| Informix Guide to SQL: Syntax SQL Statements |
|
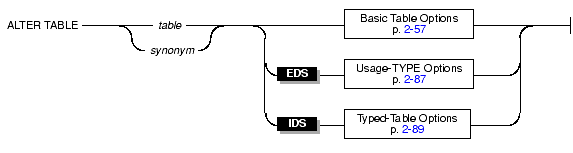
Use the ALTER TABLE statement to modify the definition of a table.
|
Altering a table on which a view depends might invalidate the view.
 Warning: The clauses available with this statement have varying performance implications. Before you undertake alter operations, check corresponding sections in your "Performance Guide" to review effects and strategies.
Warning: The clauses available with this statement have varying performance implications. Before you undertake alter operations, check corresponding sections in your "Performance Guide" to review effects and strategies.
Restrictions
You cannot alter a temporary table. You also cannot alter a violations or diagnostics table. In addition, you cannot add, drop, or modify a column if the table that contains the column has violations and diagnostics tables associated with it.
![]() If a table has range fragmentation, the parts of this statement that you can use are the Usage-TYPE options, and the Lock-Mode clause. All other operations return an error.
If a table has range fragmentation, the parts of this statement that you can use are the Usage-TYPE options, and the Lock-Mode clause. All other operations return an error.
If you have a static or raw table, the only information that you can alter is the usage type of the table. That is, the Usage-TYPE options are the only part of the ALTER TABLE statement that you can use. 
To use the ALTER TABLE statement, you must meet one of the following conditions:
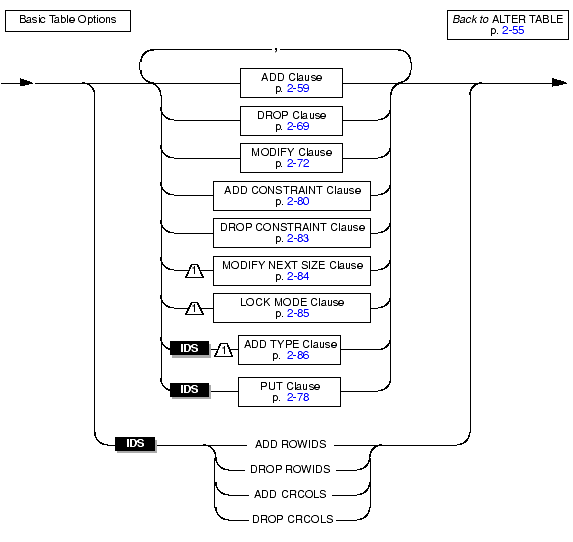
With the ALTER TABLE statement, you can perform basic alter operations such as adding, modifying, or dropping columns and constraints, and changing the extent size and locking granularity of a table. The database server performs the alter operations in the order that you specify. If any of the actions fails, the entire operation is cancelled.
|
![]() You can also associate a table with a named-row type or specify a new storage space to store large-object data.
You can also associate a table with a named-row type or specify a new storage space to store large-object data.
In addition, you can add or drop rowid columns and shadow columns that for Enterprise Replication. However, you cannot specify these options in conjunction with any other alterations.
Use the ADD ROWIDS keywords to add a new column called rowid to a fragmented table. (Fragmented tables do not contain the hidden rowid column by default.)
When you add a rowid column, the database server assigns a unique number to each row that remains stable for the life of the row. The database server creates an index that it uses to find the physical location of the row. After you add the rowid column, each row of the table contains an additional 4 bytes to store the rowid value.
 Tip: Use the ADD ROWIDS clause only on fragmented tables. In nonfragmented tables, the rowid column remains unchanged. Informix recommends that you use primary keys as an access method rather than exploiting the rowid column.
Tip: Use the ADD ROWIDS clause only on fragmented tables. In nonfragmented tables, the rowid column remains unchanged. Informix recommends that you use primary keys as an access method rather than exploiting the rowid column.
For additional information about the rowid column, refer to your
Administrator's Reference.
Use the DROP ROWIDS keywords to drop a rowid column that you added (with either the CREATE TABLE or ALTER FRAGMENT statement) to a fragmented table. You cannot drop the rowid column of a nonfragmented table.
Use the add CRCOLS keywords to create the shadow columns, cdrserver and cdrtime, that Enterprise Replication uses for conflict resolution. You must add these columns before you can use time-stamp or UDR conflict resolution.
For more information, refer to Using the WITH CRCOLS Option and to the Guide to Informix Enterprise Replication.
Use the DROP CRCOLS keywords to drop the cdrserver and cdrtime shadow columns. You cannot drop these columns if Enterprise Replication is in use.
Use the ADD clause to add a column to a table.

|
The following restrictions apply to the ADD clause:
Use the BEFORE option to specify the column before which a new column or list of columns is to be added.
If you do not include the BEFORE option, the database server adds the new column or list of columns to the end of the table definition by default.
In the following example, the BEFORE option directs the database server to add the item_weight column before the total_price column:
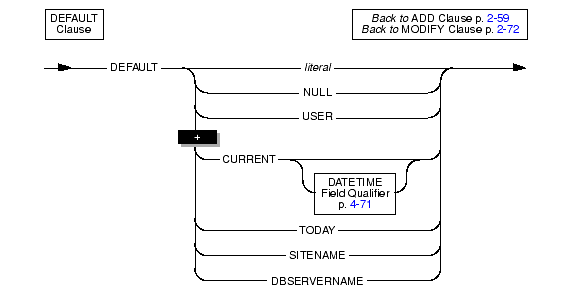
Use the DEFAULT clause to specify the default value that the database server should insert in a column when an explicit value for the column is not specified.
|
You cannot place a default on serial columns.
If the table that you are altering already has rows in it when you add a column that contains a default value, the database server inserts the default value for all pre-existing rows.
For more information about the options of the DEFAULT clause, refer to DEFAULT Clause.
The following example adds a column to the items table. In items, the new column item_weight has a literal default value:
In this example, each existing row in the items table has a default value of 2.00 for the item_weight column.
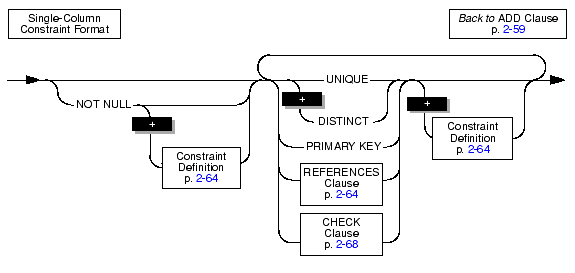
Use the Single-Column Constraint Format to associate constraints with a particular column.
|
You cannot specify a primary-key or unique constraint on a new column if the table contains data. However, in the case of a unique constraint, the table can contain a single row of data. When you want to add a column with a primary-key constraint, the table must be empty when you issue the ALTER TABLE statement.
The following rules apply when you place primary-key or unique constraints on existing columns:
You cannot place a unique constraint on a BYTE or TEXT column, nor can you place referential constraints on these types of columns. You can place a check constraint on a BYTE or TEXT column. However, you can check only for IS NULL, IS NOT NULL, or LENGTH.
When you place a referential constraint on a column or set of columns, and an index already exists on that column or set of columns, the index is upgraded to unique (if possible) and the index is shared.
Using Not-Null Constraints with ADDIf a table contains data, when you add a column with a not-null constraint you must also include a DEFAULT clause. If the table is empty, no additional restrictions exist; that is, you can add a column and apply only the not-null constraint.
The following statement is valid whether or not the table contains data:
![]() Use the Constraint Definition portion of the ALTER TABLE statement to assign a name to a constraint and to set the mode of the constraint to disabled, enabled, or filtering.
Use the Constraint Definition portion of the ALTER TABLE statement to assign a name to a constraint and to set the mode of the constraint to disabled, enabled, or filtering.
![]() In Enterprise Decision Server, use the Constraint Definition portion of the ALTER TABLE statement to assign a name to a constraint.
In Enterprise Decision Server, use the Constraint Definition portion of the ALTER TABLE statement to assign a name to a constraint.

|
| Element | Purpose | Restrictions | Syntax |
|---|---|---|---|
| constraint | Name assigned to the constraint | None. | Identifier, p. 4-205 |
For more information about constraint-mode options, see Choosing a Constraint-Mode Option.
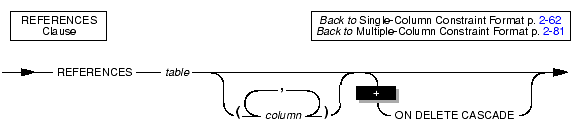
The REFERENCES clause allows you to place a foreign-key reference on a column. The referenced column can be in the same table as the referencing column, or the referenced column can be in a different table in the same database.
|
You must have the REFERENCES privilege to create a referential constraint.
Restrictions on the Referenced ColumnYou must observe the following restrictions on the column variable (the referenced column) in the REFERENCES clause:
If the referenced table is different from the referencing table, you do not need to specify the referenced column; the default column is the primary-key column (or columns) of the referenced table. If the referenced table is the same as the referencing table, you must specify the referenced column.
The following example creates a new column in the cust_calls table, ref_order. The ref_order column is a foreign key that references the order_num column in the orders table.
When you place a referential constraint on a column or set of columns, and a duplicate or unique index already exists on that column or set of columns, the index is shared.
Use the ON DELETE CASCADE option to specify whether you want rows deleted in the child table when corresponding rows are deleted in the parent table. If you do not specify cascading deletes, the default behavior of the database server prevents you from deleting data in a table if other tables reference it.
If you specify this option, later when you delete a row in the parent table, the database server also deletes any rows associated with that row (foreign keys) in a child table. The principal advantage to the cascading deletes feature is that it allows you to reduce the quantity of SQL statements you need to perform delete actions.
For example, in the stores_demo database, the stock table contains the stock_num column as a primary key. The catalog table refers to the stock_num column as a foreign key. The following ALTER TABLE statements drop an existing foreign-key constraint (without cascading delete) and add a new constraint that specifies cascading deletes:
With cascading deletes specified on the child table, in addition to deleting a stock item from the stock table, the delete cascades to the catalog table that is associated with the stock_num foreign key. This cascading delete works only if the stock_num that you are deleting was not ordered; otherwise, the constraint from the items table would disallow the cascading delete. For more information, see Restrictions on DELETE When Tables Have Cascading Deletes.
RestrictionsIf a table has a trigger with a DELETE trigger event, you cannot define a cascading-delete referential constraint on that table. You receive an error when you attempt to add a referential constraint that specifies ON DELETE CASCADE to a table that has a delete trigger.
For information about syntax restrictions and locking implications when you delete rows from tables that have cascading deletes, see Considerations When Tables Have Cascading Deletes.
When you create a referential constraint, the database server places an exclusive lock on the referenced table. The lock is released after you finish with the ALTER TABLE statement or at the end of a transaction (if you are altering a table in a database with transactions, and you are using transactions).
A check constraint designates a condition that must be met before data can be inserted into a column.

|
During an insert or update, if a row evaluates to false for any check constraint defined on a table, the database server returns an error. The database server does not return an error if a row evaluates to null for a check constraint. In some cases, you might wish to use both a check constraint and a NOT NULL constraint.
Check constraints are defined using search conditions. The search condition cannot contain the following items: subqueries, aggregates, host variables, rowids, or user-defined routines. In addition, the search condition cannot contain the following built-in functions: CURRENT, USER, SITENAME, DBSERVERNAME, or TODAY.
You cannot create check constraints for columns across tables. When you are using the ADD or MODIFY clause, the check constraint cannot depend upon values in other columns of the same table. The following example adds a new column, unit_price, to the items table and includes a check constraint that ensures that the entered value is greater than 0:
To create a constraint that checks values in more than one column, use the ADD CONSTRAINT clause. The following example builds a constraint on the column that was added in the previous example. The check constraint now spans two columns in the table.
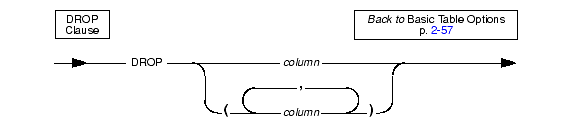
Use the DROP clause to drop one or more columns from a table.
|
You cannot issue an ALTER TABLE DROP statement that would drop every column from the table. At least one column must remain in the table.
You cannot drop a column that is part of a fragmentation strategy.
![]() In Enterprise Decision Server, you cannot use the DROP clause if the table has a dependent GK index.
In Enterprise Decision Server, you cannot use the DROP clause if the table has a dependent GK index.
When you drop a column, all constraints placed on that column are dropped, as described in the following list:
Because any constraints that are associated with a column are dropped when the column is dropped, the structure of other tables might also be altered when you use this clause. For example, if the dropped column is a unique or primary key that is referenced in other tables, those referential constraints also are dropped. Therefore the structure of those other tables is also altered.
In general, when you drop a column from a table, the triggers based on that table remain unchanged. However, if the column that you drop appears in the action clause of a trigger, you can invalidate the trigger.
The following statements illustrate the possible affects on triggers:
After the ALTER TABLE statement, tab2 has only one column. The col1trig trigger is invalidated because the action clause as it is currently defined with values for two columns cannot occur.
If you drop a column that occurs in the triggering column list of an UPDATE trigger, the database server drops the column from the triggering column list. If the column is the only member of the triggering column list, the database server drops the trigger from the table. For more information on triggering columns in an UPDATE trigger, see CREATE TRIGGER.
If a trigger is invalidated when you alter the underlying table, drop and then recreate the trigger.
When you drop a column from a table, the views based on that table remain unchanged. That is, the database server does not automatically drop the corresponding columns from associated views.
The database server does not automatically drop the column because you can change the order of columns in a table by dropping a column and then adding a new column with the same name. In this case, views based on the altered table continue to work. However, they retain their original sequence of columns.
If a view is invalidated when you alter the underlying table, you must rebuild the view.
In Enterprise Decision Server, if you drop a column from a table that has a dependent GK index, all GK indexes on the table that refer to the dropped column are dropped. Any GK indexes on other tables that refer to the dropped column are also dropped.
Use the MODIFY clause to change the data type of a column and the length of a character column, to add or change the default value for a column, and to allow or disallow nulls in a column.

|
![]() In Enterprise Decision Server, you cannot use the MODIFY clause if the table has a dependent GK index.
In Enterprise Decision Server, you cannot use the MODIFY clause if the table has a dependent GK index.
![]() You cannot change the data type of a column to be a collection type or a row type.
You cannot change the data type of a column to be a collection type or a row type.
When you modify a column, all attributes previously associated with that column (that is, default value, single-column check constraint, or referential constraint) are dropped. When you want certain attributes of the column to remain, such as PRIMARY KEY, you must re-specify those attributes. For example, if you are changing the data type of an existing column, quantity, to SMALLINT, and you want to keep the default value (in this case, 1) and non-null attributes for that column, you can issue the following ALTER TABLE statement:
Tip: Both attributes are specified again in the modify clause.
When you modify a column that has column constraints associated with it, the following constraints are dropped:
For example, if you modify a column that has a unique constraint, the unique constraint is dropped. If this column was referenced by columns in other tables, those referential constraints are also dropped. In addition, if the column is part of a multiple-column primary-key or unique constraint, the multiple-column constraints are not dropped, but any referential constraints placed on the column by other tables are dropped. For example, a column is part of a multiple-column primary-key constraint. This primary key is referenced by foreign keys in two other tables. When this column is modified, the multiple-column primary-key constraint is not dropped, but the referential constraints placed on it by the two other tables are dropped.
The characteristics of the object you are attempting to modify can affect how you handle your modifications.
You can use the MODIFY clause to change a BYTE column to a TEXT column, and vice versa. However, you cannot use the MODIFY clause to change a BYTE or TEXT column to any other type of column, and vice versa.
![]() You can also use the MODIFY clause to change a BYTE column to a BLOB column and a TEXT column to a CLOB column.
You can also use the MODIFY clause to change a BYTE column to a BLOB column and a TEXT column to a CLOB column.
You can use the MODIFY clause to reset the next value of a serial column. You cannot set the next value below the current maximum value in the column because that action can cause the database server to generate duplicate numbers. However, you can set the next value to any value higher than the current maximum, which creates gaps in the sequence.
The following example sets the next serial number to 1000.
As an alternative, you can use the INSERT statement to create a gap in the sequence of a serial column. For more information, see Inserting Values into Serial Columns.
You can set the initial serial number or modify the next serial number for a row-type field with the MODIFY clause of the ALTER TABLE statement. (You cannot set the start number for a serial field when you create a row type.)
Suppose you have row types parent, child1, child2, and child3.
You then create corresponding typed tables:
To change the next serial and next serial 8 numbers to 75, you can enter the following command:
When the ALTER TABLE statement executes, the database server updates corresponding serial columns in the child1, child2, and child3 tables.
When you use the MODIFY clause, you can also alter the structure of other tables. If the modified column is referenced by other tables, those referential constraints are dropped. You must add those constraints to the referencing tables again, using the ALTER TABLE statement.
When you change the data type of an existing column, all data is converted to the new data type, including numbers to characters and characters to numbers (if the characters represent numbers). The following statement changes the data type of the quantity column:
When a primary-key or unique constraint exists, however, conversion takes place only if it does not violate the constraint. If a data-type conversion would result in duplicate values (by changing FLOAT to SMALLFLOAT, for example, or by truncating CHAR values), the ALTER TABLE statement fails.
You can modify an existing column that formerly permitted nulls to disallow nulls, provided that the column contains no null values. To do this, specify MODIFY with the same column name and data type and the NOT NULL keywords. The NOT NULL keywords create a not-null constraint on the column.
You can modify an existing column that did not permit nulls to permit nulls. To do this, specify MODIFY with the column name and the existing data type, and omit the NOT NULL keywords. The omission of the NOT NULL keywords drops the not-null constraint on the column. If a unique index exists on the column, you can remove it using the DROP INDEX statement.
An alternative method of permitting nulls in an existing column that did not permit nulls is to use the DROP CONSTRAINT clause to drop the not-null constraint on the column.
If you use the MODIFY clause to add a constraint in the enabled mode and receive an error message because existing rows would violate the constraint, you can take the following steps to add the constraint successfully:
In Enterprise Decision Server, when you modify a column, all GK indexes that reference the column are dropped if the column is used in the GK index in a way that is incompatible with the new data type of the column.
For example, if a numeric column is changed to a character column, any GK indexes involving that column are dropped if they involve arithmetic expressions.
If you modify a column that appears in the triggering column list of an UPDATE trigger, the trigger is unchanged.
When you modify a column in a table, the triggers based on that table remain unchanged. However, the column modification might invalidate the trigger.
The following statements illustrate the possible affects on triggers:
After the ALTER TABLE statement, column i4 accepts only character values. Because character columns accept only values enclosed in quotation marks, the action clause of the col1trig trigger is invalidated.
If a trigger is invalidated when you modify the underlying table, drop and then recreate the trigger.
When you modify a column in a table, the views based on that table remain unchanged. If a view is invalidated when you alter the underlying table, you must rebuild the view.
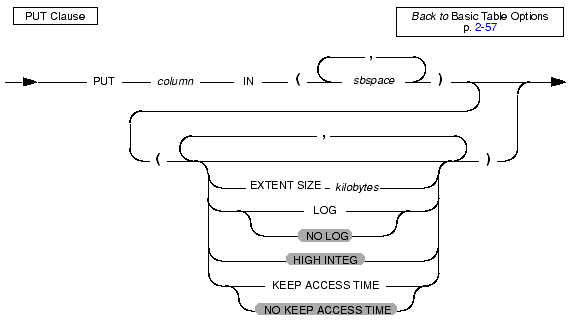
Use the PUT clause to specify the storage space (an sbspace) for a column that contains smart large objects. You can use this clause to specify storage characteristics for a new column or replace the storage characteristics of an existing column.
|
When you modify the storage characteristics of an existing column, all attributes previously associated with the storage space for that column are dropped. When you want certain attributes to remain, you must respecify those attributes. For example, to retain logging, you must respecify the log keyword.
When you modify the storage characteristics of a column that holds smart large objects, the database server does not alter smart large objects that already exist. The database server applies the new storage characteristics to only those smart large objects that are inserted after the ALTER TABLE statement takes effect.
For more information on the available storage characteristics, refer to the counterpart of this section in the CREATE TABLE statement, PUT Clause. For a discussion of large-object characteristics, refer to Large-Object Data Types.
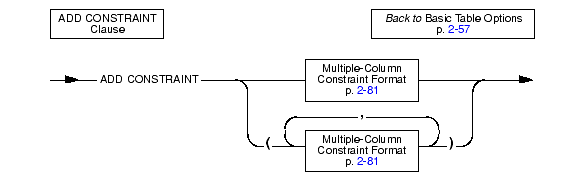
Use the ADD CONSTRAINT clause to specify a constraint on a new or existing column or on a set of columns.
|
For example, to add a unique constraint to the fname and lname columns of the customer table, use the following statement:
To name the constraint, change the preceding statement, as the following example shows:
When you do not provide a constraint name, the database server provides one. You can find the name of the constraint in the sysconstraints system catalog table. For more information about the sysconstraints system catalog table, see the Informix Guide to SQL: Reference.
Use the Multiple-Column Constraint Format option to assign a constraint to one column or a set of columns.

|
A constraint that involves multiple columns can include no more than 16 column names.
You can assign a name to the constraint and set its mode by means of Constraint Definition.
When you place a primary-key or unique constraint on a column or set of columns, those columns must contain unique values.
When you place a primary-key or unique constraint on a column or set of columns, the database server checks for existing constraints and indexes.
When you place a referential constraint on a column or set of columns, and an index already exists on that column or set of columns, the index is shared.
When you own the table or have the Alter privilege on the table, you can create a check, primary-key, or unique constraint on the table and specify yourself as the owner of the constraint. To add a referential constraint, you must have the References privilege on either the referenced columns or the referenced table. When you have the DBA privilege, you can create constraints for other users.
If you use the ADD CONSTRAINT clause to add a constraint in the enabled mode and receive an error message because existing rows would violate the constraint, you can follow a procedure to add the constraint successfully. See Adding a Constraint When Existing Rows Violate the Constraint.
Use the DROP CONSTRAINT clause to drop a named constraint.
|
| Element | Purpose | Restrictions | Syntax |
|---|---|---|---|
| constraint | Name of the constraint that you want to drop | The constraint must exist. | Database Object Name, p. 4-50 |
To drop an existing constraint, specify the DROP CONSTRAINT keywords and the name of the constraint. The following statement is an example of dropping a constraint:
If a constraint name is not specified when the constraint is created, the database server generates the name. You can query the sysconstraints system catalog table for the name and owner of a constraint. For example, to find the name of the constraint placed on the items table, you can issue the following statement:
When you drop a primary-key or unique constraint that has a corresponding foreign key, the referential constraints are dropped. For example, if you drop the primary-key constraint on the order_num column in the orders table and order_num exists in the items table as a foreign key, that referential relationship is also dropped.
Use the MODIFY NEXT SIZE clause to change the size of new extents.

|
If you want to specify an extent size of 32 kilobytes, use a statement such as the one in the following example:
When you use this clause, the size of existing extents does not change. You cannot change the size of existing extents without unloading all of the data.
To change the size of existing extents, you must unload all of the data, modify the extent and next-extent sizes in the CREATE TABLE statement of the database schema, re-create the database, and reload the data. For information about optimizing extents, see your Administrator's Guide.
Use the LOCK MODE keywords to change the locking granularity of a table.
|
Use the ADD TYPE clause to convert a table that is not based on a named-row type into a typed table.

|
| Element | Purpose | Restrictions | Syntax |
|---|---|---|---|
| row_type_name | Name of the row type being added to the table | The field types of this row type must match the column types of the table. | Data Type, p. 4-53 |
When you use the ADD TYPE clause, you assign a named-row type to a table whose columns match the fields of the row type.
You cannot add a type to a fragmented table that has rowids.
You cannot combine the ADD TYPE clause with any clause that changes the structure of the table. That is, you cannot use an ADD, DROP, or MODIFY clause in the same statement as the ADD TYPE clause.
Tip: To change the data type of a column, use the MODIFY clause. The ADD TYPE clause does not allow you to change column data types.
When you add a named-row type to a table, be sure that:
You must have the Usage privilege to add a type to a table.
In Enterprise Decision Server, use the Usage-TYPE options to specify that the table have particular characteristics that can improve various bulk operations on it.

|
Other than the default option (STANDARD) that is used for OLTP databases, these Usage-TYPE options are used primarily to improve performance in data warehousing databases.
A table can have any of the following usage characteristics.
For a more detailed description, refer to your Administrator's Guide.
The usage-TYPE options have the following restrictions:
In Dynamic Server, the database server performs the actions in the ALTER TABLE statement in the order that you specify. If any of the actions fails, the entire operation is cancelled.

|
The following considerations apply to tables that are part of inheritance hierarchies:
Use the DROP TYPE option to drop the type from a table. DROP TYPE removes the association between a table and a named-row type. You must drop the type from a typed table before you can modify, drop, or change the data type of a column in the table.
If a table is part of a table hierarchy, you cannot drop its type unless it is the last subtype in the hierarchy. That is, you can only drop a type from a table if that table has no subtables. When you drop the type of a subtable, it is automatically removed from the hierarchy. The table rows are deleted from all indexes defined by its supertables.
Related statements: CREATE TABLE, DROP TABLE, LOCK TABLE, and SET Database Object Mode
For discussions of data-integrity constraints and the ON DELETE CASCADE option, see the Informix Guide to SQL: Tutorial.
For a discussion of database and table creation, see the Informix Guide to Database Design and Implementation.
For information on how to maximize performance when you make table modifications, see your Performance Guide.