| INFORMIX-ESQL/C Programmer's Manual Working with Complex Data Types of the Universal Data Option |
|
ESQL/C supports the SQL row types with the ESQL/C row type host variable. A row type is a complex data type that contains one or more members called fields. Each field has a name and a data type associated with it.
Informix Dynamic Server with Universal Data Option supports the following two kinds of row types:
For more information about row types, see the CREATE ROW TYPE statement in the Informix Guide to SQL: Syntax and the Informix Guide to SQL: Reference.
To access a column in a table that has a row type as its data type, perform the following steps:
The following sections describe each of these steps in more detail.
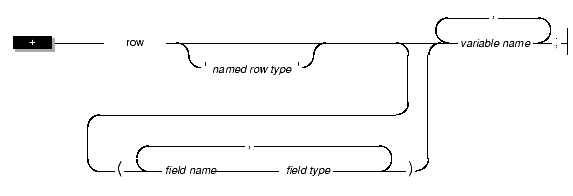
To declare a row host variable, use the following syntax.
|
ESQL/C supports the following two row variables:
ESQL/C handles row variables as client-side collection variables.
The Typed Row VariableA typed row variable specifies a field list, which contains the name and data type of each field in the row. Figure 9-8 shows declarations for three typed row variables.
Typed row variables can contain fields with the following data types:
When you specify the type of a field in the row variable, use SQL data types, not ESQL/C data types. For example, to declare a row variable with a field that holds small integers, use the SQL SMALLINT data type, not the ESQL/C int data type. Similarly, to declare a field whose values are character strings, use the SQL syntax for a CHAR column, not the C syntax for char variables. For example, the following declaration of the row_var host variable contains a field of small integers and a character field:
Use a typed row variable when you know the exact data type of the row-type column that you store in the row variable. Match the declaration of a typed row variable exactly with the data type of the row-type column. You can use this row variable directly in SQL statements such as INSERT, DELETE, or UPDATE. You can also use it in the collection-derived table clause.
You can declare several row variables in a single declaration line. However, all variables must have the same field types, as the following declaration shows:
If you do not know the exact data type of the row-type column you want to access, use an untyped row variable.
The Untyped Row VariableThe definition of an untyped row variable specifies only the row keyword and a name. The following lines declare three untyped row variables:
The advantage of an untyped row host variable is that it provides more flexibility in row definition. For an untyped row variable, you do not have to know the definition of the row-type column at compile time. Instead, you obtain, at runtime, a description of the row from a row-type column.
To obtain this description at runtime, execute a SELECT statement that retrieves the row-type column into the untyped row variable. When the database server executes the SELECT statement, it returns the data-type information for the row-type column (the types of the fields in the row) to the client application.
For example, suppose the a_row host variable is declared as an untyped row variable, as follows:
The following code fragment uses a SELECT statement to initialize the a_row variable with data-type information before it uses the row variable in an UPDATE statement:
The field name fld1, which refers to a field of :a_row, comes from the definition of the row column in the tab_row table.
For more information about the ALLOCATE ROW statement, see Managing Memory for Rows.
You can use the same untyped row variable to successively store different row types, but you must select the associated row-type column into the row variable for each new row type.
A named row type associates a name with the row structure. For a database you create a named row type with the CREATE ROW TYPE statement. If the database contains more than one row type with the same structure but with distinctly different names, the database server cannot properly enforce structural equivalence when it compares named row types. To resolve this ambiguity, specify a row-type name in the declaration of the row variable.
A named ESQL/C row variable can be typed or untyped.
The ESQL/C preprocessor does not check the validity of a row-type name and ESQL/C does not use this name at runtime. ESQL/C just sends this name to the database server to provide information for type resolution. Therefore, ESQL/C treats the a_row variable in the following declaration as an untyped row variable even though a row-type name is specified:
If you specify both the row-type name and a row structure in the declaration (a typed named row variable), the row-type name overrides the structure. For example, suppose the database contains the following definition of the address_t named row type:
In the following declaration, the another_row host variable has line1 and line2 fields of type CHAR(20) (from the address_t row type:), not CHAR(10) as the declaration specifies:
You cannot specify a named row type to declare a row variable that you use in a collection-derived table. ESQL/C does not have information about the named row type, only the database server does. For example, suppose your database has a named row type, r1, and a table, tab1, that are defined as follows:
To access this column, suppose you declare two row variables, as follows:
With these declarations, the following statement succeeds because ESQL/C has the information it needs about the structure of row1:
The following statement fails; however, because ESQL/C does not have the necessary information to determine the correct storage structure of the row2 row variable.
Similarly, the following statement also fails. In this case, ESQL/C treats r1 as a user-defined type instead of a named row type.
You can get around this restriction in either of the following ways:
An UPDATE statement that uses either the row2 or row2_untyped row variable in its collection-derived table clause can now execute successfully.
A row variable is sometimes called a client-side row. When you declare a row variable, you must declare the row variable name, allocate memory, and perform operations on the row.
To access the elements of a row variable, you specify the variable in the collection-derived table clause of a SELECT or UPDATE statement. When either of these statements contains a collection-derived table clause, ESQL/C performs the select or update operation on the row variable; it does not send these statements to the database server for execution. For example, ESQL/C executes the update operation on the row variable, a_row, that the following UPDATE statement specifies:
To access fields of a row type, you must use the SELECT or UPDATE statements with the collection-derived table clause.
For more information on the collection-derived table clause, see Accessing a Collection.
Once you declare a row variable, ESQL/C recognizes the variable name. For typed row variables, ESQL/C also recognizes the associated data type. However, ESQL/C does not automatically allocate or deallocate memory for row variables. You must explicitly manage memory that is allocated to a row variable. To manage memory for both typed and untyped row host variables, use the following SQL statements:
 Important: ESQL/C does not implicitly deallocate memory that you allocate with the ALLOCATE ROW statement. You must explicitly perform memory deallocation with the DEALLOCATE ROW statement.
Important: ESQL/C does not implicitly deallocate memory that you allocate with the ALLOCATE ROW statement. You must explicitly perform memory deallocation with the DEALLOCATE ROW statement.
The following code fragment declares the a_name host variable as a typed row, allocates memory for this variable, then deallocates memory for this variable:
For syn information for the ALLOCATE ROW and DEALLOCATE ROW statements, refer to their descriptions in the Informix Guide to SQL: Syntax.
The SELECT, and UPDATE statements allow you to access a row-type column as a whole.
An ESQL/C client application can access individual fields as follows:
 Important: You cannot use dot notation in a SELECT statement to access the fields of a nested row in a row variable.
Important: You cannot use dot notation in a SELECT statement to access the fields of a nested row in a row variable.
With a row host variable, you access a row-type column as a collection-derived table. The collection-derived table contains a single row in which each column is a field. A collection-derived table allows you to decompose a row into its fields and then access the fields individually.
The application first performs the operations on the fields through the row host variable. Once modifications are complete, the application can save the contents of the row variable into a row-type column of the database.
This section discusses the following topics on how to use a collection-derived table in an ESQL/C application to access a row-type column:
The collection-derived table clause allows you to create a collection-derived table from a row-type column. This clause has the following syntax:
The variable row_var is a row host variable. It can be either a typed or untyped row host variable but you must declare it beforehand.
For more information on the syn of the collection-derived table clause, see the description of the collection-derived table segment in the Informix Guide to SQL: Syntax.
Accessing a Row VariableYou can perform the following operations on the row host variable with the collection-derived table clause:
The insert and delete operations are not supported on row variables. For more information, see page 9-61 and page 9-64.
 Tip: If you only need to insert or update a row-type column with literal values, you do not need to use a row host variable. Instead, you can explicitly list the literal-row value in either the INTO clause of the INSERT statement or the SET clause of the UPDATE statement.
Tip: If you only need to insert or update a row-type column with literal values, you do not need to use a row host variable. Instead, you can explicitly list the literal-row value in either the INTO clause of the INSERT statement or the SET clause of the UPDATE statement.
For more information, see Inserting into and Updating Row-Type Columns.
Once the row host variable contains the values you want, update the row-type column with the contents of the host variable. For more information, see Accessing a Typed Table. For more information on the syn of the collection-derived table clause, see the description of the collection-derived table segment in the Informix Guide to SQL: Syntax.
Distinguishing Between Columns and Row VariablesWhen you use the collection-derived table clause with a SELECT or UPDATE statement, ESQL/C processes the statement. It does not send it to the database server. Therefore, some of the syntax checking that the database server performs is not done on SQL statements that include the collection-derived table clause.
In particular, the ESQL/C preprocessor cannot distinguish between column names and host variables. Therefore, when you use the collection-derived table clause with an UPDATE statement to modify a row host variable, the preprocessor does not check that you correctly specify host variables. You must ensure that you use valid host-variable syntax.
If you omit the host-variable symbol (colon (:) or dollar sign ($)), the preprocessor assumes that the name is a column name. For example, the following UPDATE statement omits the colon for the clob_ins host variable in the SET clause:
To perform operations on existing fields in a row-type column, you must first initialize the row variable with the field values. To perform this initialization, select the existing fields of the row-type column into a row variable with the SELECT statement, as follows:
Suppose you create the tab_unmrow and tab_nmrow tables with the statements in Figure 9-9.
The following code fragment initializes a typed row host variable called a_rect with the contents of the rectangle column in the row whose area column is 1234:
When you use a typed row host variable, the data types of the row-type column (the field types) must be compatible with the corresponding data types of the typed row host variable. The SELECT statement in the preceding code fragment successfully retrieves the rectangle column because the a_rect host variable has the same field types as the rectangle column.
The following SELECT statement fails because the data types of the fields in the emp_name column and the a_rect host variable do not match:
You can select any row into an untyped row host variable. The following code fragment uses an untyped row host variable to access the emp_name and rectangle columns that Figure 9-9 on page 9-60 defines:
Both SELECT statements in this code fragment can successfully retrieve row-type columns into the an_untyped_row host variable. However, ESQL/C does not perform type checking on an untyped row host variable because its elements do not have a predefined data type.
Once you have initialized the row host variable, you can use the collection-derived table clause to select or update existing fields in the row. For more information, see the following sections.
You cannot insert to a row variable using an INSERT statement. The row variable represents a single table row in the form of a collection-derived table. Each field in the row type is a like column in this virtual table. ESQL/C returns an error if you attempt to insert to a row variable.
You can, however, use the UPDATE statement to insert new field values into a row variable. For more information, see Updating a Row Variable.
The SELECT statement and the collection-derived table clause allow you to select a particular field or group of fields in the row variable. The INTO clause identifies the host variables that holds the field values selected from the row-type variable. The data type of the host variable in the INTO clause must be compatible with the field type.
For example, Figure 9-10 contains a code fragment that puts the value of the width field (in the row variable myrect) into the rect_width host variable.
The SELECT statement on a row variable (one that contains a collection-derived table clause) has the following restrictions:
If the row variable is a nested row, a SELECT statement cannot use dot notation to access the fields of the inner row. Instead, you must declare a row variable for each row type. The code fragment in Figure 9-11 shows how to access the fields of the inner row in the nested_row host variable.
The following SELECT statement is not valid to access the x and y fields of the nested_row variable because it uses dot notation:
An ESQL/C application can use dot notation to access fields of a nested row when a SELECT statement accesses a database column. For more information, see Selecting Fields of a Row Column,
The UPDATE statement and the collection-derived table clause allow you to update a particular field or group of fields in the row variable. You specify the new field values in the SET clause. An UPDATE of a field or fields in a row variable cannot include a WHERE clause.
For example, the following UPDATE changes the x and y fields in the myrect ESQL/C row variable:
You cannot use a row variable in the collection-derived table clause of an INSERT statement. However, you can use the UPDATE statement and the collection-derived table clause to insert new field values into a row host variable, as long as you specify a value for every field in the row. For example, the following code fragment inserts new field values into the row variable myrect and then inserts this row variable into the database:
A delete operation does not apply to a row variable because a delete normally removes a row from a table. The row variable represents the row-type value as a single table row in the collection-derived table. Each field in the row type is a column in this table. You cannot remove this single table row from the collection-derived table. Therefore, the DELETE statement does not support a row variable in the collection-derived table clause. ESQL/C returns an error if you attempt to perform a DELETE operation on a row variable.
However, you can use the UPDATE statement to delete existing field values in a row variable. For more information, see Deleting an Entire Row Type.
ESQL/C is case insensitive with regard to the field names of a row variable. In a SELECT or UPDATE statement, ESQL/C always interprets field names of a row variable as lowercase. For example, in the following SELECT statement, ESQL/C interprets the fields to select as x and y, even though the SELECT statement specifies them in uppercase:
This behavior is consistent with how the database server handles identifier names in SQL statements. To maintain the case of a field name, specify the field name as a delimited identifier. That is, surround the field name in double quotes and enable the DELIMIDENT environment variable before you compile the program.
ESQL/C interprets the fields to select as X and Y (uppercase) in the following SELECT statement (assuming the DELIMIDENT environment variable is enabled):
For more information on delimited identifiers and the DELIMIDENT environment variable, see SQL Identifiers.
Use Host Variable Field NamesIf the field names of the row column and the row variable are different, you must specify the field names of the row host variable. For example, if the last SELECT statement in the following example referenced field names x and y instead of the field names of a_row, it would generate a runtime error.
You can specify any of the following values for fields in a row variable:
For information on how to update field values into a row variable, see Updating a Row Variable. The following sections describe the values you can assign to an element in a row variable.
Literal Values as Field ValuesYou can use a literal value to specify a field value for a row variable. The literal values must have a data type that is compatible with the field type. For example, the following UPDATE statement specifies a literal integer as a field value for the length field of the myrect variable. See Updating a Row Variable for a description of myrect.
The following UPDATE statement updates the x- and y-coordinate fields of the myrect variable:
The following UPDATE statement updates a ROW(a INTEGER, b CHAR(5)) host variable called a_row2 with a quoted string:
The following UPDATE statement updates the nested_row host variable (which Figure 9-11 on page 9-63 defines) with a literal row:
 Important: The syntax of a literal row for a row variable is different from the syntax of a literal row for a row-type column. A row variable does not need to be a quoted string.
Important: The syntax of a literal row for a row variable is different from the syntax of a literal row for a row-type column. A row variable does not need to be a quoted string.
If you only need to insert or update the row-type column with literal values, you can list the literal values as a literal-row value in the INTO clause of the INSERT statement or the SET clause of the UPDATE statement.
For more information, see Inserting into and Updating Row-Type Columns.
Constructed RowsYou can use a constructed row to specify an expression as a field value for a row variable. The constructed expression must use a row constructor and evaluate to a data type that is compatible with the field type of the field. Suppose you have a nested-row variable that is declared as follows:
The following UPDATE statement uses the ROW constructor to specify expressions in the value for the fld2 field of the a_nested_row variable:
For more information on the syn of a row constructor, see the Expression segment in the Informix Guide to SQL: Syntax.
ESQL/C Host Variables as Field ValuesYou can use an ESQL/C host variable to specify a field value for a row variable. The host variable must be declared with a data type that is compatible with the data type of the field and must contain a value that is also compatible. For example, the following UPDATE statement uses a host variable to update a single value into the a_row variable.
To insert multiple values into a row variable, you can use an UPDATE statement for each value or you can specify all field values in a single UPDATE statement:
The following variation of the UPDATE statement performs the same task as the preceding UPDATE statement:
The following UPDATE statement updates the nested_row variable with a literal field value and a host variable:
You can use a row variable to access the columns of a typed table. A typed table is a table that was created with the OF TYPE clause of the CREATE TABLE statement. This table obtains the information for its columns from a named row type.
Suppose you create a typed table called names from the full_name named row type that Figure 9-9 on page 9-60 defines:
You can access a row of the names typed table with a row variable. The following code fragment declares a_name as a typed row variable and selects a row of the names table into this row variable:
The last SELECT statement accesses the lname field value of the :a_name row variable. For more information about typed tables, see the CREATE TABLE statement in the Informix Guide to SQL: Syntax and the Informix Guide to SQL: Tutorial.
The following example illustrates how you can also use an untyped row variable to access a row of an untyped table:
The row variable stores the fields of the row type. The row variable, however, has no intrinsic connection with a database column. You must use an INSERT or UPDATE statement to explicitly save the contents of the variable into the row type column.
You can use the SELECT, UPDATE, INSERT, and DELETE statements to access a row-type column (named or unnamed), as follows:
For more information on how to use these statements with row-type columns, see the Informix Guide to SQL: Tutorial.
The SELECT statement allows you to access a row-type column in the following ways:
To select all fields in a row-type column, specify the row-type column in the select list of the SELECT statement. To access these fields from an ESQL/C application, specify a row host variable in the INTO clause of the SELECT statement. For more information, see Initializing a Row Variable.
Selecting Fields of a Row ColumnYou can access an individual field in a row-type column with dot notation. Dot notation allows you to qualify an SQL identifier with another SQL identifier. You separate the identifiers with the period (.) symbol. The following SELECT statement performs the same task as the two SELECT statements in Figure 9-10 on page 9-62:
For more information on dot notation, see the Column Expression section of the Expression segment in the Informix Guide to SQL: Syntax.
The INSERT and UPDATE statements support row-type columns as follows:
In the VALUES clause of an INSERT statement or the SET clause of an UPDATE statement, the field values can be in any of the following formats:
To represent literal values for a row-type column, you specify a literal-row value. You create a literal-row value or a named or unnamed row type, introduce the value with the ROW keyword and provide the field values in a comma-separated list that is enclosed in parentheses. You surround the entire literal-row value with quotes (double or single). The following INSERT statement inserts the literal row of ROW(0, 0, 4, 5) into the rectangle column in the tab_unmrow table (that Figure 9-9 on page 9-60 defines):
The UPDATE statement in Figure 9-12 overwrites the SET values that the previous INSERT added to the tab_unmrow table.
 Important: If you omit the WHERE clause, the preceding UPDATE statement updates the rectangle column in all rows of the tab_unmrow table.
Important: If you omit the WHERE clause, the preceding UPDATE statement updates the rectangle column in all rows of the tab_unmrow table.
If any character value appears in this literal-row value, it too must be enclosed in quotes; this condition creates nested quotes. For example, a literal value for column row1 of row type ROW(id INTEGER, name CHAR(5), would be:
To specify nested quotes in an SQL statement in an ESQL/C program, you must escape every double quote when it appears in a single-quote string. The following two INSERT statements show how to use escape characters for inner quotes:
When you embed a double-quoted string inside another double-quoted string, you do not need to escape the inner-most quotation marks:
For more information on the syn of literal values for row variables, see Literal Values as Field Values. For more information on the syntax of literal-row values, see the Literal Row segment in the Informix Guide to SQL: Syntax.
If the row type contains a row type or a collection as a member, the inner row does not need quotes. For example, for column col2 whose data type is ROW(a INTEGER, b SET (INTEGER)), a literal value would be:
To delete all fields in a row-type column, specify the table, view, or synonym name after the FROM keyword of the DELETE statement and use the WHERE clause to identify the table row(s) that you want to delete.
The following DELETE statement deletes the row in the tab_unmrow table that contains the row type that the UPDATE statement in Figure 9-12 on page 9-72 saves: