Advantages of data replication are as follows:
These advantages do not come without a cost. Data replication obviously requires more storage, and updating replicated data can take more processing time than updating a single object.
You could implement data replication in the logic of client applications by explicitly specifying where data must be updated. However, this method of achieving data replication is costly, prone to error, and difficult to maintain. Instead, the concept of data replication is often coupled with replication transparency. Replication transparency is built into a database server (instead of into client applications) to handle automatically the details of locating and maintaining data replicas.
When you configure a pair of database servers to use HDR, one database server is called the primary database server, and the other is called the secondary database server. (In this context, a database server that does not use HDR is referred to as a standard database server.)
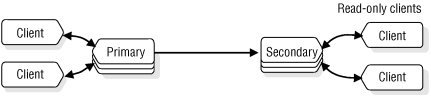
During normal operation, clients can connect to the primary database server and use it as they would an ordinary database server. Clients can also use the secondary database server during normal operation, but only to read data. The secondary database server does not permit updates from client applications.
As Figure 73 illustrates, the secondary database server is dynamically updated, with changes made to the data that the primary database server manages.
If one of the database servers in an HDR pair fails, as Figure 74 shows, you can redirect the clients that use that database server to the other database server in the pair.
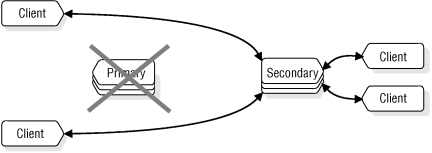
If a primary database server fails, you can change the secondary database server to a standard database server so that it can accept updates.
HDR has the following features:
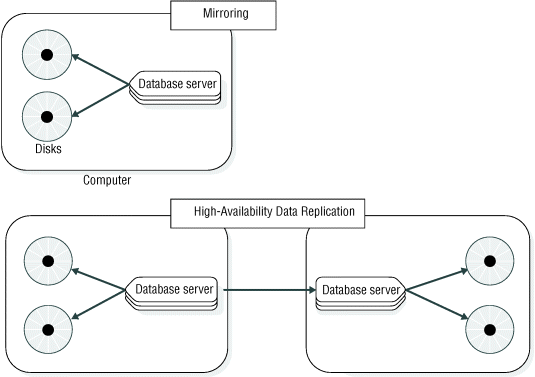
HDR and mirroring are both transparent ways of making the database server more fault tolerant. However, as Figure 75, shows, they are quite different.
Mirroring, described in Mirroring, is the mechanism by which a single database server maintains a copy of a specific dbspace on a separate disk. This mechanism protects the data in mirrored dbspaces against disk failure because the database server automatically updates data on both disks and automatically uses the other disk if one of the dbspaces fails.
On the other hand, HDR duplicates on an entirely separate database server all the data that a database server manages (not just specified dbspaces). Because HDR involves two separate database servers, it protects the data that these database servers manage, not just against disk failures, but against all types of database server failures, including a computer failure or the catastrophic failure of an entire site.
The two-phase commit protocol, described in detail in Multiphase Commit Protocols, ensures that transactions are uniformly committed or rolled back across multiple database servers.
In theory, you could take advantage of two-phase commit to replicate data by configuring two database servers with identical data and then defining triggers on one of the database servers that replicate updates to the other database server. However, this sort of implementation has numerous synchronization problems in different failure scenarios. Also, the performance of distributed transactions is inferior to HDR.
You can combine HDR with Enterprise Replication to create a robust replication system. HDR can ensure that an Enterprise Replication system remains fully connected by providing backup database servers for critical replication nodes.
When you combine HDR and Enterprise Replication, only the primary HDR server is connected to the Enterprise Replication system. The secondary HDR server does not participate in Enterprise Replication unless the primary HDR server fails.
For more information, see IBM Informix Dynamic Server Enterprise Replication Guide.
Home | [ Top of Page | Previous Page | Next Page | Contents | Index ]