SQL Statements
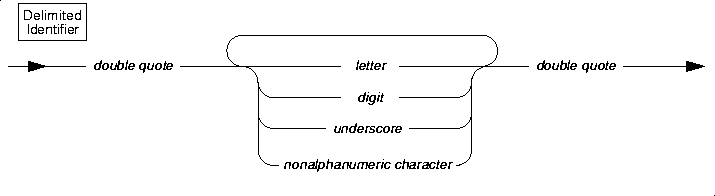
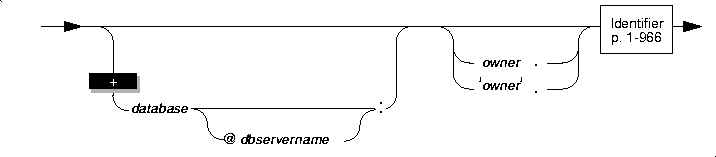
Identifier
An identifier specifies the simple name of a database object, such as a column, table, index, or view. Use the Identifier segment whenever you see a reference to an identifier in a syntax diagram.
Syntax
Usage
An identifier can contain up to 18 bytes, inclusive.
Use of Reserved Words as Identifiers
Although you can use almost any word as an identifier, syntactic ambiguities can result from using reserved words as identifiers in SQL statements. The statement might fail or might not produce the expected results. See "Potential Ambiguities and Syntax Errors" for a discussion of the syntactic ambiguities that can result from using reserved words as identifiers and an explanation of workarounds for these problems.
Delimited identifiers provide the easiest and safest way to use a reserved word as an identifier without causing syntactic ambiguities. No workarounds are necessary when you use a reserved word as a delimited identifier. See "Delimited Identifiers" for the syntax and usage of delimited identifiers.
ANSI-Reserved Words
The following list specifies all the ANSI-reserved words (that is, reserved words in the ANSI SQL standard).
You can flag identifiers as ANSI-reserved words by taking the following steps:
Support for Non-ASCII Characters in Identifiers
If you are using a nondefault locale, you can use any alphabetic character that your locale recognizes as a letter in an SQL identifier name. You can use a non-ASCII character as a letter as long as your locale supports it. This feature enables you to use non-ASCII characters in the names of database objects such as indexes, tables, and views. For a list of SQL identifiers that support non-ASCII characters, see the Guide to GLS Functionality. 
Delimited Identifiers
Delimited identifiers allow you to specify names for database objects that are otherwise identical to SQL reserved keywords, such as TABLE, WHERE, DECLARE, and so on. The only database object for which you cannot use delimited identifiers is database name.
Delimited identifiers are case sensitive.
Delimited identifiers are compliant with the ANSI standard.
Support for Nonalphanumeric Characters
You can use delimited identifiers to specify nonalphanumeric characters in the names of database objects. However, you cannot use delimited identifiers to specify nonalpha characters in the names of storage objects such as dbspaces and blobspaces.
Support for Non-ASCII Characters in Delimited Identifiers
When you are using a nondefault locale whose code set supports non-ASCII characters, you can specify non-ASCII characters in most delimited identifiers. The rule is that if you can specify non-ASCII characters in the undelimited form of the identifier, you can also specify non-ASCII characters in the delimited form of the same identifier. See the Guide to GLS Functionality for a list of identifiers that support non-ASCII characters and for information on non-ASCII characters in delimited identifiers.
Effect of DELIMIDENT Environment Variable
To use delimited identifiers, you must set the DELIMIDENT environment variable. When you set the DELIMIDENT environment variable, database objects in double quotes (") are treated as identifiers and database objects in single quotes (') are treated as strings. If the DELIMIDENT environment variable is not set, values within double quotes are also treated as strings.
If the DELIMIDENT variable is set, the SELECT statement in the following example must be in single quotes in order to be treated as a quoted string:
Examples of Delimited Identifiers
The following example shows how to create a table with a case-sensitive table name:
The following example shows how to create a table whose name includes a space character. If the table name were not in double quotes ("), you could not use a space character or any other nonalpha character except an underscore (_) in the name.
The following example shows how to create a table that uses a keyword as the table name:
Using Double Quotes Within a Delimited Identifier
If you want to include a double-quote (") within a delimited identifier, you must precede the double-quote (") with another double-quote ("), as shown in the following example:
Potential Ambiguities and Syntax Errors
Although you can use almost any word as an SQL identifier, syntactic ambiguities can occur. An ambiguous statement might not produce the desired results. The following sections outline some potential pitfalls and workarounds.
Using Functions as Column Names
The following two examples show a workaround for using a function as a column name in a SELECT statement. This workaround applies to the aggregate functions (AVG, COUNT, MAX, MIN, SUM) as well as the function expressions (algebraic, exponential and logarithmic, time, hex, length, dbinfo, trigonometric, and trim functions).
Using avg as a column name causes the following example to fail because the database server interprets avg as an aggregate function rather than as a column name:
If the DELIMIDENT environment variable is set, you could use avg as a column name as shown in the following example:
The workaround in following example removes ambiguity by including a table name with the column name:
If you use the keyword TODAY, CURRENT, or USER as a column name, ambiguity can occur, as shown in the following example:
The database server interprets user, current, and today in the SELECT statement as the SQL functions USER, CURRENT, and TODAY. Thus, instead of returning josh, 11:30:30,1/22/89, the SELECT statement returns the current user name, the current time, and the current date.
If you want to select the actual columns of the table, you must write the SELECT statement in one of the following ways:
Using Keywords as Column Names
Specific workarounds exist for using a keyword as a column name in a SELECT statement or other SQL statement. In some cases, there might be more than one suitable workaround.
Using ALL, DISTINCT, or UNIQUE as a Column Name
If you want to use the ALL, DISTINCT, or UNIQUE keywords as column names in a SELECT statement, you can take advantage of a workaround.
First, consider what happens when you try to use one of these keywords without a workaround. In the following example, using all as a column name causes the SELECT statement to fail because the database server interprets all as a keyword rather than as a column name:
You need to use a workaround to make this SELECT statement execute successfully. If the DELIMIDENT environment variable is set, you can use all as a column name by enclosing all in double quotes. In the following example, the SELECT statement executes successfully because the database server interprets all as a column name:
The workaround in the following example uses the keyword ALL with the column name all:
The rest of the examples in this section show workarounds for using the keywords UNIQUE or DISTINCT as a column name in a CREATE TABLE statement.
Using unique as a column name causes the following example to fail because the database server interprets unique as a keyword rather than as a column name:
The workaround shown in the following example uses two SQL statements. The first statement creates the column mycol; the second renames the column mycol to unique.
The workaround in the following example also uses two SQL statements. The first statement creates the column mycol; the second alters the table, adds the column unique, and drops the column mycol.
Using INTERVAL or DATETIME as a Column Name
The examples in this section show workarounds for using the keyword INTERVAL (or DATETIME) as a column name in a SELECT statement.
Using interval as a column name causes the following example to fail because the database server interprets interval as a keyword and expects it to be followed by an INTERVAL qualifier:
If the DELIMIDENT environment variable is set, you could use interval as a column name, as shown in the following example:
The workaround in the following example removes ambiguity by specifying a table name with the column name:
The workaround in the following example includes an owner name with the table name:
Using rowid as a Column Name
Every nonfragmented table has a virtual column named rowid. To avoid ambiguity, you cannot use rowid as a column name. Performing the following actions causes an error:
You can, however, use the term rowid as a table name.
Using Keywords as Table Names
The examples in this section show workarounds that involve owner naming when you use the keyword STATISTICS or OUTER as a table name. This workaround also applies to the use of STATISTICS or OUTER as a view name or synonym.
Using statistics as a table name causes the following example to fail because the database server interprets it as part of the UPDATE STATISTICS syntax rather than as a table name in an UPDATE statement:
The workaround in the following example specifies an owner name with the table name, to avoid ambiguity:
Using outer as a table name causes the following example to fail because the database server interprets outer as a keyword for performing an outer join:
The workaround in the following example uses owner naming to avoid ambiguity:
Workarounds That Use the Keyword AS
In some cases, although a statement is not ambiguous and the syntax is correct, the database server returns a syntax error. The preceding pages show existing syntactic workarounds for several situations. You can use the AS keyword to provide a workaround for the exceptions.
You can use the AS keyword in front of column labels or table aliases.
The following example uses the AS keyword with a column label:
The following example uses the AS keyword with a table alias:
Using AS with Column Labels
The examples in this section show workarounds that use the AS keyword with a column label. The first two examples show how you can use the keyword UNITS (or YEAR, MONTH, DAY, HOUR, MINUTE, SECOND, or FRACTION) as a column label.
Using units as a column label causes the following example to fail because the database server interprets it as a DATETIME qualifier for the column named mycol:
The workaround in the following example includes the AS keyword:
The following examples show how the AS or FROM keyword can be used as a column label.
Using as as a column label causes the following example to fail because the database server interprets as as identifying from as a column label and thus finds no required FROM clause:
The following example repeats the AS keyword:
Using from as a column label causes the following example to fail because the database server expects a table name to follow the first from:
The following example uses the AS keyword to identify the first from as a column label:
Using AS with Table Aliases
The examples in this section show workarounds that use the AS keyword with a table alias. The first pair shows how to use the ORDER, FOR, GROUP, HAVING, INTO, UNION, WITH, CREATE, GRANT, or WHERE keyword as a table alias.
Using order as a table alias causes the following example to fail because the database server interprets order as part of an ORDER BY clause:
The workaround in the following example uses the keyword AS to identify order as a table alias:
The following two examples show how to use the keyword WITH as a table alias.
Using with as a table alias causes the following example to fail because the database server interprets the keyword as part of the WITH CHECK OPTION syntax:
The workaround in the following example uses the keyword AS to identify with as a table alias:
The following two examples show how to use the keyword CREATE (or GRANT) as a table alias.
Using create as a table alias causes the following example to fail because the database server interprets the keyword as part of the syntax to create an entity such as a table, synonym, or view:
The workaround in the following example uses the keyword AS to identify create as a table alias:
Fetching Keywords as Cursor Names
In a few situations, no workaround exists for the syntactic ambiguity that occurs when a keyword is used as an identifier in an SQL program.
In the following example, the FETCH statement specifies a cursor named next. The FETCH statement generates a syntax error because the preprocessor interprets next as a keyword, signifying the next row in the active set and expects a cursor name to follow next. This error occurs whenever the keyword NEXT, PREVIOUS, PRIOR, FIRST, LAST, CURRENT, RELATIVE, or ABSOLUTE is used as a cursor name.
Using Keywords as Variable Names
If you use any of the following keywords as identifiers for variables in a routine, you can create ambiguous syntax.
Using CURRENT, DATETIME, INTERVAL, and NULL in INSERT
A routine cannot insert a variable using the CURRENT, DATETIME, INTERVAL, or NULL keyword as the name.
For example, if you define a variable called null, when you try to insert the value null into a column, you receive a syntax error, as shown in the following example:
Using NULL and SELECT in a Condition
If you define a variable with the name null or select, using it in a condition that uses the IN keyword is ambiguous. The following example shows three conditions that cause problems: in an IF statement, in a WHERE clause of a SELECT statement, and in a WHILE condition:
CREATE PROCEDURE problem()
.
.
.
DEFINE x,y,select, null, INT;
DEFINE pfname CHAR[15];
LET x = 3; LET select = 300;
LET null = 1;
IF x IN (select, 10, 12) THEN LET y = 1; -- problem if
IF x IN (1, 2, 4) THEN
SELECT customer_num, fname INTO y, pfname FROM customer
WHERE customer IN (select , 301 , 302, 303); -- problem in
WHILE x IN (null, 2) -- problem while
.
.
.
END WHILE;
You can use the variable select in an IN list if you ensure it is not the first element in the list. The workaround in the following example corrects the IF statement shown in the preceding example:
No workaround exists to using null as a variable name and attempting to use it in an IN condition.
Using ON, OFF, or PROCEDURE with TRACE
If you define a procedure variable called on, off, or procedure, and you attempt to use it in a TRACE statement, the value of the variable does not trace. Instead, the TRACE ON, TRACE OFF, or TRACE PROCEDURE statements execute. You can trace the value of the variable by making the variable into a more complex expression. The following example shows the ambiguous syntax and the workaround:
Using GLOBAL as a Variable Name
If you attempt to define a variable with the name global, the define operation fails. The syntax shown in the following example conflicts with the syntax for defining global variables:
If the DELIMIDENT environment variable is set, you could use global as a variable name, as shown in the following example:
Using EXECUTE, SELECT, or WITH as Cursor Names
Do not use an EXECUTE, SELECT, or WITH keyword as the name of a cursor. If you try to use one of these keywords as the name of a cursor in a FOREACH statement, the cursor name is interpreted as a keyword in the FOREACH statement. No workaround exists.
The following example does not work:
SELECT Statements in WHILE and FOR Statements
If you use a SELECT statement in a WHILE or FOR loop, and if you need to enclose it in parentheses, enclose the entire SELECT statement in a BEGIN...END block. The SELECT statement in the first WHILE statement in the following example is interpreted as a call to the procedure var1; the second WHILE statement is interpreted correctly:
The SET Keyword in the ON EXCEPTION Statement
If you use a statement that begins with the keyword SET inside the statement ON EXCEPTION, you must enclose it in a BEGIN...END block. The following list shows some of the SQL statements that begin with the keyword SET.
The following examples show incorrect and correct use of a SET LOCK MODE statement inside an ON EXCEPTION statement.
The following ON EXCEPTION statement returns an error because the SET LOCK MODE statement is not enclosed in a BEGIN...END block:
The following ON EXCEPTION statement executes successfully because the SET LOCK MODE statement is enclosed in a BEGIN...END block:
References
In the INFORMIX-Universal Server Administrator's Guide, see the owner-naming discussion.
In the Guide to GLS Functionality, see the discussion of identifiers that support non-ASCII characters and the discussion of non-ASCII characters in delimited identifiers.
Index Name
The Index Name segment specifies the name of an index. Use the Index Name segment whenever you see a reference to an index name in a syntax diagram.
Syntax
Usage
The actual name of the index is an SQL identifier.
If you are using a nondefault locale, you can use characters from the code set of your locale in the names of indexes. For more information, see the Guide to GLS Functionality.
If you are creating an index, the name must be unique within a database.
The owner.name combination is case sensitive. In an ANSI-compliant database, if you do not use quotes around the owner name, the name of the table owner is stored as uppercase letters. For more information, see the discussion of case sensitivity in ANSI-compliant databases on page 1-1049.
References
See the CREATE INDEX statement in this manual for information on defining indexes.
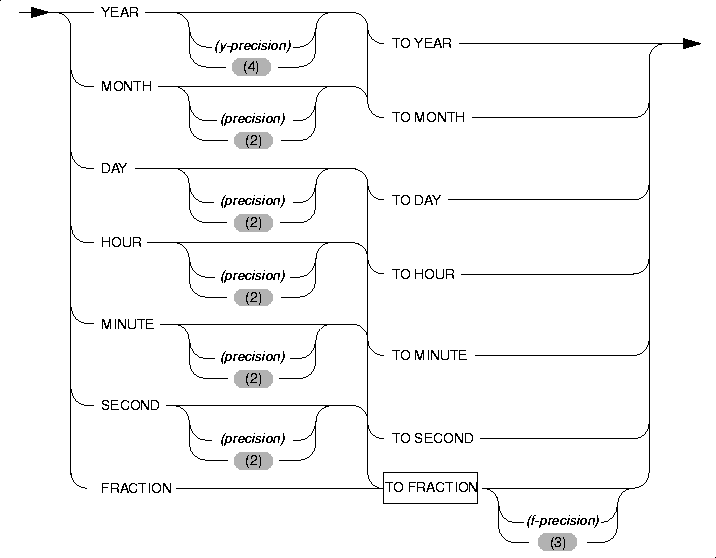
INTERVAL Field Qualifier
The INTERVAL field qualifier specifies the units for an INTERVAL value. Use the INTERVAL Field Qualifier segment whenever you see a reference to an INTERVAL field qualifier in a syntax diagram.
Syntax
Usage
The next two examples show INTERVAL data types of the YEAR TO MONTH type. The first example can hold an interval of up to 999 years and 11 months, because it gives 3 as the precision of the year field. The second example uses the default precision on the year field, so it can hold an interval of up to 9,999 years and 11 months.
When you want a value to contain only one field, the first and last qualifiers are the same. For example, an interval of whole years is qualified as YEAR TO YEAR or YEAR (5) TO YEAR, for an interval of up to 99,999 years.
The following examples show several forms of INTERVAL qualifiers:
References
In the Informix Guide to SQL: Syntax, see the INTERVAL data type in Chapter 2 for information about specifying INTERVAL field qualifiers and using INTERVAL data in arithmetic and relational operations.
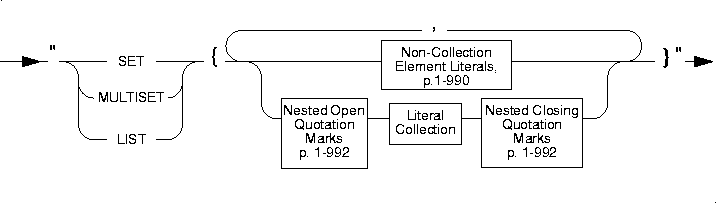
Literal Collection
The Literal Collection segment specifies the syntax for values of the collection data types: SET, LIST, and MULTISET.
Syntax
Usage
You can specify literal collection values for each of the collection data types: SET, MULTISET, or LIST. The entire literal collection value must be enclosed in quotes; each literal within the literal collection must also be enclosed in quotes, following the rule explained on page 1-992.
To specify a single literal-collection value, specify the collection type and the literal values. The following SQL statement inserts four integer values into the set_col column that is declared as SET(INT NOT NULL):
You specify an empty collection with a set of empty braces ({}). The following INSERT statement inserts an empty list into a collection column list_col that is declared as LIST(INT NOT NULL):
If the collection is a nested collection, you must include the collection-constructor syntax for each level of collection type. Suppose you define the following column:
The following statement inserts three elements into the nest_col column:
To learn how to use quotes in INSERT statements, see "Nested Quotation Marks".
Non-Collection Element Literal
Elements of a collection can be literal values for the following built-in data types:
The NCHAR and NVARCHAR data types also use quoted strings for literal values.
For more information, see the description of the BOOLEAN data type in the Informix Guide to SQL: Syntax.
Collection elements can also be literal values for the following user-defined data types:
When the collection element type is a named row type, you do not have to cast the values that you insert to the named row type.
A collection whose element type is another collection is called a nested collection. For information on literal collection value as a column value, see page 1-992. For information on a literal collection value as a collection-variable value, see page 1-992.
Nested Quotation Marks
Whenever you nest collection literals, you use nested quotation marks. In these cases, you must follow the rule for nesting quotation marks. Otherwise, the server cannot correctly parse the strings.
The general rule is that you must double the number of quotes for each new level of nesting. For example, if you use double quotes for the first level, you must use two double quotes for the second level, four double quotes for the third level, eight for the fourth level, sixteen for the fifth level, and so on. Likewise, if you use single quotes for the first level, you must use two single quotes for the second level and four single quotes for the third level.
There is no limit to the number of levels you can nest, as long as you follow this rule.
Example of Nested Quotation Marks
The following example illustrates the case for two levels of nested collection literals, using double quotes. Table tab5 is a one-column table whose column, set_col, is a nested collection type.
The following statement creates the tab5 table:
The following statement inserts values into the table tab5:
For any individual literal value, the opening quotation marks and the closing quotation marks must match. In other words, if you open a literal with two double quotes, you must close that literal with two double quotes
(""a literal value"").
The rules for nested quotation marks apply to all literals-collection literals and non-collection literals-that are nested in a single collection value.
To specify nested quotes within an SQL statement in an ESQL/C program, you use the C escape character for every double quote inside a single-quote string. Otherwise, the ESQL/C preprocessor cannot correctly interpret the literal collection value. For example, the preceding INSERT statement on the tab5 table would appear in an ESQL/C program as follows:
For more information, see the chapter on complex data types in the INFORMIX-ESQL/C Programmer's Manual.
References
See the INSERT, UPDATE, and SELECT statements in this manual. See also the Row Literal segment.
In the Informix Guide to SQL: Tutorial, see Chapter 10 and Chapter 12 for information about how to create and use collection data types.
In the Informix Guide to SQL: Syntax, see the SET, MULTISET, and LIST data types in Chapter 2.
In the Guide to GLS Functionality, see the discussion of customizing NCHAR and NVARCHAR data types.
Literal DATETIME
The Literal DATETIME segment specifies a literal DATETIME value. Use the Literal DATETIME segment whenever you see a reference to a literal DATETIME in a syntax diagram.
Syntax
Usage
You must specify both a numeric date and a DATETIME field qualifier for this date in the Literal DATETIME segment. The DATETIME field qualifier must correspond to the numeric date you specify. For example, if you specify a numeric date that includes a year as the largest unit and a minute as the smallest unit, you must specify YEAR TO MINUTE as the DATETIME field qualifier.
The following examples show literal DATETIME values:
The following example shows a literal DATETIME value used with the EXTEND function:
References
In the Informix Guide to SQL: Syntax, see the DATETIME data type in Chapter 2 and the DBCENTURY environment variable in Chapter 3.
In the Guide to GLS Functionality, see the discussion of customizing DATETIME values for a locale.
Literal INTERVAL
The Literal INTERVAL segment specifies a literal INTERVAL value. Use the Literal INTERVAL segment whenever you see a reference to a literal INTERVAL in a syntax diagram.
Syntax
Usage
The following examples show literal INTERVAL values:
References
In the Informix Guide to SQL: Syntax, see the INTERVAL data type in Chapter 2 for information about using INTERVAL data in arithmetic and relational operations.
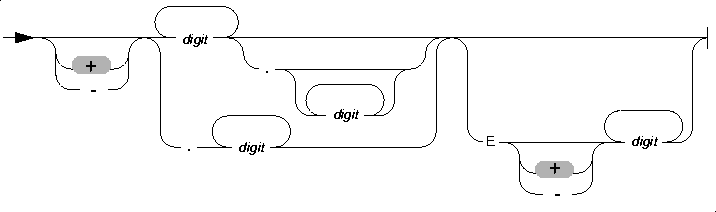
Literal Number
A literal number is an integer or noninteger (floating) constant. Use the Literal Number segment whenever you see a reference to a literal number in a syntax diagram.
Syntax
Usage
Literal numbers do not contain embedded commas; you cannot use a comma to indicate a decimal point. You can precede literal numbers with a plus or a minus sign.
Integers
Integers do not contain decimal points. The following examples show some integers:
Floating and Decimal Numbers
Floating and decimal numbers contain a decimal point and/or exponential notation. The following examples show floating and decimal numbers:
The digits to the right of the decimal point in these examples are the decimal portions of the numbers.
The E that occurs in two of the examples is the symbol for exponential notation. The digit that follows E is the value of the exponent. For example, the number 3E5 (or 3E+5) means 3 multiplied by 10 to the fifth power, and the number 3E-5 means 3 multiplied by 10 to the minus fifth power.
Literal Numbers and the MONEY Data Type
When you use a literal number as a MONEY value, do not precede it with a money symbol or include commas.
References
See the discussions of numeric data types, such as DECIMAL, FLOAT, INTEGER, and MONEY, in Chapter 2 of the Informix Guide to SQL: Syntax.
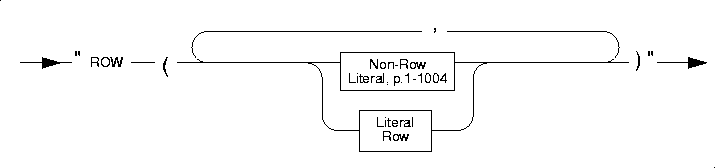
Literal Row
The Literal Row segment specifies the syntax for literal values of named row types and unnamed row types.
Syntax
Usage
You can specify literal values for named row types and unnamed row types. The literal row value is introduced with a ROW constructor. The entire literal row value must be enclosed in quotes.
The format of the value for each field of the row type must be compatible with the data type of the corresponding field.
Non-Row Literal Values
Literals of an Unnamed Row Type
To specify a literal value for an unnamed row type, introduce the literal row with the ROW constructor and enclose the values in parentheses. For example, suppose you define the rectangles table, as follows:
The following INSERT statement inserts values into the rect column of the rectangles table:
LIterals of a Named Row Type
To specify a literal value for a named row, type, introduce the literal row with the ROW type constructor and enclose the literal values for each field in parentheses. In addition, you can cast the row literal to the appropriate named row type to ensure that the row value is generated as a named row type. The following statements create the named row type address_t and the employee table:
The following INSERT statement inserts values into the address column of the employee table:
Literals for Nested Rows
If the literal value is for a nested row, specify the ROW type constructor for each row level. However only the outermost row is enclosed in quotes. For example, suppose you create the following emp_tab table:
The following INSERT statement adds a row to the emp_tab table:
Field-Level Literal Values
Fields of a row can be literal values for the following built-in data types:
The NCHAR and NVARCHAR data types also use quoted strings for literal values.
For more information, see the description of the BOOLEAN data type in Chapter 2 of the Informix Guide to SQL: Syntax.
Field values can also be literal values for the following user-defined data types:
For information on literal collection value as a column value, see page 1-992. For information on a literal collection value as a collection-variable value, see page 1-992.
A row with a field whose data type is another row is called a nested row.
References
See the INSERT, UPDATE, and SELECT statements in this manual. See the CREATE ROW TYPE statement for information on named row types. See "Constructor Expressions" of the Expression segment for information on ROW constructors. See also the Collection Literal segment.
Procedure Name
The Procedure Name segment specifies the name of a procedure.
Syntax
Usage
In a statement that calls for a Procedure Name, you can enter an identifier with an optional owner name, database name, and server name. The database and server names allow you to use a procedure stored on a remote database. A Procedure Name with a database name, server name, and owner name is called a fully qualified procedure name.
The actual name of the procedure is an SQL identifier.
The owner name is case sensitive. In an ANSI database, if you type quotation marks around the name, it is stored as you type it. If you do not use quotation marks, the name is stored as uppercase letters. For more information, see the discussion of case sensitivity in ANSI-compliant databases on page 1-1049.
If you are using a nondefault locale, you can use characters from the code set of your locale in the names of procedures. For more information, see the Guide to GLS Functionality.
Routine Overloading
Due to routine overloading, a procedure name does not need to be unique in Universal Server. You can define more than one procedure with the same name and different parameter lists.
Procedures are uniquely identified by their signature. A procedure's signature includes the following items:
If a procedure name is not unique, Universal Server uses routine resolution to identify the instance of the procedure to execute. For more information about routine resolution, see the Extending INFORMIX-Universal Server: User-Defined Routines manual.
Database Name and Server Name
When you add the database name and server name options, you use a fully qualified procedure name to specify a remote procedure. You can use those options when:
References
In this manual, see the CREATE FUNCTION, CREATE PROCEDURE, DROP FUNCTION, DROP PROCEDURE, DROP ROUTINE, EXECUTE FUNCTION, and EXECUTE PROCEDURE statements. See also the Function Name and Specific Name segments.
In the Informix Guide to SQL: Tutorial, see Chapter 14 for information about how to create and use SPL routines.
|