| Informix DataBlade API Programmer's Manual Writing a User-Defined Routine |
|
A C user-defined routine has access to the following types of memory:
The DataBlade API provides functions to manage these types of memory.
The DataBlade API provides memory-management functions to dynamically allocate memory in a C UDR. These functions allocate user memory, which is allocated from database server shared memory. Figure 12-14 shows the memory-management functions that the DataBlade API provides for memory operations on user memory.
Figure 12-14
| Default Memory Duration | Memory Operation | Function Name |
|---|---|---|
| Current memory duration | Constructor | mi_alloc(), mi_dalloc(), mi_zalloc() |
| Destructor | mi_free() |
 Tip: The DataBlade API memory-management functions execute in client LIBMI applications as well as C UDRs. For DataBlade API modules that you design to run in both client LIBMI applications and UDRs, use these memory-management functions. For information on the behavior of these functions in a client LIBMI application, see Appendix A, Writing a Client LIBMI Application.
Tip: The DataBlade API memory-management functions execute in client LIBMI applications as well as C UDRs. For DataBlade API modules that you design to run in both client LIBMI applications and UDRs, use these memory-management functions. For information on the behavior of these functions in a client LIBMI application, see Appendix A, Writing a Client LIBMI Application.
![]() Allocating User Memory
Allocating User Memory
To handle dynamic memory allocation of user memory, use one of the following DataBlade API memory-management functions.
Tip: The DataBlade API library also provides several private memory-management functions. These private functions are only available to DataBlade partners for special DataBlade functionality. For more information on private memory-management durations, see your Informix sales representative.
These DataBlade API memory-management functions work correctly with the transaction management and garbage collection of the database server. In particular, they provide the following advantages:
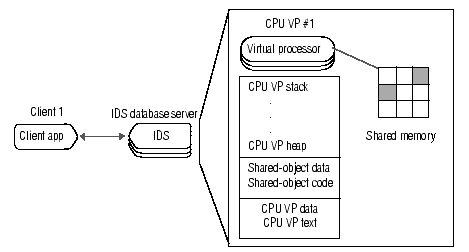
While a C UDR executes on a VP (VP #1), it can access memory that is part of that virtual process. Figure 12-15 shows a schematic representation of what a virtual processor that loads a shared-object file looks like internally.
However, if the UDR migrates to another VP, it no longer has access to any information in the memory space of VP #1. It can now only access the memory in the new VP (VP #2). The only memory that the UDR can access from both VP #1 and VP #2 is the database server shared memory. This restriction leads to the following guidelines for the dynamic memory allocation in a C UDR:
The DataBlade API memory-management functions allocate user memory from the shared memory of the database server. The database server organizes this shared memory into memory pools. Keeping related memory allocations in one pool helps to reduce memory fragmentation.
Tip: For more information about the use and structure of database server memory pools, see your Administrator's Guide.
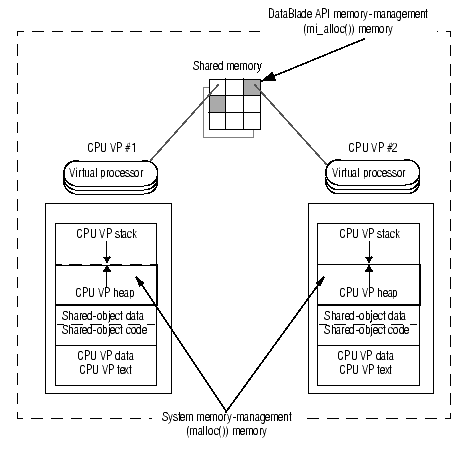
As Figure 12-16 shows, the DataBlade API memory-management functions (such as mi_alloc() and mi_dalloc()) allocate memory from shared memory, which remains accessible if a thread migrates to another virtual processor. The system memory-management functions (such as malloc() and free()) allocate memory in the heap space of the VP. If a thread migrates to another VP, it no longer has access to the heap space of the previous VP. Therefore, the address to dynamic memory in some variable is not valid while the UDR executes in the new VP.
A C UDR must allocate user memory from the shared memory of the database server, not from the memory of the virtual processor that runs the C UDR. Therefore, a C UDR must use the DataBlade API memory-management functions to manage user memory.
Determining Memory DurationA memory duration specifies the lifetime of the user memory. The DataBlade API memory-management functions allocate user memory from database server shared memory, which is organized into memory pools. Each memory duration has a separate memory pool.
When the database server calls a UDR, it creates a memory context. This context records all of the allocations that the UDR makes before the routine returns. The UDR might run for some time, calling other user-defined routines or DataBlade API functions. The database server automatically performs garbage collection on user memory based on its memory duration. When a particular memory duration expires, the database server marks the associated memory pool for deallocation.
In a C UDR, you can allocate shared memory with any of the public memory durations in Figure 12-17.
Figure 12-17
Tip: The DataBlade API memory-management functions also support several private memory durations. These private memory durations are only available to DataBlade module partners for special DataBlade module functionality. For more information on private memory durations, see your Informix sales representative.
These memory-duration constants are of type MI_MEMORY_DURATION. The memdur.h header file declares these memory-duration constants.
Make sure you choose a memory duration that is appropriate to the use of the user memory. An inappropriate memory duration can cause the following problems:
 Important: It is important to keep track of the scope and memory duration of the memory you allocate with the DataBlade API memory-management functions. Incorrect memory duration can create serious memory corruption.
Important: It is important to keep track of the scope and memory duration of the memory you allocate with the DataBlade API memory-management functions. Incorrect memory duration can create serious memory corruption.
The following sections provide additional information about each of the valid memory durations in Figure 12-17 on page 12-58.
Current Memory DurationThe current memory duration is the memory duration that applies when the mi_alloc() or mi_zalloc() function allocates memory. These functions do not specify a memory duration for their allocation. The default memory duration is PER_ROUTINE; that is, the database server marks the memory for garbage collection when the UDR completes. By default, the current memory duration is default memory duration. Therefore, the mi_alloc() and mi_zalloc() functions allocate memory with a duration of PER_ROUTINE by default.
Figure 12-18 shows the DataBlade API data structures that have a memory duration of the current memory duration.
Figure 12-18
You can change the current memory duration that these functions use with the mi_switch_mem_duration() function.
To increase the memory duration of a DataBlade API data structure, call the mi_switch_mem_duration() function with the desired duration before the DataBlade API function call that allocates the object. For more information, see Changing the Memory Duration.
Important: All the DataBlade API functions in Figure 12-18 allocate structures with the current memory duration. If you switch the current memory duration, you affect not only explicit allocations you make with mi_alloc() or mi_zalloc() but the memory allocations that these DataBlade API constructor functions do as well.
PER_ROUTINE Memory Duration
Memory that is allocated with the PER_ROUTINE memory duration has a duration of a single invocation of the UDR.
Tip: The two memory-duration constants PER_ROUTINE and PER_FUNCTION are synonyms for the same memory duration. PER_ROUTINE is the more current name.
The database server performs garbage collection on PER_ROUTINE memory when a single invocation of a UDR completes. At this time, the database server reclaims any PER_ROUTINE memory in the memory context that is marked with the PER_ROUTINE duration. This memory is actually freed on entry to the next routine invocation. The database server does not reclaim any memory in the memory context with a higher duration than PER_ROUTINE. Therefore, the PER_ROUTINE memory duration causes the database server to free memory automatically when a UDR invocation completes, if the UDR did not already free the memory.
The PER_ROUTINE memory duration is useful for user memory required for a single UDR invocation. A UDR cannot allocate memory, save a pointer to this memory in static space, and expect the pointer to be valid for the next routine invocation. To save information across invocations, use the function-state pointer of the MI_FPARAM structure. For more information, see Saving a User State.
The routine manager allocates memory with a PER_ROUTINE duration for UDR pass-by-reference arguments that are pass-by-reference and for the UDR return value.
The default memory duration is PER_ROUTINE. The current memory duration is initialized to this default memory duration. For more information, see Current Memory Duration.
PER_COMMAND Memory DurationMemory that is allocated with the PER_COMMAND memory duration has a duration of the current SQL command. An SQL command is an SQL statement (such as a subquery) that was initiated as part of the current client SQL statement. Examples of SQL commands include:
One client SQL statement might initiate several SQL commands, which the PREPARE statement or one of the DataBlade API execution functions executes. The database server marks any PER_COMMAND memory for garbage collection when the current SQL command completes.
For a query, an SQL command completes when the subquery finishes execution for one outer row of the outer query. The only exception to this rule is if this statement is a cursor statement (DECLARE, OPEN, FETCH, UPDATE...WHERE CURRENT OF or DELETE...WHERE CURRENT OF, CLOSE), in which case the database server frees the memory when the cursor closes. For a routine sequence, an SQL command completes when the routine instance is complete; that is, when every routine invocation in the routine sequence is complete.
The PER_COMMAND memory duration is useful for accumulating calculations, in iterator functions, and for initialization of expensive resources. To retain user state across a routine instance, a user-defined routine can allocate PER_COMMAND memory and store it in the MI_FPARAM structure. For example, if a UDR calculates a total, PER_ROUTINE memory would be available only for a single routine invocation; PER_COMMAND memory would be available for the entire routine instance, regardless of the number of invocations involved. For more information on the use of MI_FPARAM, see Saving a User State.
Figure 12-19 shows the DataBlade API data structures that have a memory duration of PER_COMMAND.
Figure 12-19
| DataBlade API Data Structure | DataBlade API Constructor Function |
DataBlade API Destructor Function |
|---|---|---|
| Connection descriptor (MI_CONNECTION) | mi_open() | mi_close() |
| Function descriptor (MI_FUNC_DESC) | mi_cast_get(), mi_func_desc_by_typeid(), mi_routine_get(), mi_routine_get_by_typeid(), mi_td_cast_get() | mi_routine_end() |
| Row structure (MI_ROW) | mi_row_create() | mi_row_free() |
| User-defined MI_FPARAM structure | mi_fparam_allocate(), mi_fparam_copy() | mi_fparam_free() |
Switching the current memory duration before one of these constructor functions does not have an effect on the memory duration of the allocated DataBlade API structure. To retain access to some of these DataBlade API data structures after the command completes, you must save them at the per-session level.
Tip: The DataBlade API supports the ability to save information at a per-session level. However, this ability is a controlled feature of the DataBlade API. For information on how to obtain more information on this feature, contact your Informix sales representative.
PER_STATEMENT Memory Duration
Memory that is allocated with the PER_STATEMENT memory duration has a duration of the current SQL statement. A statement is the entire SQL statement plus any SQL commands that the SQL statement initiates. Examples of SQL statements include:
One SQL statement might contain several SQL commands. If the statement does not contain any commands, the database server deallocates PER_STATEMENT memory at the same time it deallocates PER_COMMAND memory.
The database server marks any PER_STATEMENT shared memory for garbage collection when the current client SQL statement completes or when every routine sequence in the SQL statement is complete.
The PER_STATEMENT memory duration is useful for communication between UDRs, parallel execution, user-defined aggregates, named memory, and for memory allocations within an end-of-statement callback (if you have information to pass to the callback).
Figure 12-20 shows that the DataBlade API data structures have a memory duration of PER_STATEMENT.
Figure 12-20
| DataBlade API Data Structure | DataBlade API Constructor Function |
DataBlade API Destructor Function |
|---|---|---|
| Save-set structure (MI_CONNECTION) | mi_save_set_create() | mi_save_set_destroy() |
Switching the current memory duration before one of these constructor functions does not have an effect on the memory duration of the allocated DataBlade API structure. To retain access to some of these DataBlade API data structures after the command completes, you must save them at the per-session level.
Tip: The DataBlade API supports the ability to save information at a per-session level. However, this ability is a controlled feature of the DataBlade API. For information on how to obtain more information on this feature, contact your Informix sales representative.
Changing the Memory Duration
The PER_ROUTINE memory duration is the default protection on a region of database server shared memory. You can change the memory duration of user memory to another duration in either of the following ways:
Changing the current memory duration with mi_switch_mem_duration() has an effect on the memory durations of all DataBlade API data structures that Figure 12-18 on page 12-60 lists. It does not have an effect on the memory duration of DataBlade API data structures allocated at the PER_COMMAND (Figure 12-19 on page 12-63) and PER_STATEMENT (Figure 12-20 on page 12-64) durations.
The mi_switch_mem_duration() function returns the previous memory duration. You can use this return value to restore memory duration after performing some allocations at a different duration.
The following code fragment temporarily changes the current memory duration from PER_ROUTINE (the default) to PER_COMMAND:
In the preceding code fragment, the PER_COMMAND memory duration is in effect for the allocation of user memory that the call to mi_alloc() makes. Because the mi_new_var() function allocates a new varying-length structure in the current memory duration, this call to mi_new_var() allocates the varying-length structure with a PER_COMMAND duration. However, the mi_save_set_create() function does not allocate its save-set structure at the current memory duration. Therefore, the call to mi_save_set_create() still allocates its save-set structure with the PER_STATEMENT duration. The second call to mi_switch_mem_duration() restores the current memory duration to PER_ROUTINE.
The database server automatically performs garbage collection on the user memory that mi_alloc(), mi_dalloc(), and mi_zalloc() allocate. The memory duration of the user memory determines when the database server marks the memory for deallocation.
User memory remains valid until whichever of the following events occurs first:
A C UDR is not allowed to cache information from the database across transaction boundaries. Because the state of the database might change entirely when the current transaction commits, any cached information might be invalid. Therefore, UDRs must reinitialize any database state that they require when the next transaction begins. To enforce the policy of no caching across transactions, the database server automatically performs garbage collection of memory at transaction boundaries. In addition, the database server performs garbage collection when specified memory durations expire, usually when a UDR allocates and returns a value.
To conserve resources, use the mi_free() function to explicitly deallocate the user memory once your DataBlade API module no longer needs it. The mi_free() function is the destructor function for user memory.
Keep the following restrictions in mind about memory deallocation:
Memory leakage occurs when memory remains allocated after the structure that holds its address was deallocated. There is no way to access the memory once its address is gone. Therefore, the memory remains with no way to remove it. You can monitor use of memory that your UDR allocates (explicitly or implicitly) with the following options of the onstat utility:
Tip: You can use the -r option of onstat in conjunction with any of the options listed above to have onstat repeat the command every specified number of seconds.
Suppose that the onstat -g ses command produces the following sample output:
Suppose also that your DB-Access session is hooked to session 23 (the italicized line in the preceding sample output).
![]()
![]() You can determine the session identifier of the DB-Access session on a UNIX system with the following command:
You can determine the session identifier of the DB-Access session on a UNIX system with the following command:

You can now obtain information about memory-pool usage with the
-g mem option of onstat:
Suppose that the preceding onstat command generated the following sample output (some output lines are omitted for brevity):
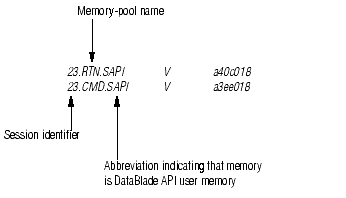
Figure 12-21 shows the lines of the onstat -g mem output that indicate user memory allocations.
Each memory duration has a separate memory pool. The three letters before "SAPI" identify each memory pool. The following table shows the memory-pool names for the public memory durations.
Tip: The onstat -g mem output also shows memory pools for the private memory durations. These private memory durations are only available to DataBlade partners for special DataBlade functionality. For more information on private memory durations, see your Informix sales representative.
Once you have determined a specific session identifier or memory-pool name that exhibits a problem, you can find out which specific kind of memory is affected with the -g ufr option of onstat. The -g ufr option of onstat shows memory fragments by usage. For example, the following onstat command captures a snapshot every 30 seconds of memory pools that session 23 uses:
Sample output for the preceding command follows:
In the preceding sample output, the main memory consumer is sqscb.
Any memory leakage from a DataBlade API function would show up in the memid column entry labelled sapi. For more information on the onstat command, see your Administrator's Reference.
Session threads execute C UDRs and their thread-stack space is allocated from a common region in shared memory. The thread stack stores nonshared data for the UDRs and system routines that the thread executes. This stack contains everything that would normally be on the execution stack, including the following:
Like all memory that UDRs use, stack segments can be overrun. The database server can only check for stack violations when the user-defined routine yields. Therefore, you must ensure that you perform the following tasks within a UDR:
To avoid stack overflow, follow these design restrictions in your UDR:
By default, when a thread of a virtual processor executes a UDR, the database server uses a thread-stack size that the STACKSIZE configuration parameter specifies (32 kilobytes, if STACKSIZE is not set). To determine how much stack space a UDR requires, monitor the UDR from the system prompt with the following onstat command:
The -g sts option prints the maximum and current stack usage per thread. For more information on the onstat utility and its -g sts option, see your Administrator's Reference.
You must ensure that your UDR has sufficient stack space for its execution. That is, the UDR must have enough stack space to hold all local variables of the routine. If you see errors in the message-log file of the following format when you try to allocate a large block of memory, your stack space is being overrun:
To override the stack size for a particular UDR, use the STACK routine modifier of the CREATE FUNCTION or CREATE PROCEDURE statement when you register your user-defined routine. For example, the following CREATE FUNCTION statement specifies a stack size of 64 kilobytes for the func1() UDR:
When the UDR completes, the database server allocates thread stacks for subsequent UDRs based on the STACKSIZE parameter (unless these subsequent UDRs have also specified the STACK routine modifier).
The DataBlade API provides the mi_call() function to dynamically manage stack space. This function performs the following tasks:
Use the mi_call() function to increase stack space for recursive UDRs.
Keep in mind that mi_call() does not know the size of the routine arguments. When mi_call() creates a new stack and copies the arguments onto this new stack, it assumes that each argument is the size of an MI_DATUM. If the data type of the routine argument is larger than an MI_DATUM, mi_call() does not copy all the argument bytes.
For example, consider a UDR that includes an mi_double argument.
![]()
![]() On a Sun Sparc system, an mi_double_precision argument takes the space of two long int values. Therefore, the mi_call() function pushes only half of the argument onto the new stack. Any arguments after the mi_double_precision might get garbled, and the last one might be truncated.
On a Sun Sparc system, an mi_double_precision argument takes the space of two long int values. Therefore, the mi_call() function pushes only half of the argument onto the new stack. Any arguments after the mi_double_precision might get garbled, and the last one might be truncated.
When you design UDRs that require use of mi_call(), make sure you use the correct passing mechanism for the argument data type. Pass all data types larger than MI_DATUM by reference. Examples of large data types include floating-point types (such as mi_real, mi_double_precision) and data structures.
The following example illustrates stack-space allocation with mi_call():
This code sample implements a factorial function. If the mi_call() function determines that there is sufficient stack space, the code recursively calls the handle_row() function to process the row value. The return value of the mi_call() function indicates whether mi_call() has allocated additional thread-stack memory, as follows.
The other mi_call() return values (MI_NOMEM and MI_TOOMANY) indicate error conditions. For these return values, the function uses the mi_db_error_raise() function to raise a database server exception and provide an error message.
The following CREATE FUNCTION registers the factorial() function:
The following EXECUTE FUNCTION invokes the factorial() function: