| Informix Guide to SQL: Syntax SQL Statements |
|
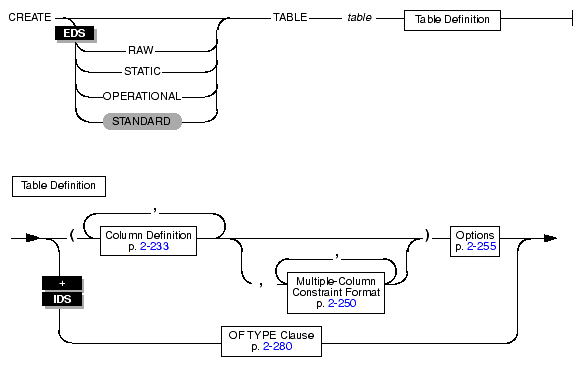
Use the CREATE TABLE statement to create a new table in the current database, place data-integrity constraints on columns, designate where the table should be stored, indicate the size of its initial and subsequent extents, and specify how to lock it.
You can use the CREATE TABLE statement to create relational-database tables or typed tables (object-relational tables). For information on how to create temporary tables, see CREATE Temporary TABLE.
|
When you create a table, the table and columns within that table must have unique names and every table column must have a data type associated with it.
![]() In an ANSI-compliant database, the combination owner.table must be unique within the database.
In an ANSI-compliant database, the combination owner.table must be unique within the database. 
![]() In DB-Access, using the CREATE TABLE statement outside the CREATE SCHEMA statement generates warnings if you use the -ansi flag or set DBANSIWARN.
In DB-Access, using the CREATE TABLE statement outside the CREATE SCHEMA statement generates warnings if you use the -ansi flag or set DBANSIWARN.
![]() In ESQL/C, using the CREATE TABLE statement generates warnings if you use the -ansi flag or set DBANSIWARN.
In ESQL/C, using the CREATE TABLE statement generates warnings if you use the -ansi flag or set DBANSIWARN.
For information about the DBANSIWARN environment variable, refer to the Informix Guide to SQL: Reference.
In Enterprise Decision Server, use the Usage-TYPE Options to specify that the table has particular characteristics that can improve various bulk operations on it. Other than the default option (STANDARD) that is used for OLTP databases, these usage-type options are used primarily to improve performance in data warehousing databases.
A table can have any of the following usage characteristics.
For a more detailed description of these table types, refer to your Administrator's Guide.
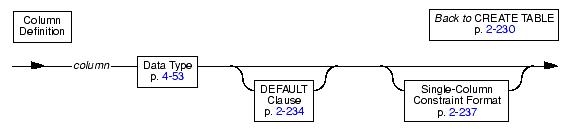
Use the column definition portion of CREATE TABLE to list the name, data type, default values, and constraints of a single column.
|
When you name a column, as with any SQL identifier, you can use a reserved word, but syntactic ambiguities can occur. For more information on reserved words for Dynamic Server, see Appendix A, Reserved Words for Dynamic Server. For more information on reserved words for Enterprise Decision Server, see Appendix B, Reserved Words for Enterprise Decision Server. For more information on the ambiguities that can occur, see Using Keywords as Column Names.
![]() If you define a column of a table to be of a named-row type, the table does not adopt any constraints of the named row.
If you define a column of a table to be of a named-row type, the table does not adopt any constraints of the named row.
Use the DEFAULT clause to specify the default value that the database server should insert in a column when an explicit value for the column is not specified.

|
If you do not indicate a default value for a column, the default is null unless you place a not-null constraint on the column. In that case, no default value exists for the column.
You cannot specify default values for serial columns.
You can designate a literal value as a default value. A literal value is a string of alphabetic or numeric characters. To use a literal value as a default value, you must adhere to the syntax restrictions in the following table.
Date literals must be of the format that the DBDATE environment variable specifies. If DBDATE is not set, the date literals must be of the mm/dd/yyyy format.
If you do not indicate a default value for a column, the default is null unless you place a not-null constraint on the column. In this case, no default value exists for the column.
If you specify null as the default value for a column, you cannot specify a not-null constraint as part of the column definition.
You cannot designate null as the default value for a column that is part of a primary key.
If the column is BYTE or TEXT data type, null is the only default value that you can designate.
![]() If the column is BLOB or CLOB data type, null is the only default value that you can designate.
If the column is BLOB or CLOB data type, null is the only default value that you can designate.
You can specify a built-in function as the default value for a column. The following table indicates the built-in functions that you can specify, the data type requirements, and the recommended size for their corresponding columns.
Informix recommends a column size because if the column length is too small to store the default value during INSERT and ALTER TABLE operations, the database server returns an error.
![]() You cannot designate a built-in function (that is, CURRENT, USER, TODAY, SITENAME, or DBSERVERNAME) as the default value for a column that holds opaque or distinct data types.
You cannot designate a built-in function (that is, CURRENT, USER, TODAY, SITENAME, or DBSERVERNAME) as the default value for a column that holds opaque or distinct data types.
For more information on these built-in functions, see Constant Expressions.
The following example creates a table called accounts. In accounts, the acc_num, acc_type, and acc_descr columns have literal default values. The acc_id column defaults to the login name of the user.
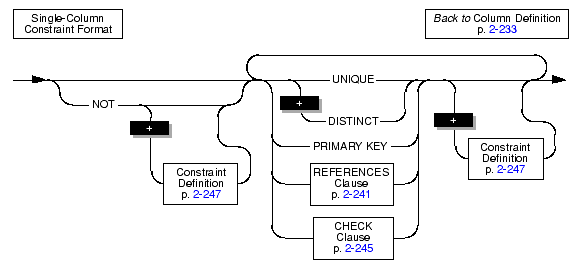
Use the Single-Column Constraint Format to associate one or more constraints with a particular column. You can use this portion of CREATE TABLE to perform the following tasks:
|
The following example creates a simple table with two constraints, a primary-key constraint named num on the acc_num column and a unique constraint named code on the acc_code column:
The constraints used in this example are defined in the following sections.
When you use the single-column constraint format, you cannot use constraints that involve more than one column. For example, you cannot use the single-column constraint format to define a composite key. For information on multiple-column constraints, see Multiple-Column Constraint Format.
Using Large-Object Types in ConstraintsYou cannot place unique, primary-key, or referential constraints on BYTE or TEXT columns. However, you can check for null or non-null values with a check constraint.
![]() You cannot place unique, primary-key, or referential constraints on BLOB or CLOB columns.
You cannot place unique, primary-key, or referential constraints on BLOB or CLOB columns.
Use the NOT NULL keywords to require that a column receive a value during insert or update operations. If you place a not null constraint on a column (and no default value is specified), you must enter a value into this column when you insert a row or update that column in a row. If you do not enter a value, the database server returns an error.
The following example creates the newitems table. In newitems, the column manucode does not have a default value nor does it allow nulls.
If you do not indicate a default value for a column, the default is null unless you place a NOT NULL constraint on the column. In this case, no default value exists for the column.
You cannot specify NULL as the default value for a column and also specify the NOT NULL constraint.
Use the UNIQUE or DISTINCT keyword to require that a column or set of columns accepts only unique data. You cannot insert duplicate values in a column that has a unique constraint. When you create a UNIQUE or DISTINCT constraint, the database server automatically creates an internal index on the constrained column or columns.
Restrictions on Defining Unique Constraints
You cannot place a unique constraint on a column on which you have already placed a primary-key constraint.
You cannot place a unique constraint on a BYTE or TEXT column.
![]() You cannot place a unique or primary-key constraint on a BLOB or CLOB column.
You cannot place a unique or primary-key constraint on a BLOB or CLOB column.
Opaque types support a unique constraint only where a secondary access method supports uniqueness for that type. The default secondary access method is a generic B-tree, which supports the equal() function. Therefore, if the definition of the opaque type includes the equal() function, a column of that opaque type can have a unique constraint.
The following example creates a simple table that has a unique constraint on one of its columns:
For an explanation of the constraint name, refer to Choosing a Constraint Name.
A primary key is a column or a set of columns (available when you use the multiple-column constraint format) that contains a non-null, unique value for each row in a table. When you create a PRIMARY KEY constraint, the database server automatically creates an internal index on the column or columns that make up the primary key.
Restrictions for Primary-Key ConstraintsYou can designate only one primary key for a table. If you define a single column as the primary key, it is unique by definition; you cannot explicitly give the same column a unique constraint.
You cannot place a primary-key constraint on a BYTE or TEXT column.
![]() You cannot place a unique or primary-key constraint on a BLOB or CLOB column.
You cannot place a unique or primary-key constraint on a BLOB or CLOB column.
Opaque types support a primary key constraint only where a secondary access method supports the uniqueness for that type. The default secondary access method is a generic B-tree, which supports the equal() function. Therefore, if the definition of the opaque type includes the equal() function, a column of that opaque type can have a primary-key constraint.
In the previous two examples, a unique constraint was placed on the column acc_num. The following example creates this column as the primary key for the accounts table:
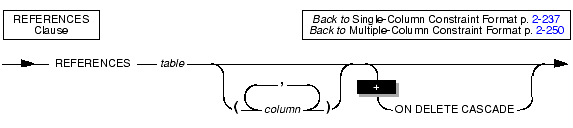
Use the REFERENCES clause to establish a referential relationship:
|
The referencing column (the column being defined) is the column or set of columns that refers to the referenced column or set of columns. The referencing column or set of columns can contain null and duplicate values. However, the values in the referenced column or set of columns must be unique.
The relationship between referenced and referencing columns is called a parent-child relationship, where the parent is the referenced column (primary key) and the child is the referencing column (foreign key). The referential constraint establishes this parent-child relationship.
When you create a referential constraint, the database server automatically creates an internal index on the constrained column or columns.
You must have the References privilege to create a referential constraint.
When you use the REFERENCES clause, you must observe the following restrictions:
If the referenced table is different from the referencing table, you do not need to specify the referenced column; the default column is the primary-key column (or columns) of the referenced table. If the referenced table is the same as the referencing table, you must specify the referenced column.
You can establish a referential relationship between two columns of the same table. In the following example, the emp_num column in the employee table uniquely identifies every employee through an employee number. The mgr_num column in that table contains the employee number of the manager who manages that employee. In this case, mgr_num references emp_num. Duplicate values appear in the mgr_num column because managers manage more than one employee.
When you create a referential constraint, an exclusive lock is placed on the referenced table. The lock is released when the CREATE TABLE statement is finished. If you are creating a table in a database with transactions, and you are using transactions, the lock is released at the end of the transaction.
The following example uses the single-column constraint format to create a referential relationship between the sub_accounts and accounts tables. The ref_num column in the sub_accounts table references the acc_num column (the primary key) in the accounts table.
When you use the single-column constraint format, you do not explicitly specify the ref_num column as a foreign key. To use the FOREIGN KEY keyword, use the Multiple-Column Constraint Format.
Use the ON DELETE CASCADE option to specify whether you want rows deleted in a child table when corresponding rows are deleted in the parent table. If you do not specify cascading deletes, the default behavior of the database server prevents you from deleting data in a table if other tables reference it.
If you specify this option, later when you delete a row in the parent table, the database server also deletes any rows associated with that row (foreign keys) in a child table. The principal advantage to the cascading-deletes feature is that it allows you to reduce the quantity of SQL statements you need to perform delete actions.
For example, the all_candy table contains the candy_num column as a primary key. The hard_candy table refers to the candy_num column as a foreign key. The following CREATE TABLE statement creates the hard_candy table with the cascading-delete option on the foreign key:
Because the ON DELETE CASCADE option is specified for the child table, when an item from the all_candy table is deleted, the delete cascades to the corresponding rows of the hard_candy table.
For information about syntax restrictions and locking implications when you delete rows from tables that have cascading deletes, see Considerations When Tables Have Cascading Deletes.
Use the CHECK clause to designate conditions that must be met before data can be assigned to a column during an INSERT or UPDATE statement.

|
During an insert or update, if a row evaluates to false for any check constraint defined on a table, the database server returns an error. The database server does not return an error if a row evaluates to null for a check constraint. In some cases, you might wish to use both a check constraint and a NOT NULL constraint.
You use search conditions to define check constraints. The search condition cannot contain the following items: subqueries, aggregates, host variables, rowids, or user-defined routines. In addition, the search condition cannot contain the following built-in functions: CURRENT, USER, SITENAME, DBSERVERNAME, or TODAY.
 When you specify a date value in a search condition, make sure you specify 4 digits instead of 2 digits for the year. When you specify a 4-digit year, the DBCENTURY environment variable has no effect on the distribution scheme. When you specify a 2-digit year, the DBCENTURY environment variable can affect the distribution scheme and can produce unpredictable results. See the "Informix Guide to SQL: Reference" for more information on the DBCENTURY environment variable.
When you specify a date value in a search condition, make sure you specify 4 digits instead of 2 digits for the year. When you specify a 4-digit year, the DBCENTURY environment variable has no effect on the distribution scheme. When you specify a 2-digit year, the DBCENTURY environment variable can affect the distribution scheme and can produce unpredictable results. See the "Informix Guide to SQL: Reference" for more information on the DBCENTURY environment variable.
With a BYTE or TEXT column, you can check for null or not-null values. This constraint is the only constraint allowed on a BYTE or TEXT columns.
![]() With a BLOB or CLOB column, you can check for null or not-null values. This constraint is the only constraint allowed on a BLOB or CLOB columns.
With a BLOB or CLOB column, you can check for null or not-null values. This constraint is the only constraint allowed on a BLOB or CLOB columns.
When you use the single-column constraint format to define a check constraint, the only column that the check constraint can check against is the column itself. In other words, the check constraint cannot depend on values in other columns of the table.
ExampleThe following example creates the my_accounts table which has two columns with check constraints:
Both acct1 and acct2 are columns of MONEY data type whose values must be between 0 and 99999.
If, however, you want to test that acct1 has a larger balance than acct2, you cannot use the single-column constraint format. To create a constraint that checks values in more than one column, you must use the Multiple-Column Constraint Format.
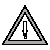
Use the constraint definition portion of CREATE TABLE for the following purposes:
|
Whenever you use the single- or multiple-column constraint format to place a data restriction on a column, the database server creates a constraint and adds a row for that constraint to the sysconstraints system catalog table. The database server also generates an identifier and adds a row to the sysindexes system catalog table for each new primary-key, unique, or referential constraint that does not share an index with an existing constraint. Even if you assign a name to a constraint, the database server generates the name that appears in the sysindexes table.
If you wish, you can specify a meaningful name for the constraint. The name of a constraint must be unique within the database.
Constraint names appear in error messages having to do with constraint violations. You can use this name when you use the DROP CONSTRAINT clause of the ALTER TABLE statement.
![]() In addition, you specify a constraint name when you change the mode of constraint with the SET Database Object Mode statement or the SET Transaction Mode statement.
In addition, you specify a constraint name when you change the mode of constraint with the SET Database Object Mode statement or the SET Transaction Mode statement.
![]() When you create a constraint of any type, the owner.constraint (the combination of the owner name and constraint name) must be unique within the database.
When you create a constraint of any type, the owner.constraint (the combination of the owner name and constraint name) must be unique within the database.
![]() The system catalog table that holds information about indexes is the sysindices table.
The system catalog table that holds information about indexes is the sysindices table.
If you do not specify a constraint name, the database server generates a constraint name using the following template:
In this template, constraint_type is the letter u for unique or primary-key constraints, r for referential constraints, c for check constraints, and n for not-null constraints. In the template, tabid and constraintid are values from the tabid and constrid columns of the systables and sysconstraints system catalog tables, respectively. For example, the constraint name for a unique constraint might look like: u111_14.
If the generated name conflicts with an existing identifier, the database server returns an error, and you must then supply a constraint name.
The index name in sysindexes (or sysindices) is created with the following format:
For example, the index name might be something like: " 111_14" (quotation marks are used to show the space).
Use the constraint-mode options to control the behavior of constraints during insert, delete, and update operations. The following list explains these options.
If you choose filtering mode, you can specify the WITHOUT ERROR or WITH ERROR options. The following list explains these options.
For how to set the constraint mode after the table exists, see SET Database Object Mode. For information about where the database server stores data that violates a constraint set to filtering, see START VIOLATIONS TABLE.
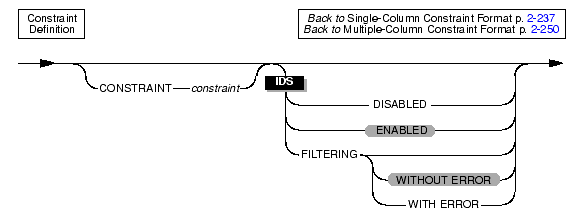
Use the multiple-column constraint format to associate one or more columns with a constraint. This alternative to the single-column constraint format allows you to associate multiple columns with a constraint.
|
When you use the multiple-column constraint format, you can perform the following tasks:
When you use this format, you can create composite primary and foreign keys. You can also define check constraints that involve comparing data in different columns.
When you use the multiple-column constraint format, you cannot define any default values for columns. In addition, you cannot establish a referential relationship between two columns of the same table.
To define a default value for a column or establish a referential relationship between two columns of the same table, refer to Single-Column Constraint Format and Referential Relationships Within a Table respectively.
Using Large-Object Types in ConstraintsYou cannot place unique, primary-key, or referential (FOREIGN KEY) constraints on BYTE or TEXT columns. However, you can check for null or non-null values with a check constraint.
![]() You cannot place unique or primary-key constraints on BLOB or CLOB columns.
You cannot place unique or primary-key constraints on BLOB or CLOB columns.
The following table indicates where you can find detailed discussions of specific constraints
A foreign key joins and establishes dependencies between tables, that is, it creates a referential constraint.
A foreign key references a unique or primary key in a table. For every entry in the foreign-key columns, a matching entry must exist in the unique or primary-key columns if all foreign-key columns contain non-null values.
You cannot make BYTE or TEXT columns be foreign keys.
![]() You cannot make BLOB or CLOB columns be foreign keys.
You cannot make BLOB or CLOB columns be foreign keys.
For more information on referential constraints, see the REFERENCES Clause.
The following example creates a simple table with a unique constraint. The example uses the multiple-column constraint format. However, nothing in this example would prohibit you from using the single-column constraint format to define this constraint.
For an explanation of the constraint name, refer to Choosing a Constraint Name.
Defining Check Constraints Across ColumnsWhen you use the multiple-column constraint format to define check constraints, a check constraint can apply to more than one column in the table. (However, you cannot create a check constraint for columns across tables.)
The following example includes a comparison of acct1 and acct2 two columns in the table.
In this example, the acct1 column must be greater than the acct2 column, or the insert or update fails.
Defining Composite Primary and Foreign KeysWhen you use the multiple-column constraint format, you can create a composite key (that is, you can specify multiple columns for a primary key or foreign key constraint.
The following example creates two tables. The first table has a composite key that acts as a primary key, and the second table has a composite key that acts as a foreign key.
In this example, the foreign key of the sub_accounts table, ref_num and ref_type, references the composite key, acc_num and acc_type, in the accounts table. If, during an insert or update, you tried to insert a row into the sub_accounts table whose value for ref_num and ref_type did not exactly correspond to the values for acc_num and acc_type in an existing row in the accounts table, the database server would return an error.
A referential constraint must have a one-to-one relationship between referencing and referenced columns. In other words, if the primary key is a set of columns (a composite key), then the foreign key also must be a set of columns that corresponds to the composite key.
Because of the default behavior of the database server, when you create the foreign key reference, you do not have to reference the composite key columns (acc_num and acc_type) explicitly.
You can rewrite the references section of the previous example as follows:
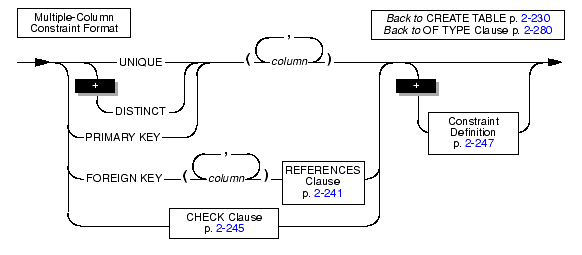
The CREATE TABLE options let you specify storage locations, extent size, locking modes, and user-defined access methods.
|
Use the WITH CRCOLS keywords to create two shadow columns that Enterprise Replication uses for conflict resolution. The first column, cdrserver, contains the identity of the database server where the last modification occurred. The second column, cdrtime, contains the time stamp of the last modification. You must add these columns before you can use time-stamp or user-defined routine conflict resolution.
For most database operations, the cdrserver and cdrtime columns are hidden. For example, if you include the WITH CRCOLS keywords when you create a table, the cdrserver and cdrtime columns:
To view the contents of cdrserver and cdrtime, explicitly name the columns in a SELECT statement, as the following example shows:
For more information about using this option, refer to the Guide to Informix Enterprise Replication.
Use the storage option portion of CREATE TABLE to specify the storage space and the size of the extents for the table.

|
If you use the USING Access-Method Clause to specify an access method, the storage space named must be supported by that access method.
You can specify a dbspace for the table that is different from the storage location specified for the database, or fragment the table into several dbspaces. If you do not specify the IN clause or a fragmentation scheme, the database server stores the table in the dbspace where the current database resides.
![]() You can use the PUT clause to specify storage options for smart large objects. For more information, see PUT Clause.
You can use the PUT clause to specify storage options for smart large objects. For more information, see PUT Clause.
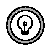 Tip: If your table has columns that contain simple large objects (TEXT or BYTE), you can specify a separate blobspace for each object. For information on storing simple large objects, refer to Large-Object Data Types.
Tip: If your table has columns that contain simple large objects (TEXT or BYTE), you can specify a separate blobspace for each object. For information on storing simple large objects, refer to Large-Object Data Types.
Using the IN Clause
Use the IN clause to specify a storage space for a table. The storage space that you specify must already exist.
Storing Data in a dbspaceYou can use the IN clause to isolate a table. For example, if the history database is in the dbs1 dbspace, but you want the family data placed in a separate dbspace called famdata, use the following statements:
For more information about how to store and manage your tables in separate dbspaces, see your Administrator's Guide.
If you are using Enterprise Decision Server, the IN dbslice clause allows you to fragment a table across a group of dbspaces that share the same naming convention. The database server fragments the table by round-robin in the dbspaces that make up the dbslice at the time the table is created.
To fragment a table across a dbslice, you can use either the IN dbslice syntax or the FRAGMENT BY ROUND ROBIN IN dbslice syntax.
In general, you use this option in conjunction with the USING Access-Method Clause. Refer to the user documentation for your custom-access method for more information.
Use the FRAGMENT BY clause to create fragmented tables and specify the distribution scheme.

|
When you fragment a table, the IN keyword introduces the storage space where a table fragment is to be stored.
Nonfragmented tables contain a hidden column called the rowid column. However, fragmented tables do not contain this column. If a table is fragmented, you can use the WITH ROWIDS keywords to add the rowid column to the table. The database server assigns to each row in the rowid column a unique number that remains stable for the life of the row. The database server uses an index to find the physical location of the row. After you add the rowid column, each row contains an additional 4 bytes to store the rowid.
 Important: Informix recommends that you use primary keys as an access method rather than the rowid column.
Important: Informix recommends that you use primary keys as an access method rather than the rowid column.
You cannot use the WITH ROWIDS clause with typed tables.
In a round-robin distribution scheme, specify at least two dbspaces where you want the fragments to be placed. As records are inserted into the table, they are placed in the first available dbspace. The database server balances the load between the specified dbspaces as you insert records and distributes the rows in such a way that the fragments always maintain approximately the same number of rows. In this distribution scheme, the database server must scan all fragments when it searches for a row.
![]() If you are using Enterprise Decision Server, you can specify the name of a dbslice to fragment a table across a group of dbspaces that share the same naming convention. For a syntax alternative to FRAGMENT BY ROUND ROBIN IN dbslice that achieves the same results, see Storing Data in a dbslice.
If you are using Enterprise Decision Server, you can specify the name of a dbslice to fragment a table across a group of dbspaces that share the same naming convention. For a syntax alternative to FRAGMENT BY ROUND ROBIN IN dbslice that achieves the same results, see Storing Data in a dbslice.
![]() Use the PUT clause to specify round-robin fragmentation for smart large objects. For more information, see PUT Clause.
Use the PUT clause to specify round-robin fragmentation for smart large objects. For more information, see PUT Clause.
In an expression-based distribution scheme, each fragment expression in a rule specifies a storage space. Each fragment expression in the rule isolates data and aids the database server in searching for rows. Specify one of the following rules:
 Warning: When you specify a date value in a fragment expression, make sure you specify 4 digits instead of 2 digits for the year. When you specify a 4-digit year, the DBCENTURY environment variable has no effect on the distribution scheme. When you specify a 2-digit year, the DBCENTURY environment variable can affect the distribution scheme and can produce unpredictable results. See the "Informix Guide to SQL: Reference" for more information on the DBCENTURY environment variable.
Warning: When you specify a date value in a fragment expression, make sure you specify 4 digits instead of 2 digits for the year. When you specify a 4-digit year, the DBCENTURY environment variable has no effect on the distribution scheme. When you specify a 2-digit year, the DBCENTURY environment variable can affect the distribution scheme and can produce unpredictable results. See the "Informix Guide to SQL: Reference" for more information on the DBCENTURY environment variable.
Use the REMAINDER keyword to specify the storage space in which to store valid values that fall outside the specified expression or expressions.
If you do not specify a remainder and a row is inserted or updated such that it no longer belongs to any dbspace, the database server returns an error.
If you use a hash-distribution scheme, the database server distributes the rows as you insert them so that the fragments maintain approximately the same number of rows. In this distribution scheme, the database server can eliminate fragments when it searches for a row because the hash is known internally.
For example, if you have a very large database, as in a data-warehousing environment, you can fragment your tables across disks that belong to different coservers. If you expect to perform a lot of queries that scan most of the data, you can use a system-defined hash-distribution scheme to balance the I/O processing as follows:
This example uses eight coservers with one dbspace defined on each coserver.
You can also specify a dbslice. When you specify a dbslice, the database server fragments the table across the dbspaces that make up the dbslice.
Serial Columns in Hash-Distribution SchemesIf you choose to fragment on a serial column, the only distribution scheme that you can use is a hash-distribution scheme. In addition, the serial column must be the only column in the hashing key.
The following excerpt is a sample CREATE TABLE statement:
You might notice a difference between serial-column values in fragmented and nonfragmented tables. The database server assigns serial values round-robin across fragments so a fragment might contain values from noncontiguous ranges. For example, if there are two fragments, the first serial value is placed in the first fragment, the second serial value is placed in the second fragment, the third value is placed in the first fragment, and so on.
The HYBRID clause allows you to apply two distribution schemes to the same table. You can use a combination of hash- and expression-distribution schemes or a combination of range distribution schemes on a table. This section discusses the hash and expression form of hybrid fragmentation. For more information on range fragmentation, see RANGE Method Clause.
When you specify hybrid fragmentation, the EXPRESSION clause determines the base fragmentation strategy of the table. In this clause, you associate an expression with a set of dbspaces (dbspace, dbslice, or dbspacelist format) to designate where the data is stored. The hash column (or columns) determines the dbspace within the specified set of dbspaces.
When you specify a dbslice, the database server fragments the table across the dbspaces that make up the dbslice. Similarly, if you specify a dbspacelist, the database server fragments the table across the dbspaces specified in that list.
For example, the following table, my_hybrid, distributes rows based on two columns of the table. The value of col1 determines in which dbslice the row belongs. The hash value of col2 determines in which dbspace (within the previously determined dbslice) to insert into.
For more information on an expression-based distribution scheme, see Fragmenting by EXPRESSION.
You can use a range-fragmentation method as a convenient alternative to fragmenting by the EXPRESSION or HYBRID clauses. This method provides a method to implicitly and uniformly distribute data whose fragmentation column values are dense or naturally uniform.
In a range-fragmented table, the database server assigns each dbspace a contiguous, completely bound and non-overlapping range of integer values over one or two columns. In other words, the database server implicitly clusters rows within the fragments based on the range of the values in the fragmentation column.
|
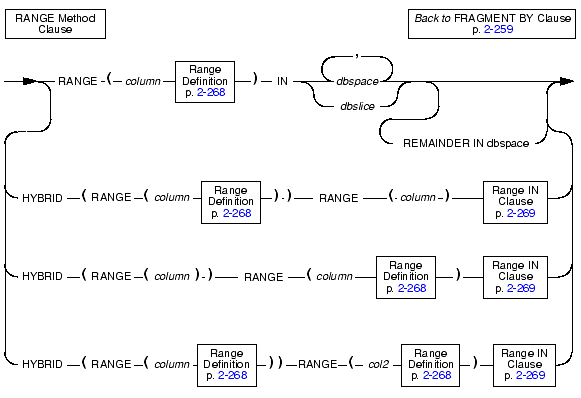
Use the range definition to specify the minimum and maximum values of the entire range.

|
You do not have to specify a minimum value.
The database server uses the minimum and maximum values to determine the exact range of values to allocate for each storage space.
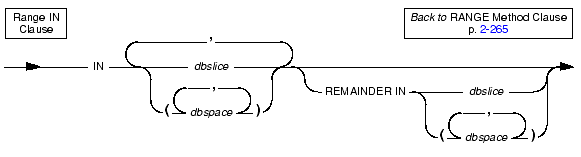
Use the IN clause to specify the storage spaces across which to distribute the data.
|
When you use a range fragmentation method, the number of integral values between the minimum and maximum specified values must be equal to or greater than the number of storage spaces specified so that the database server can allocate non-overlapping contiguous ranges across the dbspaces.
For example, the following code returns an error because the allocations for the range cannot be distributed across all specified dbspaces:
The error for this example occurs because the specified range contains three values (5, 6, and 7), but six dbspaces are specified; three values cannot be distributed across six dbspaces.
Use the REMAINDER keyword to specify the storage space in which to store valid values that fall outside the specified expression or expressions.
If you do not specify a remainder and a row is inserted or updated such that it no longer belongs to any storage space, the database server returns an error.
If you fragment a table with range fragmentation, you cannot perform the following operations on it once it is created:
The following examples illustrate range fragmentation in its simple and hybrid forms.
Simple Range Fragmentation StrategyThe following example shows a simple range fragmentation strategy:
In this example, the database server fragments the table according to the following allocations.
| Storage Space | Holds Values |
|---|---|
| db1 | 100 <= Col1 < 125 |
| db2 | 125 <= Col1 < 150 |
| db3 | 150 <= Col1 < 175 |
| db4 | 175 <= Col1 <200 |
The previous table shows allocations that can also be made with an expression-based fragmentation scheme:
However, as the examples show, the range-fragmentation example requires much less coding to achieve the same results. The same is true for the hybrid-range fragmentation methods in relation to hybrid-expression fragmentation methods.
Column-Major-Range AllocationThe following example demonstrates the syntax for column-major-range allocation, a hybrid-range fragmentation strategy:
This type of fragmentation creates a distribution across dbslices and provides a further subdivision within each dbslice (across the dbspaces in the dbslice) such that when a query specifies a value for col1 (for example, WHERE col1 = 127), the query uniquely identifies a dbspace. To take advantage of the additional subdivision, you must specify more than one dbslice.
Row-Major-Range AllocationThe following example demonstrates the syntax for row-major-range allocation, a hybrid-range fragmentation strategy:
This fragmentation strategy is the counterpart to the column-major-range allocation. The advantages and restrictions are equivalent.
Independent-Range AllocationThe following example demonstrates the syntax for an independent-range allocation, a hybrid-range fragmentation strategy:
In this type of range fragmentation, the two columns are independent, and therefore the range allocations are independent. The range allocation for a dbspace on both columns is the conjunctive combination of the range allocation on each of the two independent columns. This type of fragmentation does not provide subdivisions within either column.
With this type of fragmentation, a query that specifies values for both columns (such as, WHERE col4 = 128 and col5 = 650) uniquely identifies the dbspace at the intersection of the two dbslices identified by the columns independently.
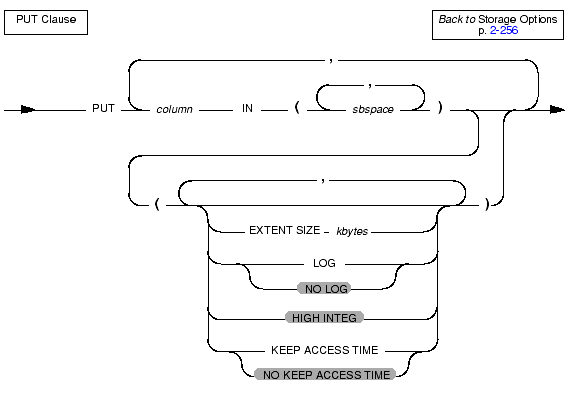
Use the PUT clause to specify the storage spaces and characteristics for each column that will contain smart large objects.
|
A smart large object is contained in a single sbspace. The SBSPACENAME configuration parameter specifies the system default in which smart large objects are created unless you specify another area.
When you specify more than one sbspace, the database server distributes the smart large objects in a round-robin distribution scheme so that the number of smart large objects in each space is approximately equal. The fragmentation scheme is stored in the syscolattribs system catalog table.
When you fragment smart large objects across different sbspaces you can work with smaller sbspaces. If you limit the size of an sbspace, backup and archive operations can perform more quickly. For an example that uses the PUT clause, see Storage Options.
 Important: The PUT clause does not affect the storage of simple-large-object data types (BYTE and TEXT). For information on how to store BYTE and TEXT data, see Large-Object Data Types.
Important: The PUT clause does not affect the storage of simple-large-object data types (BYTE and TEXT). For information on how to store BYTE and TEXT data, see Large-Object Data Types.
Using Options in the PUT Clause
The following table describes the storage options available when you store BLOB and CLOB data.
If a user-defined type or complex type contains more than one large object, the specified large-object storage options apply to all large objects in the type unless the storage options are overridden when the large object is created.
Instead of full logging, you might turn off logging when you load the smart large object initially, and then turn logging back on once the smart large object is loaded.
Use the NO LOG option to turn off logging. If you use NO LOG, you can restore the smart-large-object metadata later to a state in which no structural inconsistencies exist. In most cases, no transaction inconsistencies will exist either, but that result is not guaranteed.
The following statement creates the greek table. The data for the table is fragmented into the dbs1 and dbs2 dbspaces. However, the PUT clause assigns the smart-large-object data in the gamma and delta columns to the sb1 and sb2 sbspaces, respectively. The TEXT data in the eps column is assigned to the blb1 blobspace.
Use the extent size options to define the size of the extents assigned to the table.

|
The following example specifies a first extent of 20 kilobytes and allows the rest of the extents to use the default size:
If you need to revise the extent sizes of a table, you can modify the extent and next-extent sizes in the generated schema files of an unloaded table. For example, to make a database more efficient, you might unload a table, modify the extent sizes in the schema files and then create and load a new table. For information about optimizing extents, see your Administrator's Guide.
Use the LOCK MODE options to specify the locking granularity of the table.
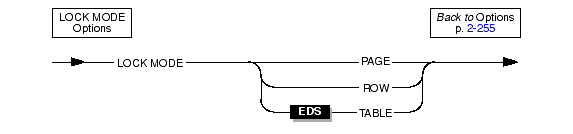
|
You can change the lock mode of an existing table with the ALTER TABLE statement.
A primary access method is a set of routines that perform all of the operations you need to make a table available to a server, such as create, drop, insert, delete, update, and scan. The database server provides a built-in primary access method.
You store and manage a virtual table either outside of the database server in an extspace or inside the database server in an sbspace. (See Storage Options.) You can access a virtual table with SQL statements. Access to a virtual table requires a user-defined primary access method.
DataBlade modules can provide other primary access methods to access virtual tables. When you access a virtual table, the database server calls the routines associated with that access method rather than the built-in table routines. For more information on these other primary access methods, refer to your access method documentation.
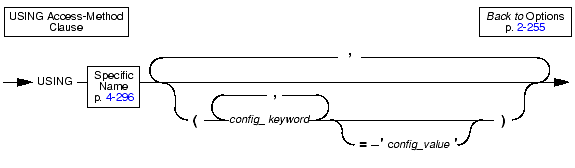
|
For example, if an access method called textfile exists, you can specify that access method with the following syntax:
The access method must already exist.
Use the OF TYPE clause to create a typed table for an object-relational database. A typed table is a table that has a named-row type assigned to it.

|
When you create a typed table, the columns of the table are not named in the CREATE TABLE statement. Instead, the columns are specified when you create the row type. The columns of a typed table correspond to the fields of the named-row type. You cannot add additional columns to a typed table.
For example, suppose you create a named-row type, student_t, as follows:
If a table is assigned the type student_t, the table is a typed table whose columns are of the same name and data type (and in the same order) as the fields of the type student_t.
The following CREATE TABLE statement creates a typed table named students whose type is student_t:
The students table has the following columns:
For more information about row types, refer to the CREATE ROW TYPE statement on page 1-194.
Informix recommends that you use the BLOB or CLOB data types instead of the BYTE or TEXT data types when you create a typed table that contains columns for large objects. For backward compatibility, you can create a named-row type that contains BYTE or TEXT fields and use that type to recreate an existing (untyped) table as a typed table. However, although you can use a row type that contains BYTE or TEXT fields to create a typed table, you cannot use such a row type as a column. You can use a row type that contains BLOB or CLOB fields in both typed tables and columns.
Use the UNDER clause to specify inheritance (that is, define the table as a subtable.) The subtable inherits properties from the supertable which it is under. In addition, you can define new properties specific to the subtable.
Continuing the example shown in OF TYPE Clause, the following statements create a typed table, grad_students, that inherits all of the columns of the students table. In addition, the grad_students table has columns for adviser and field_of_study that correspond to their respective fields in the grad_student_t row type:
When you use the UNDER clause, the subtable inherits the following properties:
Tip: Any heritable attributes that are added to a supertable after subtables have been created will automatically be inherited by existing subtables. You do not need to add all heritable attributes to a supertable before you create its subtables.
Inheritance occurs in one direction only-from supertable to subtable. Properties of subtables are not inherited by supertables.
Restrictions on the Inheritance HierarchyNo two tables in a table hierarchy can have the same type. For example, the final line of the following code sample is illegal because the tables tab2 and tab3 cannot have the same row type (rowtype2):
Constraints, indexes, and triggers are recorded in the system catalog for the supertable, but not for subtables that inherit them. Fragmentation information is recorded for both supertables and subtables.
For more information about inheritance, refer to the Informix Guide to SQL: Tutorial.
The privileges on a table describe both who can access the information in the table and who can create new tables. For more information about privileges, see GRANT.
![]() In an ANSI-compliant database, no default table-level privileges exist. You must grant these privileges explicitly.
In an ANSI-compliant database, no default table-level privileges exist. You must grant these privileges explicitly.
When set to yes, the environment variable NODEFDAC prevents default privileges from being granted to PUBLIC on a new table in a database that is not ANSI compliant.
For information about how to prevent privileges from being granted to PUBLIC, see the NODEFDAC environment variable in the Informix Guide to SQL: Reference. For additional information about privileges, see the Informix Guide to SQL: Tutorial.
When you create a table with unique or primary-key constraints, the database server creates an internal, unique, ascending index for each constraint.
When you create a table with a referential constraint, the database server creates an internal, nonunique, ascending index for each column specified in the referential constraint.
The database server stores this internal index in the same location that the table uses. If you fragment the table, the database server stores the index fragments in the same dbspaces as the table fragments or in some cases, the database dbspace.
If you require an index fragmentation strategy that is independent of the underlying table fragmentation, do not include the constraint when you create the table. Instead, use the CREATE INDEX statement to create a unique index with the desired fragmentation strategy. Then use the ALTER TABLE statement to add the constraint. The new constraint will use the previously defined index.
Important: In a database without logging, detached checking is the only kind of constraint checking available. Detached checking means that constraint checking is performed on a row-by-row basis.
System Catalog Information
When you create a table, the database server adds basic information about the table to the systables system catalog table and column information to syscolumns table. The sysblobs table contains information about the location of dbspaces and simple large objects. The syschunks table in the sysmaster database contains information about the location of smart large objects.
The systabauth, syscolauth, sysfragauth, sysprocauth, sysusers, and sysxtdtypeauth tables contain information about the privileges that various CREATE TABLE options require. The systables, sysxtdtypes, and sysinherits system catalog tables provide information about table types.
Related statements: ALTER TABLE, CREATE INDEX, CREATE DATABASE, CREATE EXTERNAL TABLE, CREATE ROW TYPE, CREATE Temporary TABLE, DROP TABLE, SET Database Object Mode, and SET Transaction Mode
For discussions of database and table creation, including discussions on data types, data-integrity constraints, and tables in hierarchies, see the Informix Guide to Database Design and Implementation.
For information about the system catalog tables that store information about objects in the database, see the Informix Guide to SQL: Reference.
For information about the syschunks table (in the sysmaster database) that contains information about the location of smart large objects, see your Administrator's Reference.