sequential. Informix recommends, however, that you use primary keys as an access method rather than exploiting the rowid column.
The following examples show possible uses of the ROWID keyword in a SELECT statement:
The last SELECT statement example shows how to get the page number (the first six digits after 0x) and the slot number (the last two digits) of the location of your row.
You cannot use the ROWID keyword in the select list of a query that contains an aggregate function.
The SELECT, UPDATE, and INSERT statements do not manipulate the values of smart large objects directly. Instead, they use a handle value, which is a type of pointer, to access the BLOB or CLOB value, as follows:
To access the data of a smart-large-object column, you must use one of the following application programming interfaces (APIs):
You cannot use the name of a smart-large-object column in expressions that involve arithmetic operators. For example, operations such as addition or subtraction on the smart-large-object handle value have no meaning.
When you select a smart-large-object column, you can assign the handle value to any number of columns: all columns with the same handle value share the CLOB or BLOB value across several columns. This storage arrangement reduces the amount of disk space that the CLOB or BLOB data takes. However, when several columns share the same smart-large-object value, the following conditions result:
To remove these constraints, you can create separate copies of the BLOB or CLOB data for each column that needs to access it. You can use the LOCOPY function to create a copy of an existing smart large object. You can also use the built-in functions LOTOFILE, FILETOCLOB, and FILETOBLOB to access smart-large-object values. For more information on these functions, see Smart-Large-Object Functions. For more information on the BLOB and CLOB data types, see the Informix Guide to SQL: Reference.
Conditional expressions return values that depend on the outcome of conditional tests. The following diagram shows the syntax for Conditional Expressions.

|
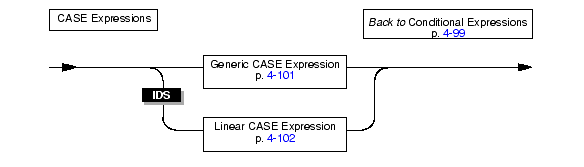
The CASE expression allows an SQL statement such as the SELECT statement to return one of several possible results, depending on which of several condition tests evaluates to true. The CASE expression has two forms as the following diagram shows: generic CASE expressions and linear CASE expressions.
|
You can use a generic or linear CASE expression wherever you can use a column expression in an SQL statement (for example, in the select list of a SELECT statement.) You must include at least one WHEN clause in the CASE expression. Subsequent WHEN clauses and the ELSE clause are optional.
The expressions in the search condition or the result value expression can contain subqueries.
You can nest a CASE expression in another CASE expression.
When a CASE expression appears in an aggregate expression, you cannot use aggregate functions in the CASE expression.
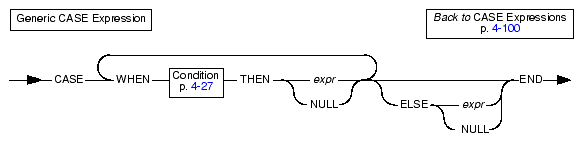
Generic CASE ExpressionsA generic CASE expression tests for a true condition in a WHEN clause and when it finds a true condition it returns the result specified in the THEN clause.
|
The database server processes the WHEN clauses in the order that they appear in the statement. As soon as the database server finds a WHEN clause whose search condition evaluates to true, it takes the corresponding result value expression as the overall result of the CASE expression, and it stops processing the CASE expression.
If no WHEN condition evaluates to true, the database server takes the result of the ELSE clause as the overall result. If no WHEN condition evaluates to true, and no ELSE clause was specified, the resulting value is null. You can use the IS NULL condition to handle null results. For information on how to handle null values, see IS NULL Condition.
The following example shows the use of a generic CASE expression in the select list of a SELECT statement. In this example the user retrieves the name and address of each customer as well as a calculated number that is based on the number of problems that exist for that customer.
In a generic CASE expression, all the results should be of the same type, or they should evaluate to a common compatible type. If the results in all the WHEN clauses are not of the same type, or if they do not evaluate to values of mutually compatible types, an error occurs.
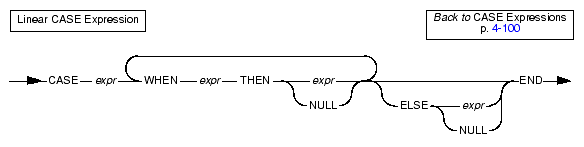
A linear CASE expression tests for a match between the value expression that follows the CASE keyword and a value expression in a WHEN clause.
|
First the database server evaluates the value expression that follows the CASE keyword. Then the database server processes the WHEN clauses in the order that they appear in the CASE expression. As soon as the database server finds a WHEN clause where the value expression after the WHEN keyword evaluates to the same value as the value expression that follows the CASE keyword, it takes the value expression that follows the THEN keyword as the overall result of the CASE expression. Then the database server stops processing the CASE expression.
If none of the value expressions that follow the WHEN keywords evaluates to the same value as the value expression that follows the CASE keyword, the database server takes the result value expression of the ELSE clause as the overall result of the CASE expression. If all of the value expressions that follow the WHEN keyword in all the WHEN clauses do not evaluate to the same value as the value expression that follows the CASE keyword, and the user did not specify an ELSE clause, the resulting value is null.
The following example shows a linear CASE expression in the select list of a SELECT statement. For each movie in a table of movie titles, the SELECT statement displays the title of the movie, the cost of the movie, and the type of movie. The statement uses a CASE expression to derive the type of each movie.
In linear CASE expressions, the types of value expressions in all the WHEN clauses have to be compatible with the type of the value expression that follows the CASE keyword.
The NVL expression returns different results depending on whether its first argument evaluates to null.
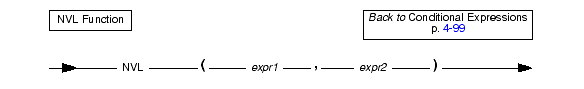
|
NVL evaluates expression1. If expression1 is not null, NVL returns the value of expression1. If expression1 is null, NVL returns the value of expression2. The expressions expression1 and expression2 can be of any data type, as long as they evaluate to a common compatible type.
Suppose that the addr column of the employees table has null values in some rows, and the user wants to be able to print the label Address unknown for these rows. The user enters the following SELECT statement to display the label Address unknown when the addr column has a null value.
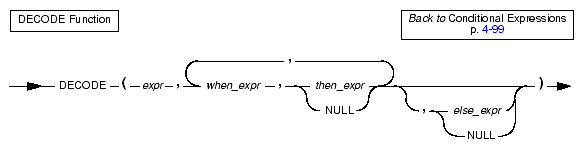
The DECODE expression is similar to the CASE expression in that it can print different results depending on the values found in a specified column.
|
The expressions expr, when_expr, and then_expr are required. DECODE evaluates expr and compares it to when_expr. If the value of when_expr matches the value of expr, DECODE returns then_expr.
The expressions when_expr and then_expr are an expression pair, and you can specify any number of expression pairs in the DECODE function. In all cases, DECODE compares the first member of the pair against expr and returns the second member of the pair if the first member matches expr.
If no expression matches expr, DECODE returns else_expr. However, if no expression matches expr and the user did not specify else_expr, DECODE returns NULL.
You can specify any data type as input, but two limitations exist.
Suppose that a user wants to convert descriptive values in the evaluation column of the students table to numeric values in the output. The following table shows the contents of the students table.
The user now enters a SELECT statement with the DECODE function to convert the descriptive values in the evaluation column to numeric equivalents.
The following table shows the output of this SELECT statement.
The following diagram shows the possible syntax for constant expressions.

|
The following examples show quoted strings as expressions:
For more information, see Quoted String.
The following examples show literal numbers as expressions:
For more information, see Literal Number.
The USER function returns a string that contains the login name of the current user (that is, the person running the process).
The following statements show how you might use the USER function:
The USER function does not change the case of a user ID. If you use USER in an expression and the present user is Robertm, the USER function returns Robertm, not robertm.
If you specify USER as the default value for a column, the column must have a CHAR, VARCHAR, NCHAR, or NVARCHAR data type.
![]() If you specify USER as the default value for a column, Informix recommends that the size of the column be at least 32 bytes long. You risk getting an error message during INSERT and ALTER TABLE operations if the length of the column is too small to store the default value.
If you specify USER as the default value for a column, Informix recommends that the size of the column be at least 32 bytes long. You risk getting an error message during INSERT and ALTER TABLE operations if the length of the column is too small to store the default value.
![]() If you specify USER as the default value for a column, Informix recommends that the size of the column be at least 8 bytes long. You risk getting an error message during INSERT and ALTER TABLE operations if the length of the column is too small to store the default value.
If you specify USER as the default value for a column, Informix recommends that the size of the column be at least 8 bytes long. You risk getting an error message during INSERT and ALTER TABLE operations if the length of the column is too small to store the default value.
![]() In an ANSI-compliant database, if you do not use quotes around the owner name, the name of the table owner is stored as uppercase letters. If you use the USER keyword as part of a condition, you must be sure that the way the user name is stored agrees with the values that the USER function returns, with respect to case.
In an ANSI-compliant database, if you do not use quotes around the owner name, the name of the table owner is stored as uppercase letters. If you use the USER keyword as part of a condition, you must be sure that the way the user name is stored agrees with the values that the USER function returns, with respect to case.
The DBSERVERNAME function returns the database server name, as defined in the ONCONFIG file for the installation where the current database resides or as specified in the INFORMIXSERVER environment variable. The two function names, DBSERVERNAME and SITENAME are synonymous. You can use the DBSERVERNAME function to determine the location of a table, to put information into a table, or to extract information from a table. You can insert DBSERVERNAME into a simple character field or use it as a default value for a column.
If you specify DBSERVERNAME as a default value for a column, the column must have a CHAR, VARCHAR, NCHAR, or NVARCHAR data type.
![]() If you specify DBSERVERNAME as the default value for a column, Informix recommends that the size of the column be at least 128 bytes long. You risk getting an error message during INSERT and ALTER TABLE operations if the length of the column is too small to store the default value.
If you specify DBSERVERNAME as the default value for a column, Informix recommends that the size of the column be at least 128 bytes long. You risk getting an error message during INSERT and ALTER TABLE operations if the length of the column is too small to store the default value.
![]() If you specify DBSERVERNAME as the default value for a column, Informix recommends that the size of the column be at least 18 bytes long. You risk getting an error message during INSERT and ALTER TABLE operations if the length of the column is too small to store the default value.
If you specify DBSERVERNAME as the default value for a column, Informix recommends that the size of the column be at least 18 bytes long. You risk getting an error message during INSERT and ALTER TABLE operations if the length of the column is too small to store the default value.
In the following example, the first statement returns the name of the database server where the customer table resides. Because the query is not restricted with a WHERE clause, it returns DBSERVERNAME for every row in the table. If you add the DISTINCT keyword to the SELECT clause, the query returns DBSERVERNAME once. The second statement adds a row that contains the current site name to a table. The third statement returns all the rows that have the site name of the current system in site_col. The last statement changes the company name in the customer table to the current system name.
Use the TODAY function to return the system date as a DATE data type. If you specify TODAY as a default value for a column, it must be a DATE column.
The following examples show how you might use the TODAY function in an INSERT, UPDATE, or SELECT statement:
The CURRENT function returns a DATETIME value with the date and time of day, showing the current instant.
If you do not specify a datetime qualifier, the default qualifier is YEAR TO FRACTION(3). The USEOSTIME configuration parameter specifies whether or not the database server uses subsecond precision when it obtains the current time from the operating system. For more information on the USEOSTIME configuration parameter, see your Administrator's Reference.
You can use the CURRENT function in any context in which you can use a literal DATETIME (see Literal DATETIME). If you specify CURRENT as the default value for a column, it must be a DATETIME column and the qualifier of CURRENT must match the column qualifier, as the following example shows:
If you use the CURRENT keyword in more than one place in a single statement, identical values can be returned at each point of the call. You cannot rely on the CURRENT function to provide distinct values each time it executes.
The returned value comes from the system clock and is fixed when any SQL statement starts. For example, any call to CURRENT from inside the SPL function that an EXECUTE FUNCTION (or EXECUTE PROCEDURE) statement names returns the value when the SPL function starts.
The CURRENT function is always evaluated in the database server where the current database is located. If the current database is in a remote database server, the returned value is from the remote host.
The CURRENT function might not execute in the physical order in which it appears in a statement. You should not use the CURRENT function to mark the start, end, or a specific point in the execution of a statement.
If your platform does not provide a system call that returns the current time with subsecond precision, the CURRENT function returns a zero for the FRACTION field.
In the following example, the first statement uses the CURRENT function in a WHERE condition. The second statement uses the CURRENT function as the input for the DAY function. The last query selects rows whose call_dtime value is within a range from the beginning of 1997 to the current instant.
For more information, see DATETIME Field Qualifier.
The following examples show literal DATETIME as an expression:
For more information, see Literal DATETIME.
The following examples show literal INTERVAL as an expression:
The second statement in the preceding example adds five days to each value of lead_time selected from the manufact table.
For more information, see Literal INTERVAL.
The UNITS keyword enables you to display a simple interval or increase or decrease a specific interval or datetime value.
If n is not an integer, it is rounded down to the nearest whole number when it is used.
In the following example, the first SELECT statement uses the UNITS keyword to select all the manufacturer lead times, increased by five days. The second SELECT statement finds all the calls that were placed more than 30 days ago. If the expression in the WHERE clause returns a value greater than 99 (maximum number of days), the query fails. The last statement increases the lead time for the ANZA manufacturer by two days.
The following examples show literal collections as expressions:
For more information, see Literal Collection. For syntax that allows you to use expressions that evaluate to element values, see Collection Constructors.
The following examples show literal rows as expressions:
For more information, see Literal Row. For syntax that allows you to use expressions that evaluate to field values, see ROW Constructors.
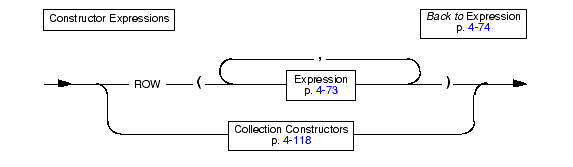
A constructor is a function that the database server uses to create an instance of a particular data type. The database server supports ROW and collection constructors.
|
You use ROW constructors to generate values for row-type columns. Suppose you create the following named row type and a table that contains the named row type row_t and an unnamed row type:
When you define a column as a named row type or unnamed row type, you must use a ROW constructor to generate values for the row column. To create a value for either a named row type or unnamed row type, you must complete the following steps:
The format of the value for each field must be compatible with the data type of the row field to which it is assigned.
You can use any kind of expression as a value with a ROW constructor, including literals, functions, and variables. The following examples show the use of different types of expressions with ROW constructors to specify values:
The following statement uses literal numbers and quoted strings with ROW constructors to insert values into col1 and col2 of the new_tab table:
When you use a ROW constructor to generate values for a named row type, you must explicitly cast the row value to the appropriate named row type. The cast is necessary to generate a value of the named row type. To cast the row value as a named row type, you can use the cast operator (::) or the CAST AS keywords, as shown in the following examples:
You can use a ROW constructor to generate row type values not only in INSERT and UPDATE statements but also in SELECT statements. In the following example, the WHERE clause of a SELECT statement specifies a row type value that is cast as type person_t
For further information on using ROW constructors in INSERT and UPDATE statements, see the INSERT and UPDATE statements in this manual. For information on named row types, see the CREATE ROW TYPE statement. For information on unnamed row types, see the discussion of the ROW data type in the Informix Guide to SQL: Reference. For task-oriented information on named row types and unnamed row types, see the Informix Guide to Database Design and Implementation.
Use a collection constructor to specify values for a collection column.
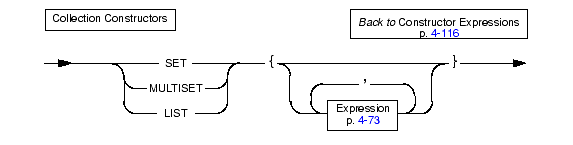
|
You can use collection constructors in the WHERE clause of the SELECT statement and the VALUES clause of the INSERT statement. You can also pass collection constructors to UDRs.
The following table differentiates the types of collections that you can construct.
You can use any kind of expression with a collection constructor, including literals, functions, and variables. When you use a collection constructor with a list of arbitrary expressions, the database server evaluates each expression to its equivalent literal form and uses the literal values to construct the collection.
You specify an empty collection with a set of empty braces ({}).
The element type of the collection can be any built-in or extended data type.
Restrictions on Collection ConstructorsElements of a collection cannot be null, therefore if an expression element evaluates to a null value the database server returns an error.
The element type of each expression must be homogeneous, that is, they must be exactly the same type. This can be accomplished by casting the entire collection constructor expression to a collection type, or by casting individual element expressions to the same type.
If the database server cannot determine the collection type and the element types are not homogeneous, then the collection constructor will return an error. In the case of host variables, this determination is made at bind time when the client informs the database server the element type of the host variable.
Examples of Collection ConstructorsThe following extended example illustrates that you can construct collection with many various expressions as long as the resulting values are of the same type.
This example assumes that a cast from BOOLEAN to INT exists.
For information about a more restrictive, but still-supported syntax for how to specify values for a collection column, see Literal Collection.
A function expression can call built-in functions or user-defined functions, as the following diagram shows.
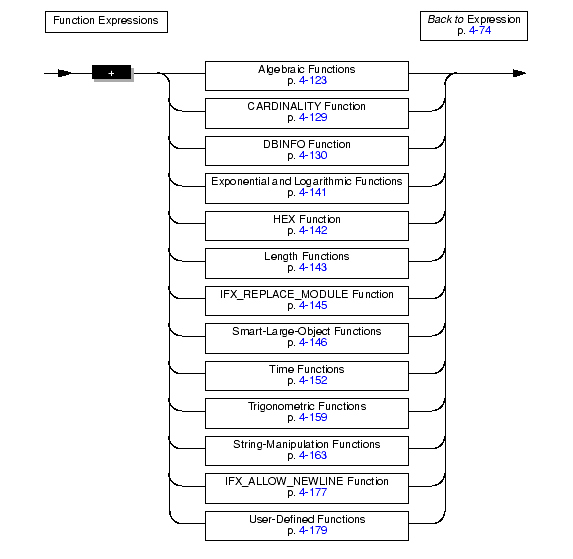
|
The following examples show function expressions:
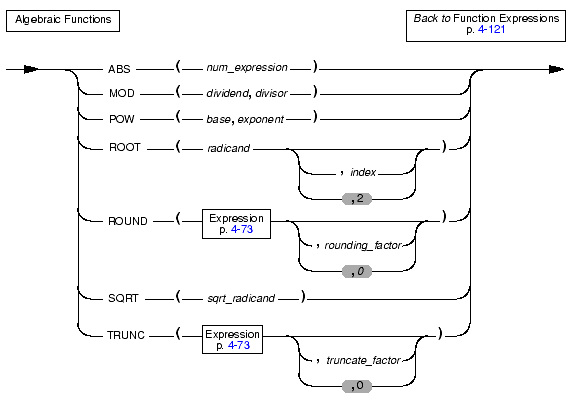
An algebraic function takes one or more arguments, as the following diagram shows.
|
The ABS function gives the absolute value for a given expression. The function requires a single numeric argument. The value returned is the same as the argument type. The following example shows all orders of more than $20 paid in cash (+) or store credit (-). The stores_demo database does not contain any negative balances; however, you might have negative balances in your appli����������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������������i class="bs-bullet-sub">Set file destination to client to identify the client computer as the location of the source file. The pathname can be either a full pathname or relative to the current directory.
The table and column parameters are optional:
The FILETOBLOB function returns a handle value (a pointer) to the new BLOB value. Similarly, the FILETOCLOB function returns a handle value to the new CLOB value. Neither of these functions actually stores the smart-large-object value into a column in the database. You must assign the BLOB or CLOB value to the appropriate column.
![]() The FILETOCLOB function performs any code-set conversion that might be required when it copies the file from the client or server computer to the database.
The FILETOCLOB function performs any code-set conversion that might be required when it copies the file from the client or server computer to the database.
The following INSERT statement uses the FILETOCLOB function to create a CLOB value from the value in the haven.rsm file:
In the preceding example, the FILETOCLOB function reads the haven.rsm file in the current directory on the client computer and returns a handle value to a CLOB value that contains the data in this file. Because the FILETOCLOB function does not specify a table and column name, this new CLOB value has the system-specified storage characteristics. The INSERT statement then assigns this CLOB value to the resume column in the candidate table.
LOTOFILE FunctionThe LOTOFILE function copies a smart large object to an operating-system file. The first parameter specifies the BLOB or CLOB column to copy. The function determines the operating-system file to create from the following parameters:
By default, the LOTOFILE function generates a filename of the form:
In this format, file is the filename you specify in pathname and hex_id is the unique hexadecimal smart-large-object identifier. The maximum number of digits for a smart-large-object identifier is 17; however most smart large objects would have an identifier with significantly fewer digits.
![]() For example, suppose you specify a pathname value as follows:
For example, suppose you specify a pathname value as follows:
If the CLOB column has an identifier of 203b2, the LOTOFILE function would create the file:
![]() For example, suppose you specify a pathname value as follows:
For example, suppose you specify a pathname value as follows:
If the CLOB column has an identifier of 203b2, the LOTOFILE function would create the file:
To change the default filename, you can specify the following wildcards in the filename of the pathname:
If the filename you specify already exists, LOTOFILE returns an error.
![]() The LOTOFILE function performs any code-set conversion that might be required when it copies a CLOB value from the database to a file on the client or server computer.
The LOTOFILE function performs any code-set conversion that might be required when it copies a CLOB value from the database to a file on the client or server computer.
The LOCOPY function creates a copy of a smart large object. The first parameter specifies the BLOB or CLOB column to copy. The table and column parameters are optional:
The LOCOPY function returns a handle value (a pointer) to the new BLOB or CLOB value. This function does not actually store the new smart-large-object value into a column in the database. You must assign the BLOB or CLOB value to the appropriate column.
The following ESQL/C code fragment copies the CLOB value in the resume column of the candidate table to the resume column of the interview table:
In the preceding example, the LOCOPY function returns a handle value for the copy of the CLOB resume column in the candidate table. Because the LOCOPY function specifies a table and column name, this new CLOB value has the storage characteristics of this resume column. If you omit the table (candidate) and column (resume) names, the LOCOPY function uses the system-defined storage defaults for the new CLOB value. The UPDATE statement then assigns this new CLOB value to the resume column in the interviews table.

|
The DATE function returns a DATE value that corresponds to the non-date expression with which you call it. The argument can be any expression that can be converted to a DATE value, usually a CHAR, DATETIME, or INTEGER value. The following WHERE clause specifies a CHAR value for the non-date expression:
When the DATE function interprets a CHAR non-date expression, it expects this expression to conform to any DATE format that the DBDATE environment specifies. For example, suppose DBDATE is set to Y2MD/ when you execute the following query:
This SELECT statement generates an error because the DATE function cannot convert this non-date expression. The DATE function interprets the first part of the date string (02) as the year and the second part (01) as the month. For the third part (1998), the DATE function encounters four digits when it expects a two-digit day (valid day values must be between 01 and 31). It therefore cannot convert the value. For the SELECT statement to execute successfully with the Y2MD/ value for DBDATE, the non-date expression would need to be '98/02/01'. For information on the format of DBDATE, see the Informix Guide to SQL: Reference.
When you specify a positive INTEGER value for the non-date expression, the DATE function interprets the value as the number of days after the default date of December 31, 1899. If the integer value is negative, the DATE function interprets the value as the number of days before December 31, 1899. The following WHERE clause specifies an INTEGER value for the non-date expression:
The database server searches for rows with an order_date value less than December 31, 1900 (12/31/1899 plus 365 days).
DAY Function
The DAY function returns an integer that represents the day of the month.
The following example uses the DAY function with the CURRENT function to compare column values to the current day of the month:
The MONTH function returns an integer that corresponds to the month portion of its type DATE or DATETIME argument. The following example returns a number from 1 through 12 to indicate the month when the order was placed:
The WEEKDAY function returns an integer that represents the day of the week; zero (0) represents Sunday, one represents Monday, and so on. The following lists all the orders that were paid on the same day of the week, which is the current day:
The YEAR function returns a four-digit integer that represents the year. The following example lists orders in which the ship_date is earlier than the beginning of the current year:
Similarly, because a DATE value is a simple calendar date, you cannot add or subtract a DATE value with an INTERVAL value whose last qualifier is smaller than DAY. In this case, convert the DATE value to a DATETIME value.
EXTEND FunctionThe EXTEND function adjusts the precision of a DATETIME or DATE value. The expression cannot be a quoted string representation of a DATE value.
If you do not specify first and last qualifiers, the default qualifiers are YEAR TO FRACTION(3).
If the expression contains fields that are not specified by the qualifiers, the unwanted fields are discarded.
If the first qualifier specifies a larger (that is, more significant) field than what exists in the expression, the new fields are filled in with values returned by the CURRENT function. If the last qualifier specifies a smaller field (that is, less significant) than what exists in the expression, the new fields are filled in with constant values. A missing MONTH or DAY field is filled in with 1, and the missing HOUR to FRACTION fields are filled in with 0.
In the following example, the first EXTEND call evaluates to the call_dtime column value of YEAR TO SECOND. The second statement expands a literal DATETIME so that an interval can be subtracted from it. You must use the EXTEND function with a DATETIME value if you want to add it to or subtract it from an INTERVAL value that does not have all the same qualifiers. The third example updates only a portion of the datetime value, the hour position. The EXTEND function yields just the hh:mm part of the datetime. Subtracting 11:00 from the hours and minutes of the datetime yields an INTERVAL value of the difference, plus or minus, and subtracting that from the original value forces the value to 11:00.
The MDY function returns a type DATE value with three expressions that evaluate to integers representing the month, day, and year. The first expression must evaluate to an integer representing the number of the month (1 to 12).
The second expression must evaluate to an integer that represents the number of the day of the month (1 to 28, 29, 30, or 31, as appropriate for the month.)
The third expression must evaluate to a four-digit integer that represents the year. You cannot use a two-digit abbreviation for the third expression. The following example sets the paid_date associated with the order number 8052 equal to the first day of the present month:
The TO_CHAR function converts a DATE or DATETIME value to a character string. The character string contains the date that was specified in the source_date parameter, and represents this date in the format that was specified in the format_string parameter.
![]() You can use this function only with built-in data types.
You can use this function only with built-in data types.
If the value of the source_date parameter is null, the result of the function is a null value.
If you omit the format_string parameter, the TO_CHAR function uses the default date format to format the character string. The default date format is specified by environment variables such as GL_DATETIME and GL_DATE.
The format_string parameter does not have to imply the same qualifiers as the source_date parameter. When the implied formatting mask qualifier in format_ string is different from the qualifier in source_date, the TO_CHAR function extends the DATETIME value as if it had called the EXTEND function.
In the following example, the user wants to convert the begin_date column of the tab1 table to a character string. The begin_date column is defined as a DATETIME YEAR TO SECOND data type. The user uses a SELECT statement with the TO_CHAR function to perform this conversion.
The symbols in the format_string parameter in this example have the following meanings. For a complete list of format symbols and their meanings, see the GL_DATE and GL_DATETIME environment variables in the Informix Guide to GLS Functionality.
The result of applying the specified format_string to the begin_date column is as follows:
The TO_DATE function converts a character string to a DATETIME value. The function evaluates the char_expression parameter as a date according to the date format you specify in the format_string parameter, and returns the equivalent date.
![]() You can use this function only with built-in data types.
You can use this function only with built-in data types.
If the value of the char_expression parameter is null, the result of the function is a null value.
If you omit the format_string parameter, the TO_DATE function applies the default DATETIME format to the DATETIME value. The default DATETIME format is specified by the GL_DATETIME environment variable.
In the following example, the user wants to convert a character string to a DATETIME value in order to update the begin_date column of the tab1 table with the converted value. The begin_date column is defined as a DATETIME YEAR TO SECOND data type. The user uses an UPDATE statement that contains a TO_DATE function to accomplish this result.
The format_string parameter in this example tells the TO_DATE function how to format the converted character string in the begin_date column. For a table that shows the meaning of each format symbol in this format string, see TO_CHAR Function.
A trigonometric function takes an argument, as the following diagram shows.

|
The COS, SIN, and TAN functions take the number of radians (radian_expr) as an argument.
If you are using degrees and want to convert degrees to radians, use the following formula:
The COS function returns the cosine of a radian expression. The following example returns the cosine of the values of the degrees column in the anglestbl table. The expression passed to the COS function in this example converts degrees to radians.
The SIN function returns the sine of a radian expression. The following example returns the sine of the values in the radians column of the anglestbl table:
The TAN function returns the tangent of a radian expression. The following example returns the tangent of the values in the radians column of the anglestbl table:
The ACOS function returns the arc cosine of a numeric expression. The following example returns the arc cosine of the value (-0.73) in radians:
The ASIN function returns the arc sine of a numeric expression. The following example returns the arc sine of the value (-0.73) in radians:
The ATAN function returns the arc tangent of a numeric expression. The following example returns the arc tangent of the value (-0.73) in radians:
The ATAN2 function computes the angular component of the polar coordinates (r,  ) associated with (x, y). The following example compares angles to for the rectangular coordinates (4, 5):
) associated with (x, y). The following example compares angles to for the rectangular coordinates (4, 5):
for (4,5) andYou can determine the length of the radial coordinate r using the expression shown in the following example:
You can determine the length of the radial coordinate r for the rectangular coordinates (4,5) using the expression shown in the following example:
String-manipulation functions perform various operations on strings of characters. The syntax for string-manipulation functions is as follows.

|
Use the TRIM function to remove leading or trailing (or both) pad characters from a string.
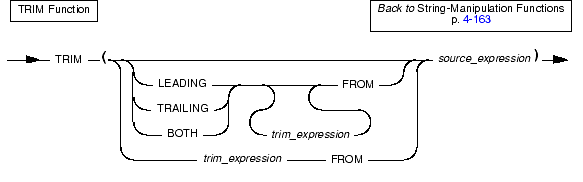
|
The TRIM function returns a VARCHAR string that is identical to the character string passed to it, except that any leading or trailing pad characters, if specified, are removed. If no trim specification (LEADING, TRAILING, or BOTH) is specified, then BOTH is assumed. If no trim_expression is used, a single space is assumed. If either the trim_expression or the source_expression evaluates to null, the result of the trim function is null. The maximum length of the resultant string must be 255 or less, because the VARCHAR data type supports only 255 characters.
Some generic uses for the TRIM function are shown in the following example:
![]() When you use the DESCRIBE statement with a SELECT statement that uses the TRIM function in the select list, the described character type of the trimmed column depends on the database server you are using and the data type of the source_expression. For further information on the GLS aspects of the TRIM function in ESQL/C, see the Informix Guide to GLS Functionality.
When you use the DESCRIBE statement with a SELECT statement that uses the TRIM function in the select list, the described character type of the trimmed column depends on the database server you are using and the data type of the source_expression. For further information on the GLS aspects of the TRIM function in ESQL/C, see the Informix Guide to GLS Functionality.
The TRIM function can be specified on fixed-length character columns. If the length of the string is not completely filled, the unused characters are padded with blank space. Figure 4-3 shows this concept for the column entry '##A2T##', where the column is defined as CHAR(10).
If you want to trim the pound sign (#) trim_expression from the column, you need to consider the blank padded spaces as well as the actual characters. For example, if you specify the trim specification BOTH, the result from the trim operation is A2T##, because the TRIM function does not match the blank padded space that follows the string. In this case, the only pound signs (#) trimmed are those that precede the other characters. The SELECT statement is shown, followed by Figure 4-4, which presents the result.
The following SELECT statement removes all occurrences of the pound sign (#):
The SUBSTRING function returns a subset of a source string.

|
![]() You can use this function only with built-in data types.
You can use this function only with built-in data types.
The subset begins at the column position that start_position specifies. The following table shows how the database server determines the starting position of the returned subset based on the input value of the start_position.
The size of the subset is specified by length. The length parameter refers to the number of logical characters rather than to the number of bytes. If you omit the length parameter, the SUBSTRING function returns the entire portion of source_ string that begins at start_position.
In the following example, the user specifies that the subset of the source string that begins in column position 3 and is two characters long should be returned.
The following table shows the output of this SELECT statement.
In the following example, the user specifies a negative start_position for the return subset.
The database server starts at the -3 position (four positions before the first character) and counts forward for 7 characters. The following table shows the output of this SELECT statement.
SUBSTR Function
The SUBSTR function has the same purpose as the SUBSTRING function (to return a subset of a source string), but it uses different syntax.
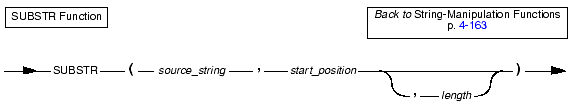
|
![]() You can use this function only with built-in data types.
You can use this function only with built-in data types.
The SUBSTR function returns a subset of source_string. The subset begins at the column position that start_position specifies. The following table shows how the database server determines the starting position of the returned subset based on the input value of the start_position.
The length parameter specifies the number of characters (not bytes) in the subset. If you omit the length parameter, the SUBSTR function returns the entire portion of source_ string that begins at start_position.
In the following example, the user specifies that the subset of the source string to be returned begins at a starting position 3 characters back from the end of the string. Because the source string is 7 characters long, the starting position is the fifth column of source_string. Because the user does not specify a value for length, the database server returns the entire portion of the source string that begins in column position 5.
The following table shows the output of this SELECT statement.
REPLACE Function
The REPLACE function replaces specified characters within a source string with different characters.
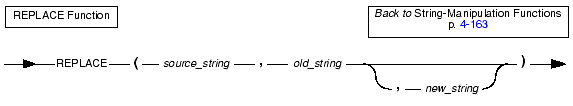
|
![]() You can use this function only with built-in data types.
You can use this function only with built-in data types.
The REPLACE function returns a copy of source_string in which every occurrence of old_string is replaced by new_string. If you omit the new_string option, every occurrence of old_string is omitted from the return string.
In the following example, the user replaces every occurrence of xz in the source string with t.
The following table shows the output of this SELECT statement.
LPAD Function
The LPAD function returns a copy of source_string that is left-padded to the total number of characters specified by length.
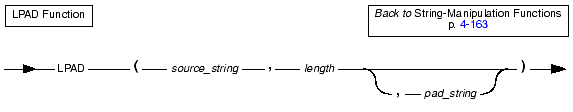
|
![]() You can use this function only with built-in data types.
You can use this function only with built-in data types.
The pad_string parameter specifies the pad character or characters to be used for padding the source string. The sequence of pad characters occurs as many times as necessary to make the return string reach the length specified by length. The sequence of pad characters in pad_string is truncated if it is too long to fit into length. If you omit the pad_string parameter, the default value is a single blank.
In the following example, the user specifies that the source string is to be left-padded to a total length of 16 characters. The user also specifies that the pad characters are a sequence consisting of a dash and an underscore (-_).
The following table shows the output of this SELECT statement.
RPAD Function
The RPAD function returns a copy of source_string that is right-padded to the total number of characters that length specifies.
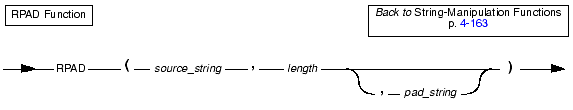
|
![]() You can use this function only with built-in data types.
You can use this function only with built-in data types.
The pad_string parameter specifies the pad character or characters to be used to pad the source string. The sequence of pad characters occurs as many times as necessary to make the return string reach the length that length specifies. The sequence of pad characters in pad_string is truncated if it is too long to fit into length. If you omit the pad_string parameter, the default value is a single blank.
In the following example, the user specifies that the source string is to be right-padded to a total length of 18 characters. The user also specifies that the pad characters to be used are a sequence consisting of a question mark and an exclamation point (?!)
The following table shows the output of this SELECT statement.
The case-conversion functions enable you to perform case-insensitive searches in your queries and specify the format of the output. The case-conversion functions are UPPER, LOWER, and INITCAP. The following diagram shows the syntax of these case-conversion functions.

|
The input type of source_expression must be a character data type. When the column is described, the data type the database server returns is the same as the input type. For example, if the input type is CHAR, the output type is also CHAR.
![]() You can use these functions only with built-in data types.
You can use these functions only with built-in data types.
![]() The byte length returned from the describe of a column with a case-conversion function is the input byte length of the source string. If you use a case-conversion function with a multibyte source_expression, the conversion might increase or decrease the length of the string. If the byte length of the result string exceeds the byte length of source_expression, the database server truncates the result string to fit into the byte length of source_expression.
The byte length returned from the describe of a column with a case-conversion function is the input byte length of the source string. If you use a case-conversion function with a multibyte source_expression, the conversion might increase or decrease the length of the string. If the byte length of the result string exceeds the byte length of source_expression, the database server truncates the result string to fit into the byte length of source_expression.
If source_expression is null, the result of a case-conversion function is also null.
The database server treats a case-conversion function as an SPL routine in the following instances:
If none of the conditions in the preceding list are met, the database server treats a case-conversion function as a system function.
The following example shows how you can use all the case-conversion functions in the same query to specify multiple output formats for the same value:
The UPPER function returns a copy of the source_expression in which every lowercase alphabetical character in the source_expression is replaced by a corresponding uppercase alphabetic character.
The following example shows how to use the UPPER function to perform a case-insensitive search on the lname column for all employees with the last name of curran:
Because the INITCAP function is specified in the select list, the database server returns the results in a mixed-case format. For example, the output of one matching row might read: accountant James Curran.
LOWER FunctionThe LOWER function returns a copy of the source_expression in which every uppercase alphabetic character in the source_expression is replaced by a corresponding lowercase alphabetic character.
The following example shows how to use the LOWER function to perform a case-insensitive search on the City column. This statement directs the database server to replace all instances (that is, any variation) of the words san jose, with the mixed-case format, San Jose.
The INITCAP function returns a copy of the source_expression in which every word in the source_expression begins with uppercase letter. With this function, a word begins after any character other than a letter. Thus, in addition to a blank space, symbols such as commas, periods, colons, and so on, introduce a new word.
For an example of the INITCAP function, see UPPER Function.
The IFX_ALLOW_NEWLINE function sets a newline mode that allows newline characters in quoted strings or disallows newline characters in quoted strings within a given session.

|
If you enter 't' as the argument of this function, you enable newline characters in quoted strings in the session. If you enter 'f' as the argument of this function, you disallow newline characters in quoted strings in the session.
You can set the newline mode for all sessions by setting the ALLOW_NEWLINE parameter in the ONCONFIG file to a value of 0 (newline characters not allowed) or to a value of 1 (newline characters allowed). If you do not set this configuration parameter, the default value is 0. Each time you start a session, the new session inherits the newline mode set in the ONCONFIG file. To change the newline mode for the session, execute the IFX_ALLOW_NEWLINE function. Once you have set the newline mode for a session, the mode remains in effect until the end of the session or until you execute the IFX_ALLOW_NEWLINE function again within the session.
In the following example, assume that you did not specify any value for the ALLOW_NEWLINE parameter in the ONCONFIG file, so by default newline characters are not allowed in quoted strings in any session. After you start a new session, you can enable newline characters in quoted strings in that session by executing the IFX_ALLOW_NEWLINE function:
![]() The newline mode that is set by the ALLOW_NEWLINE parameter in the ONCONFIG file or by the execution of the IFX_ALLOW_NEWLINE function in a session applies only to quoted-string literals in SQL statements. The newline mode does not apply to quoted strings contained in host variables in SQL statements. Host variables can contain newline characters within string data regardless of the newline mode currently in effect. For example, you can use a host variable to insert data containing newline characters into a column even if the ALLOW_NEWLINE parameter in the ONCONFIG file is set to 0.
The newline mode that is set by the ALLOW_NEWLINE parameter in the ONCONFIG file or by the execution of the IFX_ALLOW_NEWLINE function in a session applies only to quoted-string literals in SQL statements. The newline mode does not apply to quoted strings contained in host variables in SQL statements. Host variables can contain newline characters within string data regardless of the newline mode currently in effect. For example, you can use a host variable to insert data containing newline characters into a column even if the ALLOW_NEWLINE parameter in the ONCONFIG file is set to 0.
For further information on how the IFX_ALLOW_NEWLINE function affects quoted strings, see Quoted String. For further information on the ALLOW_NEWLINE parameter in the ONCONFIG file, see the Administrator's Reference.
A user-defined function is a function that you write in SPL or in a language external to the database, such as C or Java.
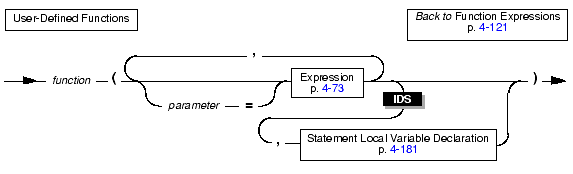
|
You can call user-defined functions within SQL statements. Unlike built-in functions, user-defined functions can only be used by the creator of the function, the DBA, and the users who have been granted the Execute privilege on the function. For more information, see GRANT.
The following examples show some user-defined function expressions. The first example omits the parameter option when it lists the function argument:
This second example uses the parameter option to specify the argument value:
When you use the parameter option, the parameter name must match the name of the corresponding parameter in the function registration. For example, the preceding example assumes that the read_address() function had been registered as follows:
![]() A statement-local variable (SLV) enables you to transmit a value from a user-defined function call to another part of the SQL statement. To use an SLV with a call to a user-defined function, follow these steps:
A statement-local variable (SLV) enables you to transmit a value from a user-defined function call to another part of the SQL statement. To use an SLV with a call to a user-defined function, follow these steps:
The Statement-Local Variable Declaration declares a statement-local variable (SLV) in a call to a user-defined function that defines an OUT parameter.

You declare an SLV in a user-defined function call so that a user-defined function can assign the value of its OUT parameter to the SLV. The call to the user-defined function must exist in the WHERE clause of the SQL statement. For example, if you register a function with the following CREATE FUNCTION statement, you can use its y parameter as a statement-local variable in a WHERE clause:
In this example, find_location() accepts two FLOAT values that represent a latitude and a longitude and returns the name of the nearest city, along with an extra value of type INTEGER that represents the population rank of the city.
You can now call find_location() in a WHERE clause:
The function expression passes two FLOAT values to find_location() and declares an SLV named rank of type INT. In this case, find_location() will return the name of the city nearest latitude 32.1 and longitude 35.7 (which may be a heavily populated area) whose population rank is between 1 and 100. The statement will then return the zip code that corresponds to that city.
The WHERE clause of the SQL statement must produce an SLV that is used within other parts of the statement. The following SELECT statement is illegal because the select list produces the SLV:
The data type you use when you declare the SLV in a statement must be the same as the data type of the OUT parameter in the CREATE FUNCTION statement. If you use different but compatible data types, such as INTEGER and FLOAT, the database server automatically performs the cast between the data types.
SLVs shared the name space with UDR variables and the column names of the table involved in the SQL statement. Therefore, the database uses the following precedence to resolve ambiguous situations:
Once the user-defined function assigns its OUT parameter to the SLV, you can use this SLV value in other parts of the SQL statement. For more information, see Statement-Local Variable Expressions.
The Statement-Local Variable Expression specifies how you can use a defined statement-local variable (SLV) elsewhere in an SQL statement.
You define an SLV in the call to a user-defined function in the WHERE clause of the SQL statement. This user-defined function must be defined with an OUT parameter. The call to the user-defined function assigns the value of the OUT parameter to the SLV. For more information, see Statement-Local Variable Declaration.
Once the user-defined function assigns its OUT parameter to the SLV, you can use this value in other parts of the SQL statement. You can use the value of this OUT parameter elsewhere in the statement, subject to the following scoping rules:
The following SELECT statement calls the find_location() function in a WHERE clause and defines the rank SLV. In this example, find_location() accepts two values that represent a latitude and a longitude and returns the name of the nearest city, along with an extra value of type INTEGER that represents the population rank of the city.
When execution of the find_location() function completes successfully, the function has initialized the rank SLV. The SELECT then uses this rank value in a second WHERE-clause condition. In this example, the Statement-Local Variable Expression is the variable rank in the second WHERE-clause condition:
If the user-defined function that initializes the SLV is not executed in an iteration of the statement, the SLV has a value of null. SLV values do not persist across iterations of the statement. At the start of each iteration, the database server sets the SLV value to null.
Each user-defined function can have only one OUT parameter and one SLV. However, a single SQL statement can invoke multiple functions that have OUT parameters. For example, the following partial statement calls two user-defined functions with OUT parameters, whose values are referenced with the SLV names out1 and out2:
For more information on how to write a user-defined function with an OUT parameter, see Extending Informix Dynamic Server 2000.
An aggregate expression uses an aggregate function to summarize selected database data.
You cannot use an aggregate expression in a condition that is part of a WHERE clause unless you use the aggregate expression within a subquery.

|
An aggregate function returns one value for a set of queried rows. The following examples show aggregate functions in SELECT statements:
If you use an aggregate function and one or more columns in the select list, you must put all the column names that are not used as part of an aggregate or time expression in the GROUP BY clause.
You can use two types of aggregate expressions in SQL statements: built-in aggregates and user-defined aggregates. The built-in aggregates include all the aggregates shown in the syntax diagram in Aggregate Expressions except for the "User-Defined Aggregates" category. User-defined aggregates are any new aggregates that the user creates with the CREATE AGGREGATE statement.
Built-in AggregatesBuilt-in aggregates are aggregate expressions that are provided by the database server, such as AVG, SUM, and COUNT. By default, these aggregates work only with built-in data types, such as INTEGER and FLOAT.
You can extend these built-in aggregates to work with extended data types. To extend built-in aggregates, you must create UDRs that overload several binary operators.
Once you have overloaded the binary operators for a built-in aggregate, you can use that aggregate with an extended data type in an SQL statement. For example, if you have overloaded the plus operator for the SUM aggregate to work with a specified row type and assigned this row type to the complex column of the complex_tab table, you can apply the SUM aggregate to the complex column:
For further information on extending built-in aggregates, see the Extending Informix Dynamic Server 2000 manual.
For information on invoking built-in aggregates, see the descriptions of individual built-in aggregates in the following pages.
User-Defined AggregatesA user-defined aggregate is an aggregate that you define to perform an aggregate computation that is not provided by the database server. For example, you can create a user-defined aggregate named SUMSQ that returns the sum of the squared values of a specified column. User-defined aggregates can work with built-in data types or extended data types or both, depending on how you define the support functions for the user-defined aggregate.
To create a user-defined aggregate, use the CREATE AGGREGATE statement. In this statement you name the new aggregate and specify the support functions for the aggregate. Once you have created the new aggregate and its support functions, you can use the aggregate in SQL statements. For example, if you have created the SUMSQ aggregate and specified that it works with the FLOAT data type, you can apply the SUMSQ aggregate to a FLOAT column named digits in the test table:
For further information on creating user-defined aggregates, see CREATE AGGREGATE and the discussion of user-defined aggregates in the Extending Informix Dynamic Server 2000 manual.
For information on invoking user-defined aggregates, see User-Defined Aggregates.
As indicated in the diagrams for Aggregate Expressions and User-Defined Aggregates, not all expressions are available for you to use when you use an aggregate expression. The argument of an aggregate function cannot itself contain an aggregate function. You cannot use the aggregate functions in the following situations:
You cannot use a collection column as an argument to the following aggregate functions:
For the full syntax of expressions, see Expression.
The DISTINCT keyword causes the function to be applied only to unique values from the named column. The UNIQUE keyword is a synonym for the DISTINCT keyword.
The ALL keyword is the opposite of the DISTINCT keyword. If you specify the ALL keyword, all the values that are selected from the named column or expression, including any duplicate values, are used in the calculation.
The COUNT function is actually a set of functions that enable you to count column values and expressions in different ways. You invoke each form of the COUNT function by specifying a particular argument after the COUNT keyword. Each form of the COUNT function is explained in the following subsections. For a comparison of the different forms of the COUNT function, see Comparison of the Different COUNT Functions.
The COUNT (*) function returns the number of rows that satisfy the WHERE clause of a SELECT statement. The following example finds how many rows in the stock table have the value HRO in the manu_code column:
If the SELECT statement does not have a WHERE clause, the COUNT (*) function returns the total number of rows in the table. The following example finds how many rows are in the stock table:
If the SELECT statement contains a GROUP BY clause, the COUNT (*) function reflects the number of values in each group. The following example is grouped by the first name; the rows are selected if the database server finds more than one occurrence of the same name:
If the value of one or more rows is null, the COUNT (*) function includes the null columns in the count unless the WHERE clause explicitly omits them.
The COUNT DISTINCT function return the number of unique values in the column or expression, as the following example shows. If the COUNT DISTINCT function encounters nulls, it ignores them.
Nulls are ignored unless every value in the specified column is null. If every column value is null, the COUNT DISTINCT function returns a zero (0) for that column.
The UNIQUE keyword has exactly the same meaning as the DISTINCT keyword when the UNIQUE keyword is used with the COUNT keyword. The UNIQUE keyword returns the number of unique non-null values in the column or expression.
The following example uses the COUNT UNIQUE function, but it is equivalent to the preceding example that uses the COUNT DISTINCT function:
The COUNT column function returns the total number of non-null values in the column or expression, as the following example shows:
You can include the ALL keyword before the specified column name for clarity, but the query result is the same whether you include the ALL keyword or omit it.
The following example shows how to include the ALL keyword in the COUNT column function:
You can use the different forms of the COUNT function to retrieve different types of information about a table. The following table summarizes the meaning of each form of the COUNT function.
Some examples can help to show the differences among the different forms of the COUNT function. The following examples pose queries against the orders table in the demonstration database. Most of the examples query against the ship_instruct column in this table. For information on the structure of the orders table and the data in the ship_instruct column, see the description of the demonstration database in the Informix Guide to SQL: Reference.
Examples of the Count(*) FunctionIn the following example, the user wants to know the total number of rows in the orders table. So the user uses the COUNT(*) function in a SELECT statement without a WHERE clause.
The following table shows the result of this query.
In the following example, the user wants to know how many rows in the orders table have a null value in the ship_instruct column. The user uses the COUNT(*) function in a SELECT statement with a WHERE clause, and specifies the IS NULL condition in the WHERE clause.
The following table shows the result of this query.
In the following example, the user wants to know how many rows in the orders table have the value express in the ship_instruct column. So the user specifies the COUNT (*) function in the select list and the equals (=) relational operator in the WHERE clause.
The following table shows the result of this query.
Examples of the COUNT column Function
In the following example the user wants to know how many non-null values are in the ship_instruct column of the orders table. The user enters the COUNT column function in the select list of the SELECT statement.
The following table shows the result of this query.
The user can also find out how many non-null values are in the ship_instruct column by including the ALL keyword in the parentheses that follow the COUNT keyword.
The following table shows that the query result is the same whether you include or omit the ALL keyword.
Examples of the COUNT DISTINCT Function
In the following example, the user wants to know how many unique non-null values are in the ship_instruct column of the orders table. The user enters the COUNT DISTINCT function in the select list of the SELECT statement.
The following table shows the result of this query.
The AVG function returns the average of all values in the specified column or expression. You can apply the AVG function only to number columns. If you use the DISTINCT keyword, the average (mean) is greater than only the distinct values in the specified column or expression. The query in the following example finds the average price of a helmet:
Nulls are ignored unless every value in the specified column is null. If every column value is null, the AVG function returns a null for that column.
The MAX function returns the largest value in the specified column or expression. Using the DISTINCT keyword does not change the results. The query in the following example finds the most expensive item that is in stock but has not been ordered:
Nulls are ignored unless every value in the specified column is null. If every column value is null, the MAX function returns a null for that column.
The MIN function returns the lowest value in the column or expression. Using the DISTINCT keyword does not change the results. The following example finds the least expensive item in the stock table:
Nulls are ignored unless every value in the specified column is null. If every column value is null, the MIN function returns a null for that column.
The SUM function returns the sum of all the values in the specified column or expression, as shown in the following example. If you use the DISTINCT keyword, the sum is for only distinct values in the column or expression.
Nulls are ignored unless every value in the specified column is null. If every column value is null, the SUM function returns a null for that column.
You cannot use the SUM function with a character column.
The RANGE function computes the range for a sample of a population. It computes the difference between the maximum and the minimum values, as follows:
You can apply the RANGE function to only numeric columns. The following query finds the range of ages for a population:
As with other aggregates, the RANGE function applies to the rows of a group when the query includes a GROUP BY clause, as shown in the following example:
Because DATE data types are stored internally as integers, you can use the RANGE function on columns of type DATE. When used with a DATE column, the return value is the number of days between the earliest and latest dates in the column.
Nulls are ignored unless every value in the specified column is null. If every column value is null, the RANGE function returns a null for that column.
 Important: All computations for the RANGE function are performed in 32-digit precision, which should be sufficient for many sets of input data. The computation, however, loses precision or returns incorrect results when all of the input data values have 16 or more digits of precision.
Important: All computations for the RANGE function are performed in 32-digit precision, which should be sufficient for many sets of input data. The computation, however, loses precision or returns incorrect results when all of the input data values have 16 or more digits of precision.
STDEV Function
The STDEV function computes the standard deviation for a population. It is the square root of the VARIANCE function.
You can apply the STDEV function only to numeric columns. The following query finds the standard deviation on a population:
As with the other aggregates, the STDEV function applies to the rows of a group when the query includes a GROUP BY clause, as shown in the following example:
Nulls are ignored unless every value in the specified column is null. If every column value is null, the STDEV function returns a null for that column.
Important: All computations for the STDEV function are performed in 32-digit precision, which should be sufficient for many sets of input data. The computation, however, loses precision or returns incorrect results when all of the input data values have 16 or more digits of precision.
Although DATE data is stored internally as an integer, you cannot use this function on columns of type DATE.
The VARIANCE function returns the population variance. It computes the following value:
In this formula, Xi is each value in the column and N is the total number of values in the column.
You can apply the VARIANCE function only to numeric columns.
The following query finds the variance on a population:
As with the other aggregates, the VARIANCE function applies to the rows of a group when the query includes a GROUP BY clause, as shown in the following example:
When you use the VARIANCE function, nulls are ignored unless every value in the specified column is null. If every column value is null, the VARIANCE function returns a null for that column. If the total number of values in the column is equal to one, the VARIANCE function returns a zero variance. If you want to omit this special case, you can adjust the query construction. For example, you might include a HAVING COUNT(*) > 1 clause.
Important: All computations for the VARIANCE function are performed in 32-digit precision, which should be sufficient for many sets of input data. The computation, however, loses precision or returns incorrect results when all of the input data values have 16 or more digits of precision.
Although DATE data is stored internally as an integer, you cannot use this function on columns of type DATE.
An example can help to summarize the behavior of the aggregate functions. Assume that the testtable table has a single INTEGER column that is named a_number. The contents of this table are as follows.
You can use aggregate functions to obtain different types of information about the a_number column and the testtable table. In the following example, the user specifies the AVG function to obtain the average of all the non-null values in the a_number column:
The following table shows the result of this query.
You can use the other aggregate functions in SELECT statements that are similar to the one shown in the preceding example. If you enter a series of SELECT statements that have different aggregate functions in the select list and do not have a WHERE clause, you receive the results that the following table shows.
Aggregate functions always return one row; if no rows are selected, the function returns a null. You can use the COUNT (*) function to determine whether any rows were selected, and you can use an indicator variable to determine whether any selected rows were empty. Fetching a row with a cursor associated with an aggregate function always returns one row; hence, 100 for end of data is never returned into the sqlcode variable for a first fetch attempt.
You can also use the GET DIAGNOSTICS statement for error checking.
You can create your own aggregate expressions with the CREATE AGGREGATE statement and then invoke these aggregates wherever you can invoke the built-in aggregates. The following diagram shows the syntax for invoking a user-defined aggregate.
.
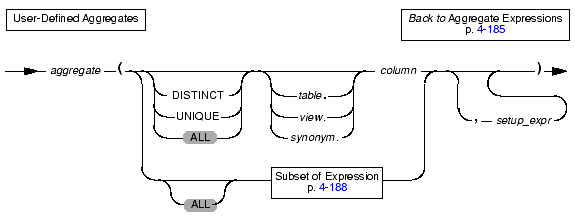
|
Use the DISTINCT or UNIQUE keywords to specify that the user-defined aggregate is to be applied only to unique values in the named column or expression. Use the ALL keyword to specify that the aggregate is to be applied to all values in the named column or expression. If you omit the DISTINCT, UNIQUE, and ALL keywords, ALL is the default value. For further information on the DISTINCT, UNIQUE, and ALL keywords, see Including or Excluding Duplicates in the Row Set.
When you specify a set-up expression, this value is passed to the INIT support function that was defined for the user-defined aggregate in the CREATE AGGREGATE statement.
In the following example, you apply the user-defined aggregate named my_avg to all values of the quantity column in the items table:
In the following example, you apply the user-defined aggregate named my_sum to unique values of the quantity column in the items table. You also supply the value 5 as a set-up expression. This value might specify that the initial value of the sum that my_avg will compute is 5.
For further information on user-defined aggregates, see CREATE AGGREGATE and the discussion of user-defined aggregates in Extending Informix Dynamic Server 2000.
For a discussion of expressions in the context of the SELECT statement, see the Informix Guide to SQL: Tutorial.
For discussions of column expressions, length functions, and the TRIM function, see the Informix Guide to GLS Functionality.