| Informix Guide to SQL: Reference Data Types |
|
This section describes the data types that Informix database servers support.
The BLOB data type stores any kind of binary data in random-access chunks, called sbspaces. Binary data typically consists of saved spreadsheets, program-load modules, digitized voice patterns, and so on. The database server performs no interpretation on the contents of a BLOB column. A BLOB column can be up to 4 terabytes in length.
The term smart large object refers to BLOB and CLOB data types. Use the CLOB data type (see page 2-15) for random access to text data. For general information about BLOB and CLOB data types, see Smart Large Objects.
You can use the following SQL functions to perform some operations on a BLOB column:
For more information on these SQL functions, see the Informix Guide to SQL: Syntax.
No casts exist for BLOB data. Therefore, the database server cannot convert data of type BLOB to any other data type. Within SQL, you are limited to the equality (=) comparison operation for BLOB data. To perform additional operations, you must use one of the application programming interfaces (APIs) from within your client application.
You can insert data into BLOB columns in the following ways:
If you select a BLOB column using DB-Access, only the phrase SBlob value is returned; no actual value is displayed.
The BOOLEAN data type stores single-byte true/false type data. The following table gives internal and literal representations of the BOOLEAN data type.
| BOOLEAN Value |
Internal Representation |
Literal Representation |
|---|---|---|
| TRUE | \0 | 't' |
| FALSE | \1 | 'f' |
| NULL | Internal Use Only | NULL |
You can compare two BOOLEAN values to determine whether they are equal or not equal. You can also compare a BOOLEAN value to the Boolean literals 't' and 'f'. BOOLEAN values are case insensitive; 't' is equivalent to 'T' and 'f' to 'F'.
You can use a BOOLEAN column to capture the results of an expression. In the following example, the value of boolean_column is 't' if column1 is less than column2, 'f' if column1 is greater than or equal to column2, and null if the value of either column1 or column2 is unknown:
The BYTE data type stores any kind of binary data in an undifferentiated byte stream. Binary data typically consists of saved spreadsheets, program load modules, digitized voice patterns, and so on.
The term simple large object is used to refer to BYTE and text data types.
The BYTE data type has no maximum size. A BYTE column has a theoretical limit of 231 bytes and a practical limit that your disk capacity determines.
You can store, retrieve, update, or delete the contents of a BYTE column. However, you cannot use BYTE data items in arithmetic or string operations or assign literals to BYTE items with the SET clause of the UPDATE statement. You also cannot use BYTE items in any of the following ways:
You can use BYTE objects in a Boolean expression only if you are testing for null values.
You can insert data into BYTE columns in the following ways:
You cannot use a quoted text string, number, or any other actual value to insert or update BYTE columns.
When you select a BYTE column, you can choose to receive all or part of it. To retrieve it all, use the regular syntax for selecting a column. You can also select any part of a BYTE column by using subscripts, as the following example shows:
This statement reads the first 75 bytes of the cat_picture column associated with the catalog number 10001.
The database server provides a cast to convert BYTE values to BLOB values. For more information, see the Informix Guide to Database Design and Implementation.
If you select a BYTE column using the DB-Access Interactive Schema Editor, only the phrase "BYTE value" is returned; no actual value is displayed.
 Important: If you try to return a BYTE column from a subquery, you get an error message even when the BYTE column is not used in a comparison condition or with the IN predicate.
Important: If you try to return a BYTE column from a subquery, you get an error message even when the BYTE column is not used in a comparison condition or with the IN predicate.
CHAR(n)
The CHAR data type stores any sequence of letters, numbers, and symbols. It can store single-byte and multibyte characters, based on what the chosen locale supports. For more information on multibyte CHARs, see Multibyte Characters with CHAR.
A character column has a maximum length n bytes, where 1 £ n £ 32,767. If you do not specify n, CHAR(1) is assumed. Character columns typically store names, addresses, phone numbers, and so on.
Because the length of this column is fixed, when a character value is retrieved or stored, exactly n bytes of data are transferred. If the character string is shorter than n bytes, the string is extended with spaces to make up the length. If the string value is longer than n bytes, the string is truncated, without the database server raising an exception.
If you plan to perform calculations on numbers stored in a column, you should assign a number data type to that column. Although you can store numbers in CHAR columns, you might not be able to use them in some arithmetic operations. For example, if you insert the sum of values into a character column, you might experience overflow problems if the character column is too small to hold the value. In this case, the insert fails. However, numbers that have leading zeros (such as some zip codes) have the zeros stripped if they are stored as number types INTEGER or SMALLINT. Instead, store these numbers in CHAR columns.
CHAR values are compared to other CHAR values by taking the shorter value and padding it on the right with spaces until the values have equal length. Then the two values are compared for the full length. Comparisons use the code-set collation order.
A CHAR value can include tabs, spaces, and other nonprintable characters. However, you must use an application to insert the nonprintable characters into host variables and to insert the host variables into your database. After passing nonprintable characters to the database server, you can store or retrieve the characters. When you select nonprintable characters, fetch them into host variables and display them with your own display mechanism.
The only nonprintable character that you can enter and display with DB-Access is a tab. If you try to display other nonprintable characters with DB-Access, your screen returns inconsistent results.
![]() The collation order of the CHAR data type depends on the code set. That is, this data is sorted by the order of characters as they appear in the code set. For more information, see the Informix Guide to GLS Functionality.
The collation order of the CHAR data type depends on the code set. That is, this data is sorted by the order of characters as they appear in the code set. For more information, see the Informix Guide to GLS Functionality.
![]() The database locale must support the multibyte characters that a database uses. If you are storing multibyte characters, make sure to calculate the number of bytes needed. For more information on multibyte characters and locales, see the Informix Guide to GLS Functionality.
The database locale must support the multibyte characters that a database uses. If you are storing multibyte characters, make sure to calculate the number of bytes needed. For more information on multibyte characters and locales, see the Informix Guide to GLS Functionality.
The CHARACTER data type is a synonym for CHAR.
The CHARACTER VARYING data type stores any multibyte string of letters, numbers, and symbols of varying length, where m is the maximum size of the column and r is the minimum amount of space reserved for that column.
The CHARACTER VARYING data type complies with ANSI standards; the non-ANSI Informix VARCHAR data type supports the same functionality. See the description of the VARCHAR data type on page 2-46.
The CLOB data type stores any kind of text data in random-access chunks, called sbspaces. Text data can include text-formatting information as long as this information is also textual, such as PostScript, Hypertext Markup Language (HTML), or Standard Graphic Markup Language (SGML) data.
The term smart large object refers to CLOB and BLOB data types. The CLOB data type includes special operations for character strings that are inappropriate for BLOB values. A CLOB column can be up to 4 terabytes in length.
Use the BLOB data type (see page 2-9) for random access to binary data. For general information about the CLOB and BLOB data types, see Smart Large Objects.
You can use the following SQL functions to perform some operations on a CLOB column:
For more information on these SQL functions, see the Informix Guide to SQL: Syntax.
No casts exist for CLOB data. Therefore, the database server cannot convert data of the CLOB type to any other data type. Within SQL, you are limited to the equality (=) comparison operation for CLOB data. To perform additional operations, you must use one of the application programming interfaces from within your client application.
You can insert data into CLOB columns in the following ways:
For more information and examples for using the CLOB data type, see the Informix Guide to SQL: Tutorial and the Informix Guide to Database Design and Implementation.
![]() With GLS, the following rules apply:
With GLS, the following rules apply:
For more information on database locales, collation order, and codeset conversion, see the Informix Guide to GLS Functionality. 
The DATE data type stores the calendar date. DATE data types require 4 bytes. A calendar date is stored internally as an integer value equal to the number of days since December 31, 1899.
Because DATE values are stored as integers, you can use them in arithmetic expressions. For example, you can subtract a DATE value from another DATE value. The result, a positive or negative INTEGER value, indicates the number of days that elapsed between the two dates.
The following example shows the default display format of a DATE column:
In this example, mm is the month (1-12), dd is the day of the month (1-31), and yyyy is the year (0001-9999). For the month, Informix products accept a number value 1 or 01 for January, and so on. For the day, Informix products accept a value 1 or 01 that corresponds to the first day of the month, and so on.
If you enter only a two-digit value for the year, how Informix products fill in the century digits depends on how you set the DBCENTURY environment variable. For example, if you enter the year value as 99, whether that year value is interpreted as 1999 or 2099 depends on the setting of your DBCENTURY environment variable. If you do not set the DBCENTURY environment variable, then your Informix products consider the present century as the default. For information on how to set the DBCENTURY environment variable, refer to page 3-33.
![]() If you specify a locale other than the default locale, you can display culture-specific formats for dates. The locales and the GL_DATE and DBDATE environment variables affect the display formatting of DATE values. They do not affect the internal format used in a DATE column of a database. To change the default DATE format, set the DBDATE or GL_DATE environment variable. GLS functionality permits the display of international DATE formats. For more information, see the Informix Guide to GLS Functionality.
If you specify a locale other than the default locale, you can display culture-specific formats for dates. The locales and the GL_DATE and DBDATE environment variables affect the display formatting of DATE values. They do not affect the internal format used in a DATE column of a database. To change the default DATE format, set the DBDATE or GL_DATE environment variable. GLS functionality permits the display of international DATE formats. For more information, see the Informix Guide to GLS Functionality. 
The DATETIME data type stores an instant in time expressed as a calendar date and time of day. You choose how precisely a DATETIME value is stored; its precision can range from a year to a fraction of a second.
The DATETIME data type is composed of a contiguous sequence of fields that represents each component of time that you want to record and uses the following syntax:
The largest_qualifier and smallest_qualifier can be any one of the fields that Figure 2-4 on page 2-18 lists.
Figure 2-4
A DATETIME column does not need to include all fields from YEAR to FRACTION; it can include a subset of fields or even a single field. For example, you can enter a value of MONTH TO HOUR in a column that is defined as YEAR TO MINUTE, as long as each entered value contains information for a contiguous sequence of fields. You cannot, however, define a column for just MONTH and HOUR; this entry must also include a value for DAY.
If you use the DB-Access TABLE menu, and you do not specify the DATETIME qualifiers, the default DATETIME qualifier, YEAR TO YEAR, is assigned.
A valid DATETIME literal must include the DATETIME keyword, the values to be entered, and the field qualifiers. You must include these qualifiers because, as noted earlier, the value you enter can contain fewer fields than defined for that column. Acceptable qualifiers for the first and last fields are identical to the list of valid DATETIME fields that Figure 2-4 lists.
Write values for the field qualifiers as integers and separate them with delimiters. Figure 2-5 lists the delimiters that are used with DATETIME values in the U.S. ASCII English locale.
Figure 2-5
Figure 2-6 shows a DATETIME YEAR TO FRACTION(3) value with
delimiters.
When you enter a value with fewer fields than the defined column, the value that you enter is expanded automatically to fill all the defined fields. If you leave out any more significant fields, that is, fields of larger magnitude than any value that you supply, those fields are filled automatically with the current date. If you leave out any less-significant fields, those fields are filled with zeros (or a 1 for MONTH and DAY) in your entry.
You can also enter DATETIME values as character strings. However, the character string must include information for each field defined in the DATETIME column. The INSERT statement in the following example shows a DATETIME value entered as a character string:
In this example, the call_dtime column is defined as DATETIME YEAR TO MINUTE. This character string must include values for the year, month, day, hour, and minute fields. If the character string does not contain information for all defined fields (or adds additional fields), the database server returns an error.
All fields of a DATETIME column are two-digit numbers except for the year and fraction fields. The year field is stored as four digits. When you enter a two-digit value in the year field, how the century digits are filled in and interpreted depends on the value that you assign to the DBCENTURY environment variable.
For example, if you enter 99 as the year value, whether the year is interpreted as 1999 or 2099 depends on the setting of the DBCENTURY environment variable. If you do not set the DBCENTURY environment variable, then your Informix products consider the present century to be the default. For information on how to set and use the DBCENTURY environment variable, see page 3-33.
The fraction field requires n digits where 1 £ n £ 5, rounded up to an even number. You can use the following formula (rounded up to a whole number of bytes) to calculate the number of bytes that a DATETIME value requires:
For example, a YEAR TO DAY qualifier requires a total of eight digits (four for year, two for month, and two for day). This data value requires 5, or (8/2) + 1, bytes of storage.
For information on how to use DATETIME data in arithmetic and relational expressions, see Manipulating DATE with DATETIME and INTERVAL Values. For more information on the DATETIME data type, see the Informix Guide to SQL: Syntax and the Informix Guide to GLS Functionality.
![]() If you specify a locale other than U.S. ASCII English, the locale defines the culture-specific display formats for DATETIME values. To change the default display format, change the setting of the GL_DATETIME environment variable.
If you specify a locale other than U.S. ASCII English, the locale defines the culture-specific display formats for DATETIME values. To change the default display format, change the setting of the GL_DATETIME environment variable.
With an ESQL API, the DBTIME environment variable also affects DATETIME formatting. Locales and the GL_DATE and DBDATE environment variables affect the display of datetime data. They do not affect the internal format used in a DATETIME column.
For information on how the USEOSTIME configuration parameter can affect the subsecond granularity when the database server obtains the current time from the operating system for SQL statements, see the Administrator's Reference.
For more information on DBTIME, see page 3-54. For more information on locales and GLS environment variables, see the Informix Guide to GLS Functionality.
The DEC data type is a synonym for DECIMAL.
The DECIMAL data type can take two forms: DECIMAL(p) floating point and DECIMAL(p,s) fixed point. In an ANSI-compliant database, all DECIMAL numbers are fixed point.
The DECIMAL data type stores decimal floating-point numbers up to a maximum of 32 significant digits, where p is the total number of significant digits (the precision). Specifying precision is optional. If you do not specify the precision (p), DECIMAL is treated as DECIMAL(16), a floating decimal with a precision of 16 places. DECIMAL(p) has an absolute exponent range between 10-130 and 10124.
If you use an ANSI-compliant database and specify DECIMAL(p), the value defaults to DECIMAL(p, 0). For more information about fixed-point decimal values, see the following discussion.
In fixed-point numbers, DECIMAL(p,s), the decimal point is fixed at a specific place, regardless of the value of the number. When you specify a column of this type, you write its precision (p) as the total number of digits that it can store, from 1 to 32. You write its scale (s) as the total number of digits that fall to the right of the decimal point.
All numbers with an absolute value less than 0.5*10-s have the value zero. The largest absolute value of a variable of this type that you can store without an error is 10p-s -10-s. A DECIMAL data type column typically stores numbers with fractional parts that must be stored and displayed exactly (for example, rates or percentages). In an ANSI-compliant database, all DECIMAL numbers must be in the range 10-32 to 10+31.
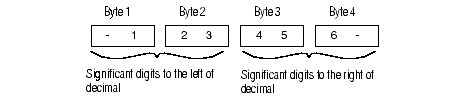
The database server uses 1 byte of disk storage to store two digits of a decimal number. The database server uses an additional byte to store the exponent and sign. The significant digits to the left of the decimal and the significant digits to the right of the decimal are stored on separate groups of bytes. The way the database server stores decimal numbers is best illustrated with an example.
If you specify DECIMAL(6,3), the data type consists of three significant digits to the left of the decimal and three significant digits to the right of the decimal (for instance, 123.456). The three digits to the left of the decimal are stored on 2 bytes (where one of the bytes only holds a single digit) and the three digits to the right of the decimal are stored on another 2 bytes, as Figure 2-7 illustrates. (The exponent byte is not shown.) With the additional byte required for the exponent and sign, this data type requires a total of 5 bytes of storage.
You can use the following formulas (rounded down to a whole number of bytes) to calculate the byte storage (N) for a decimal data type (N includes the byte required to store the exponent and sign):
For example, the data type DECIMAL(5,3) requires 4 bytes of storage (9/2 rounded down equals 4).
One caveat to these formulas exists. The maximum number of bytes the database server uses to store a decimal value is 17. One byte is used to store the exponent and sign leaving 16 bytes to store up to 32 digits of precision. If you specify a precision of 32 and an odd scale, however, you lose 1 digit of precision. Consider, for example, the data type DECIMAL(32,31). This decimal is defined as 1 digit to the left of the decimal and 31 digits to the right. The 1 digit to the left of the decimal requires 1 byte of storage. This leaves only 15 bytes of storage for the digits to the right of the decimal. The 15 bytes can accommodate only 30 digits, so 1 digit of precision is lost.
A distinct type is a data type that is based on one of the following source types:
A distinct type inherits the casts and functions of its source types as well as the length and alignment on the disk. A distinct type thus makes efficient use of the pre-existing functionality of the database server.
When you create a distinct data type, the database server automatically creates two explicit casts: one cast from the distinct type to its source type and one cast from the source type to the distinct type. A distinct type of a built-in type does not inherit the built-in casts that are provided for the built-in type. However, a distinct type does inherit any user-defined casts that have been defined on the source type.
A distinct type and a source type cannot be compared directly. To compare a distinct type and its source type, you must explicitly cast one type to the other.
You must define a distinct type in the database. Definitions for distinct types are stored in the sysxtdtypes system catalog table.
The following SQL statements maintain the definitions of distinct types in the database:
For more information on the SQL statements mentioned above, see the Informix Guide to SQL: Syntax. For information about casting distinct data types, see Casts for Distinct Types. For examples that show how to create and register cast functions for a distinct type, see the Informix Guide to Database Design and Implementation.
Columns defined as DOUBLE PRECISION behave the same as those defined as FLOAT.
The FLOAT data type stores double-precision floating-point numbers with up to 16 significant digits. FLOAT corresponds to the double data type in C. The range of values for the FLOAT data type is the same as the range of values for the C double data type on your computer.
You can use n to specify the precision of a FLOAT data type, but SQL ignores the precision. The value n must be a whole number between 1 and 14.
A column with the FLOAT data type typically stores scientific numbers that can be calculated only approximately. Because floating-point numbers retain only their most significant digits, the number that you enter in this type of column and the number the database server displays can differ slightly.
The difference between the two values depends on how your computer stores floating-point numbers internally. For example, you might enter a value of 1.1000001 into a FLOAT field and, after processing the SQL statement, the database server might display this value as 1.1. This situation occurs when a value has more digits than the floating-point number can store. In this case, the value is stored in its approximate form with the least significant digits treated as zeros.
FLOAT data types usually require 8 bytes per value.
Conversion of a FLOAT value to a DECIMAL value results in 17 digits of precision.
The INT data type is a synonym for INTEGER.
The INT8 data type stores whole numbers that range from -9,223,372,036,854,775,807 to 9,223,372,036,854,775,807 [or -(263-1) to 263-1]. The maximum negative number (-9,223,372,036,854,775,808) is a reserved value and cannot be used. The INT8 data type is typically used to store large counts, quantities, and so on.
The way that the database server stores the INT8 data is platform dependent. On 64-bit platforms, INT8 is stored as a signed binary integer; the data type requires 8 bytes per value. On 32-bit platforms, the database server uses an internal format that consists of several integer values; the data type can require 10 bytes.
Arithmetic operations and sort comparisons are performed more efficiently on integer data than on float or decimal data. However, INT8 columns can store only a limited range of values. If the data value exceeds the numeric range, the database server does not store the value.
The INTEGER data type stores whole numbers that range from -2,147,483,647 to 2,147,483,647. The maximum negative number, -2,147,483,648, is a reserved value and cannot be used. The INTEGER data type is stored as a signed binary integer and is typically used to store counts, quantities, and so on.
Arithmetic operations and sort comparisons are performed more efficiently on integer data than on float or decimal data. However, INTEGER columns can store only a limited range of values. If the data value exceeds the numeric range, the database server does not store the value.
INTEGER data types require 4 bytes per value.
The INTERVAL data type stores a value that represents a span of time. INTERVAL types are divided into two classes: year-month intervals and day-time intervals. A year-month interval can represent a span of years and months, and a day-time interval can represent a span of days, hours, minutes, seconds, and fractions of a second.
An INTERVAL value is always composed of one value, or a contiguous sequence of values, that represents a component of time. The following example defines an INTERVAL data type:
In this example, the largest_qualifier and smallest_qualifier fields are taken from one of the two INTERVAL classes, as Figure 2-8 shows, and n optionally specifies the precision of the largest field (and smallest field if it is a FRACTION).
Figure 2-8
As with a DATETIME column, you can define an INTERVAL column to include a subset of the fields that you need; however, because the INTERVAL data type represents a span of time that is independent of an actual date, you cannot combine the two INTERVAL classes. For example, because the number of days in a month depends on which month it is, a single INTERVAL data value cannot combine months and days.
A value entered into an INTERVAL column need not include all fields contained in the column. For example, you can enter a value of HOUR TO SECOND into a column defined as DAY TO SECOND. However, a value must always consist of a contiguous sequence of fields. In the previous example, you cannot enter just HOUR and SECOND values; you must also include MINUTE values.
A valid INTERVAL literal contains the INTERVAL keyword, the values to be entered, and the field qualifiers. (See the discussion of the Literal Interval in the Informix Guide to SQL: Syntax.) When a value contains only one field, the largest and smallest fields are the same.
When you enter a value in an INTERVAL column, you must specify the largest and smallest fields in the value, just as you do for DATETIME values. In addition, you can use n optionally to specify the precision of the first field (and the last field if it is a FRACTION). If the largest and smallest field qualifiers are both FRACTIONS, you can specify only the precision in the last field. Acceptable qualifiers for the largest and smallest fields are identical to the list of INTERVAL fields that Figure 2-8 displays.
If you use the DB-Access TABLE menu, and you do not specify the INTERVAL field qualifiers, the default INTERVAL qualifier, YEAR TO YEAR, is assigned.
The largest_qualifier in an INTERVAL value can be up to nine digits (except for FRACTION, which cannot be more than five digits), but if the value that you want to enter is greater than the default number of digits allowed for that field, you must explicitly identify the number of significant digits in the value that you enter. For example, to define an INTERVAL of DAY TO HOUR that can store up to 999 days, you could specify it the following way:
INTERVAL values use the same delimiters as DATETIME values. Figure 2-9 shows the delimiters.
Figure 2-9
You can also enter INTERVAL values as character strings. However, the character string must include information for the identical sequence of fields defined for that column. The INSERT statement in the following example shows an INTERVAL value entered as a character string:
Because the lead_time column is defined as INTERVAL DAY(3) TO DAY, this INTERVAL value requires only one field, the span of days required for lead time. If the character string does not contain information for all fields (or adds additional fields), the database server returns an error. For more information on entering INTERVAL values as character strings, see the Informix Guide to SQL: Syntax.
By default, all fields of an INTERVAL column are two-digit numbers except for the year and fraction fields. The year field is stored as four digits. The fraction field requires n digits where 1 £ n £ 5, rounded up to an even number. You can use the following formula (rounded up to a whole number of bytes) to calculate the number of bytes required for an INTERVAL value:
For example, a YEAR TO MONTH qualifier requires a total of six digits (four for year and two for month). This data value requires 4, or (6/2) + 1, bytes of storage.
For information on using INTERVAL data in arithmetic and relational operations, see Manipulating DATE with DATETIME and INTERVAL Values. For information on using INTERVAL as a constant expression, see the description of the INTERVAL Field Qualifier in the Informix Guide to SQL: Syntax.
The LIST data type is a collection type that stores ordered, nonunique elements; that is it allows duplicate element values. The elements of a LIST have ordinal positions; with a first, second, and third element in a LIST. (For a collection type with no ordinal positions, see the MULTISET data type on page 2-33 and the SET data type on page 2-42.)
By default, the database server inserts LIST elements at the end of the list. To support the ordinal position of a LIST, the INSERT statement provides the AT clause. This clause allows you to specify the position at which you want to insert a list-element value. For more information, see the INSERT statement in the Informix Guide to SQL: Syntax.
All elements in a LIST have the same element type. To specify the element type, use the following syntax:
The element_type of a collection can be any of the following types:
You must specify the NOT NULL constraint for LIST elements. No other constraints are valid for LIST columns. For more information on the syntax of the LIST collection type, see the Informix Guide to SQL: Syntax.
You can use LIST anywhere that you would use any other data type, for example:
You cannot use LIST with an aggregate function such as AVG, MAX, MIN, or SUM.
Two lists are equal if they have the same elements in the same order. The following examples are lists but are not equal:
The above statements are not equal because the values are not in the same order. To be equal, the second statement would have to be:
The LVARCHAR data type is an SQL data type that you can use to create a column of variable-length character data types that are potentially larger than 255 bytes.
The LVARCHAR data type is also used for input and output casts for opaque data types. The LVARCHAR data type stores opaque data types in the string (external) format. Each opaque type has an input support function and cast, which convert it from LVARCHAR to a form that database servers can manipulate. Each opaque type also has an output support function and cast, which convert it from its internal representation to LVARCHAR.
Important: When LVARCHAR data is stored in a table column, the value is limited to 2 kilobytes (2Kb). When LVARCHAR is used in I/O operations on an opaque type, it has the theoretical size limit of 4 gigabytes (4Gb).
The LVARCHAR data type supports only a subset of the string operations that you can perform on CHAR and VARCHAR data types.
For more information about LVARCHAR, see Extending Informix Dynamic Server 2000.
The MONEY data type stores currency amounts. As with the DECIMAL data type, the MONEY data type stores fixed-point numbers up to a maximum of 32 significant digits, where p is the total number of significant digits (the precision) and s is the number of digits to the right of the decimal point (the scale).
Unlike the DECIMAL data type, the MONEY data type is always treated as a fixed-point decimal number. The database server defines the data type MONEY(p) as DECIMAL(p,2). If the precision and scale are not specified, the database server defines a MONEY column as DECIMAL(16,2).
You can use the following formula (rounded down to a whole number of bytes) to calculate the byte storage for a MONEY data type:
For example, a MONEY data type with a precision of 16 and a scale of 2 (MONEY(16,2)) requires 10 or (16 + 3)/2, bytes of storage.
Client applications format values in MONEY columns with the following currency notation:
To change the format for MONEY values, change the DBMONEY environment variable. For information on how to set the DBMONEY environment variable, see page 3-45.
![]() The default value that the database server uses for scale is locale-dependent. The default locale specifies a default scale of two. For nondefault locales, if the scale is omitted from the declaration, the database server creates MONEY values with a locale-specific scale.
The default value that the database server uses for scale is locale-dependent. The default locale specifies a default scale of two. For nondefault locales, if the scale is omitted from the declaration, the database server creates MONEY values with a locale-specific scale.
The currency notation that client applications use is locale-dependent. If you specify a nondefault locale, the client uses a culture-specific format for MONEY values.
For more information on locale dependency, see the Informix Guide to GLS Functionality.
The MULTISET data type is a collection type that stores nonunique elements: it allows duplicate element values. The elements in a MULTISET have no ordinal position. That is, there is no concept of a first, second, or third element in a MULTISET. (For a collection type with ordinal positions for elements, see the LIST data type on page 2-30.)
All elements in a MULTISET have the same element type. To specify the element type, use the following syntax:
The element_type of a collection can be any of the following types:
You must specify the NOT NULL constraint for MULTISET elements. No other constraints are valid for MULTISET columns. For more information on the syntax of the MULTISET collection type, see the Informix Guide to SQL: Syntax.
You can use MULTISET anywhere that you use any other data type, unless otherwise indicated. For example:
You cannot use MULTISET with an aggregate function such as AVG, MAX, MIN, or SUM.
Two multisets are equal if they have the same elements, even if the elements are in different positions in the set. The following examples are multisets but are not equal:
The following multisets are equal:
See Row, Named.
![]() The NCHAR data type stores fixed-length character data. This data can be a sequence of single-byte or multibyte letters, numbers, and symbols. The main difference between CHAR and NCHAR data types is the collation order. While the collation order of the CHAR data type is defined by the code-set order, the collation order of the NCHAR data type depends on the locale-specific localized order. For more information about the NCHAR data type, see the Informix Guide to GLS Functionality.
The NCHAR data type stores fixed-length character data. This data can be a sequence of single-byte or multibyte letters, numbers, and symbols. The main difference between CHAR and NCHAR data types is the collation order. While the collation order of the CHAR data type is defined by the code-set order, the collation order of the NCHAR data type depends on the locale-specific localized order. For more information about the NCHAR data type, see the Informix Guide to GLS Functionality.
The NUMERIC data type is a synonym for fixed-point DECIMAL.
![]() The NVARCHAR data type stores character data of varying lengths. This data can be a sequence of single-byte or multibyte letters, numbers, and symbols. The main difference between VARCHAR and NVARCHAR data types is the collation order. While the collation order of the VARCHAR data type is defined by the code-set order, the collation order of the NVARCHAR data type depends on the locale-specific localized order. For more information about the NVARCHAR data type, see the Informix Guide to GLS Functionality.
The NVARCHAR data type stores character data of varying lengths. This data can be a sequence of single-byte or multibyte letters, numbers, and symbols. The main difference between VARCHAR and NVARCHAR data types is the collation order. While the collation order of the VARCHAR data type is defined by the code-set order, the collation order of the NVARCHAR data type depends on the locale-specific localized order. For more information about the NVARCHAR data type, see the Informix Guide to GLS Functionality.
An opaque type is a data type for which you provide the following information to the database server:
The internal structure of an opaque type is not visible to the database server. The internal structure can only be accessed through user-defined routines. Definitions for opaque types are stored in the sysxtdtypes system catalog table. The following SQL statements maintain the definitions of opaque types in the database:
For more information on the above-mentioned SQL statements, see the Informix Guide to SQL: Syntax. For information on how to create opaque types and an example of an opaque type, see Extending Informix Dynamic Server 2000.
The REAL data type is a synonym for SMALLFLOAT.
A named row type is defined by its name. That name must be unique within the schema. An unnamed row type is a row type that contains fields but has no user-defined name. Use a named row type if you want to use type inheritance. For more information, see Row Data Types.
You must define a named row type in the database. Definitions for named row types are stored in the sysxtdtypes system catalog table.
The fields of a row type can be any data type. The fields of a row type that are TEXT or BYTE type can be used in typed tables only. If you want to assign a row type to a column, then the elements of the row cannot be of TEXT and BYTE data types.
In general, the data type of the field of a row type can be any of the following types:
The following SQL statements maintain the definitions of named row types in the database:
For details about the preceding SQL syntax statements, see the Informix Guide to SQL: Syntax. For examples of how to create and used named row types, see the Informix Guide to Database Design and Implementation.
No two named row types can be equal, even if they have identical structures, because they have different names. For example, the following named row types have the same structure but are not equal:
Named row types can be part of a type-inheritance hierarchy. That is, one named row type can be the parent (supertype) of another named row type. A subtype in a hierarchy inherits all the properties of its supertype. Type inheritance is discussed in the CREATE ROW TYPE statement in the Informix Guide to SQL: Syntax and in the Informix Guide to Database Design and Implementation.
Tables that are part of an inheritance hierarchy must be typed tables. Typed tables are tables that have been assigned a named row type. For the syntax you use to create typed tables, see the CREATE TABLE statement in the Informix Guide to SQL: Syntax. Table inheritance and how it relates to type inheritance is also discussed in that section. For information about how to create and use typed tables, see the Informix Guide to Database Design and Implementation.
An unnamed row type contains fields but has no user-defined name. An unnamed row type is defined by its structure. Two unnamed row types are equal if they have the same structure. If two unnamed row types have the same number of fields, and if the data type of each field in one row type matches the data type of the corresponding field in the other row type, the two unnamed row types are equal.
For example, the following unnamed row types are equal:
The following row types are not equivalent, even though they have the same number of fields and the same data types, because the fields are not in the same order:
The data type of the field of an unnamed row type can be any of the following types:
Unnamed row types cannot be used in type tables or in type inheritance hierarchies.
For more information on unnamed row types, see the Informix Guide to SQL: Syntax and the Informix Guide to Database Design and Implementation.
You can create an unnamed row type in several ways:
When you specify field values for an unnamed row type, list the field values after the constructor and between parentheses. For example, suppose you have an unnamed row-type column. The following INSERT statement adds one group of field values to this ROW column:
You can specify a ROW column in the IN predicate in the WHERE clause of a SELECT statement to search for matching ROW values. For more information, see the Condition segment in the Informix Guide to SQL: Syntax.
The SERIAL data type stores a sequential integer assigned automatically by the database server when a row is inserted. You can define only one SERIAL column in a table. For information on inserting values in SERIAL columns, see the Informix Guide to SQL: Syntax.
The SERIAL data type is not automatically a unique column. You must apply a unique index or primary key constraint to this column to prevent duplicate serial numbers. If you use the interactive schema editor in DB-Access to define the table, a unique index is applied automatically to a SERIAL column.
Also, serial numbers might not be contiguous due to such factors as multiuser systems and rollbacks.
The default serial starting number is 1, but you can assign an initial value, n, when you create or alter the table. You can assign any number greater than 0 as your starting number. The highest serial number that you can assign is 2,147,483,647. If you assign a number greater than 2,147,483,647, you receive a syntax error.
Once a nonzero number is assigned, it cannot be changed. You can, however, insert a value in a SERIAL column (using the INSERT statement) or reset the serial value n (using the ALTER TABLE statement), as long as that value does not duplicate any existing values in the table. When you insert a number in a SERIAL column or reset the next value of a SERIAL column, your database server assigns the next number in sequence to the number entered. However, if you reset the next value of a SERIAL column to a value that is less than the values already in that column, the next value is computed with the following formula:
For example, if you reset the serial value of the customer_num column in the customer table to 50 and the highest-assigned customer number is 128, the next customer number assigned is 129.
A SERIAL data column is commonly used to store unique numeric codes (for example, order, invoice, or customer numbers). SERIAL data values require 4 bytes of storage.
The SERIAL8 data type stores a sequential integer assigned automatically by the database server when a row is inserted. (For more information on how to insert values into SERIAL8 columns, see the Informix Guide to SQL: Syntax.)
A SERIAL8 data column is commonly used to store large, unique numeric codes (for example, order, invoice, or customer numbers). SERIAL8 data values require 8 bytes of storage. The following restrictions apply to SERIAL8 columns:
If you are using the interactive schema editor in DB-Access to define the table, a unique index is applied automatically to a SERIAL8 column.
The default serial starting number is 1, but you can assign an initial value, n, when you create or alter the table. To start the values at 1 in a serial column of a table, give the value 0 for the SERIAL8 column when you insert rows into that table.The database server will assign the value 1 to the serial column of the first row of the table. The highest serial number you can assign is 263-1 (9,223,372,036,854,775,807). If you assign a number greater than this value, you receive a syntax error. When the database server generates a SERIAL8 value of this maximum number, it wraps around and starts generating values beginning at 1.
Once a nonzero number is assigned, it cannot be changed. You can, however, insert a value into a SERIAL8 column (using the INSERT statement) or reset the serial value n (using the ALTER TABLE statement), as long as that value does not duplicate any existing values in the table.
When you insert a number into a SERIAL8 column or reset the next value of a SERIAL8 column, your database server assigns the next number in sequence to the number entered. However, if you reset the next value of a SERIAL8 column to a value that is less than the values already in that column, the next value is computed using the following formula:
For example, if you reset the serial value of the customer_num column in the customer table to 50 and the highest-assigned customer number is 128, the next customer number assigned is 129.
The database server treats the SERIAL8 data type as a special case of the INT8 data type. Therefore, all the arithmetic operators that are legal for INT8 (such as +, -, *, and /) and all the SQL functions that are legal for INT8 (such as ABS, MOD, POW, and so on) are also legal for SERIAL8 values. All data conversion rules that apply to INT8 also apply to SERIAL8.
The value of a SERIAL8 column of a table can be stored in the columns of another table. However, when the values of the SERIAL8 column are put into the second table, their values lose the constraints imposed by their original SERIAL8 column and they are stored as INT8 values.
The SET data type is a collection type that stores unique elements; it does not allow duplicate element values. (For a collection type that does allow duplicate values, see the description of MULTISET on page 2-33.)
The elements in a SET have no ordinal position. That is, no concept of a first, second, or third element in a SET exists. (For a collection type with ordinal positions for elements, see the LIST data type on page 2-30.)
All elements in a SET have the same element type. To specify the element type, use the following syntax:
The element_type of a collection can be any of the following types:
You must specify the NOT NULL constraint for SET elements. No other constraints are valid for SET columns. For more information on the syntax of the SET collection type, see the Informix Guide to SQL: Syntax.
You can use SET anywhere that you use any other data type, unless otherwise indicated. For example:
For more information, see the Condition and Expression segments in the Informix Guide to SQL: Syntax.
You cannot use the SET column with an aggregate function such as AVG, MAX, MIN, or SUM.
The following examples declare two sets. The first example declares a set of integers and the second declares a set of character elements.
The following examples construct the same sets from value lists:
In the following example, a SET constructor is part of a CREATE TABLE statement:
The following sets are equal:
The SMALLFLOAT data type stores single-precision floating-point numbers with approximately eight significant digits. SMALLFLOAT corresponds to the float data type in C. The range of values for a SMALLFLOAT data type is the same as the range of values for the C float data type on your computer.
A SMALLFLOAT data type column typically stores scientific numbers that can be calculated only approximately. Because floating-point numbers retain only their most significant digits, the number that you enter in this type of column and the number the database displays might differ slightly depending on how your computer stores floating-point numbers internally.
For example, you might enter a value of 1.1000001 in a SMALLFLOAT field and, after processing the SQL statement, the application development tool might display this value as 1.1. This difference occurs when a value has more digits than the floating-point number can store. In this case, the value is stored in its approximate form with the least significant digits treated as zeros.
SMALLFLOAT data types usually require 4 bytes per value.
Conversion of a SMALLFLOAT value to a DECIMAL value results in 9 digits of precision.
The SMALLINT data type stores small whole numbers that range from -32,767 to 32,767. The maximum negative number, -32,768, is a reserved value and cannot be used. The SMALLINT value is stored as a signed binary integer.
Integer columns typically store counts, quantities, and so on. Because the SMALLINT data type takes up only 2 bytes per value, arithmetic operations are performed efficiently. However, this data type stores a limited range of values. If the values exceed the range between the minimum and maximum numbers, the database server does not store the value and provides you with an error message.
The TEXT data type stores any kind of text data. It can contain both single and multibyte characters.
The TEXT data type has no maximum size. A TEXT column has a theoretical limit of 231 bytes and a practical limit that your available disk storage determines.
The term simple large object is used to refer to TEXT and BYTE data types.
TEXT columns typically store memos, manual chapters, business documents, program source files, and so on. In the default locale U.S. ASCII English, data object of type TEXT can contain a combination of printable ASCII characters and the following control characters:
You can store, retrieve, update, or delete the contents of a TEXT column. However, you cannot use TEXT data items in arithmetic or string operations or assign literals to TEXT items with the SET clause of the UPDATE statement. You also cannot use TEXT items in the following ways:
You can use TEXT objects in Boolean expressions only if you are testing for null values.
You can insert data in TEXT columns in the following ways:
You cannot use a quoted text string, number, or any other actual value to insert or update TEXT columns.
When you select a TEXT column, you can choose to receive all or part of it. To see all of a column, use the regular syntax for selecting a column into a variable. You can also select any part of a TEXT column with subscripts, as the following example shows:
This statement reads the first 75 bytes of the cat_descr column associated with catalog number 10001.
The database server provides a cast to convert TEXT objects to CLOB objects. For more information, see the Informix Guide to Database Design and Implementation.
Important: If you try to return a TEXT column from a subquery, you get an error message even when the TEXT column is not used in a comparison condition or with the IN predicate.
Nonprintable Characters with TEXT
Both printable and nonprintable characters can be inserted in text columns. Informix products do not do any checking of the data that is inserted in a column with the TEXT data type. For detailed information on entering and displaying nonprintable characters, refer to Nonprintable Characters with CHAR.
The TEXT data type is collated in code-set order. For more information on collation orders, see the Informix Guide to GLS Functionality.
![]() The database locale must support multibyte TEXT characters. For more information, see the Informix Guide to GLS Functionality.
The database locale must support multibyte TEXT characters. For more information, see the Informix Guide to GLS Functionality.
See Row, Unnamed.
The VARCHAR data type stores character sequences that contain single-byte and multibyte character sequences of varying length, where m is the maximum byte size of the column and r is the minimum amount of byte space reserved for that column.
The VARCHAR data type is the Informix implementation of a character varying data type. The ANSI standard data type for varying character strings is CHARACTER VARYING and is described on page 2-15.
You must specify the maximum size (m) of the VARCHAR column. The size of this parameter can range from 1 to 255 bytes. If you are placing an index on a VARCHAR column, the maximum size is 254 bytes. You can store shorter, but not longer, character strings than the value that you specify.
Specifying the minimum reserved space (r) parameter is optional. This value can range from 0 to 255 bytes but must be less than the maximum size (m) of the VARCHAR column. If you do not specify a minimum space value, it defaults to 0. You should specify this parameter when you initially intend to insert rows with short or null data in this column, but later expect the data to be updated with longer values.
Although the use of VARCHAR economizes on space used in a table, it has no effect on the size of an index. In an index based on a VARCHAR column, each index key has length m, the maximum size of the column.
When you store a VARCHAR value in the database, only its defined characters are stored. The database server does not strip a VARCHAR object of any user-entered trailing blanks, nor does the database server pad the VARCHAR to the full length of the column. However, if you specify a minimum reserved space (r) and some data values are shorter than that amount, some space reserved for rows goes unused.
VARCHAR values are compared to other VARCHAR values and to character values in the same way that character values are compared. The shorter value is padded on the right with spaces until the values have equal lengths; then they are compared for the full length.
Nonprintable VARCHAR characters are entered, displayed, and treated in the same way as nonprintable CHAR characters are. For detailed information on entering and displaying nonprintable characters, refer to Nonprintable Characters with CHAR.
When you insert a numeric value in a VARCHAR column, the stored value does not get padded with trailing blanks to the maximum length of the column. The number of digits in a numeric VARCHAR value is the number of characters that you need to store that value. For example, given the following statement, the value that gets stored in table mytab is 1.
 Tip: VARCHAR treats C null (binary 0) and string terminators as termination characters for nonprintable characters.
Tip: VARCHAR treats C null (binary 0) and string terminators as termination characters for nonprintable characters.
Multibyte Characters with VARCHAR
![]() The database locale must support multibyte VARCHAR characters. If you store multibyte characters, make sure to calculate the number of bytes needed. For more information, see the Informix Guide to GLS Functionality.
The database locale must support multibyte VARCHAR characters. If you store multibyte characters, make sure to calculate the number of bytes needed. For more information, see the Informix Guide to GLS Functionality.
The main difference between the NVARCHAR and the VARCHAR data types is the difference in collation sequencing. Collation order of NVARCHAR characters depends on the GLS locale chosen, while collation of VARCHAR characters depends on the code set. For more information, see the Informix Guide to GLS Functionality.