| Informix Guide to SQL: Syntax SQL Statements |
|
Use the INSERT statement to insert one or more new rows into a table or view or one or more elements into an SPL or ESQL/C collection variable.

|
To insert data into a table, you must either own the table or have the Insert privilege for the table (see GRANT). To insert data into a view, you must have the required Insert privilege, and the view must meet the requirements explained in "Inserting Rows Through a View."
If you insert data into a table that has data integrity constraints associated with it, the inserted data must meet the constraint criteria. If it does not, the database server returns an error.
If you are using effective checking, and the checking mode is set to IMMEDIATE, all specified constraints are checked at the end of each INSERT statement. If the checking mode is set to DEFERRED, all specified constraints are not checked until the transaction is committed.
If you do not explicitly specify one or more columns, data is inserted into columns using the column order that was established when the table was created or last altered. The column order is listed in the syscolumns system catalog table.
![]() In ESQL/C, you can use the DESCRIBE statement with an INSERT statement to determine the column order and the data type of the columns in a table.
In ESQL/C, you can use the DESCRIBE statement with an INSERT statement to determine the column order and the data type of the columns in a table. 
The number of columns specified in the INSERT INTO clause must equal the number of values supplied in the VALUES clause or by the SELECT statement, either implicitly or explicitly. If you specify columns, the columns receive data in the order in which you list them. The first value following the VALUES keyword is inserted into the first column listed, the second value is inserted into the second column listed, and so on.
Use the AT clause to insert LIST elements at a specified position in a collection variable. By default, Dynamic Server adds a new element at the end of a LIST collection. If you specify a position that is greater than the number of elements in the list, the database server adds the element to the end of the list. You must specify a position value of at least 1 because the first element in the list is at position 1.
The following SPL example shows how you can insert a value at a specific position in a list:
Suppose that before this INSERT, a_list contained the elements {1,8,4,5,2}. After this INSERT, a_list contains the elements {1,8,9,4,5,2}. The new element 9 was inserted at position 3 in the list. For more information on inserting values into collection variables, see Collection Derived Table.
You can insert data through a single-table view if you have the Insert privilege on the view. To do this, the defining SELECT statement can select from only one table, and it cannot contain any of the following components:
Columns in the underlying table that are unspecified in the view receive either a default value or a null value if no default is specified. If one of these columns does not specify a default value, and a null value is not allowed, the insert fails.
You can use data-integrity constraints to prevent users from inserting values into the underlying table that do not fit the view-defining SELECT statement. For further information, see WITH CHECK OPTION Keywords.
If several users are entering sensitive information into a single table, the built-in USER function can limit their view to only the specific rows that each user inserted. The following example contains a view and an INSERT statement that achieve this effect:
In ESQL/C, if you associate a cursor with an INSERT statement, you must use the OPEN, PUT, and CLOSE statements to carry out the INSERT operation. For databases that have transactions but are not ANSI-compliant, you must issue these statements within a transaction.
If you are using a cursor that is associated with an INSERT statement, the rows are buffered before they are written to the disk. The insert buffer is flushed under the following conditions:
When the insert buffer is flushed, the client processor performs appropriate data conversion before it sends the rows to the database server. When the database server receives the buffer, it converts any user-defined data types and then begins to insert the rows one at a time into the database. If an error is encountered while the database server inserts the buffered rows into the database, any buffered rows that follow the last successfully inserted rows are discarded.
If you are inserting rows into a database without transactions, you must take explicit action to restore inserted rows after a failure. For example, if the INSERT statement fails after you insert some rows, the successfully inserted rows remain in the table. You cannot recover automatically from a failed insert.
If you are inserting rows into a database with transactions, and you are using explicit transactions, use the ROLLBACK WORK statement to undo the insertion. If you do not execute BEGIN WORK before the insert, and the insert fails, the database server automatically rolls back any database modifications made since the beginning of the insert.
![]() If you are inserting rows into an ANSI-compliant database, transactions are implicit, and all database modifications take place within a transaction. In this case, if an INSERT statement fails, use the ROLLBACK WORK statement to undo the insertions.
If you are inserting rows into an ANSI-compliant database, transactions are implicit, and all database modifications take place within a transaction. In this case, if an INSERT statement fails, use the ROLLBACK WORK statement to undo the insertions.
If you are using an explicit transaction, and the update fails, the database server automatically undoes the effects of the update.
![]() If you are using Enterprise Decision Server, tables that you create with the RAW usage type are never logged. Thus, raw tables are not recoverable, even though the database uses logging. For information about raw tables, refer to the Informix Guide to SQL: Reference.
If you are using Enterprise Decision Server, tables that you create with the RAW usage type are never logged. Thus, raw tables are not recoverable, even though the database uses logging. For information about raw tables, refer to the Informix Guide to SQL: Reference.
Rows that you insert with a transaction remain locked until the end of the transaction. The end of a transaction is either a COMMIT WORK statement, where all modifications are made to the database, or a ROLLBACK WORK statement, where none of the modifications are made to the database. If many rows are affected by a single INSERT statement, you can exceed the maximum number of simultaneous locks permitted. To prevent this situation, either insert fewer rows per transaction or lock the page (or the entire table) before you execute the INSERT statement.

|
When you use the VALUES clause, you can insert only one row at a time. Each value that follows the VALUES keyword is assigned to the corresponding column listed in the INSERT INTO clause (or in column order if a list of columns is not specified).
If you are inserting a quoted string into a column, the maximum length of the string is 256 bytes. If you insert a quoted string that is longer than 256 bytes, the database server returns an error.
![]() In ESQL/C, if you are using variables, you can insert quoted strings longer than 256 bytes into a table.
In ESQL/C, if you are using variables, you can insert quoted strings longer than 256 bytes into a table.
For discussions on the keywords that you can use in the VALUES clause, refer to Constant Expressions.
When you use the INSERT statement, the value that you insert into a column does not have to be of the same data type as the column that receives it. However, these two data types must be compatible. Two data types are compatible if the database server has some way to cast one data type to another. A cast is the mechanism by which the database server converts one data type to another.
The database server makes every effort to perform data conversion. If the data cannot be converted, the INSERT operation fails.
Data conversion also fails if the target data type cannot hold the value that is specified. For example, you cannot insert the integer 123456 into a column defined as a SMALLINT data type because this data type cannot hold a number that large.
For a summary of the casting that the database server provides, see the Informix Guide to SQL: Reference. For information on how to create a user-defined cast, see the CREATE CAST statement in this manual and Extending Informix Dynamic Server 2000.
You can insert consecutive numbers, explicit values, or explicit values that reset the serial sequence value in a serial column:
Null values are not allowed in serial columns.
![]() If you are inserting a serial value into a table that is part of a table hierarchy, the database server updates all tables in the hierarchy that contain the serial counter with the value that you insert (either a zero (0) for the next highest value or a specific number).
If you are inserting a serial value into a table that is part of a table hierarchy, the database server updates all tables in the hierarchy that contain the serial counter with the value that you insert (either a zero (0) for the next highest value or a specific number).
Some opaque data types require special processing when they are inserted. For example, if an opaque data type contains spatial or multirepresentational data, it might provide a choice of how to store the data: inside the internal structure or, for very large objects, in a smart large object.
This processing is accomplished by calling a user-defined support function called assign(). When you execute the INSERT statement on a table whose rows contains one of these opaque types, the database server automatically invokes the assign() function for the type. The assign() function can make the decision of how to store the data. For more information about the assign() support function, see Extending Informix Dynamic Server 2000.
You can use the VALUES clause to insert values into a collection column. For more information, see Collection Constructors.
![]() You can also use a collection variable to insert values into a collection column. With a collection variable you can insert one or more individual elements in a collection. For more information, see Collection Derived Table.
You can also use a collection variable to insert values into a collection column. With a collection variable you can insert one or more individual elements in a collection. For more information, see Collection Derived Table.
Regardless of what method you use to insert values into a collection column, you cannot insert null elements into the collection column. Thus expressions that you use cannot evaluate to null. If the collection that you are attempting to insert contains a null element, the database server returns an error.
ExampleFor example, suppose you define the tab1 table as follows:
The following INSERT statement inserts a row into tab1:
The collection column, list1, in this example has three elements. Each element is an unnamed row type with an INTEGER field and a CHAR(5) field. The first element is composed of two literal values, an integer (1) and a quoted string (abcde). The second and third elements also use a quoted string to indicate the value for the second field. However, they each designate the value for the first field with an expression rather than a literal value.
You can use the VALUES clause to insert literal and nonliteral values in a named row type or unnamed row type column. For example, suppose you define the following named row type and table:
The following INSERT statement inserts literal values in the name and address columns of the employee table:
The INSERT statement uses ROW constructors to generate values for the name column (an unnamed row type) and the address column (a named row type). When you specify a value for a named row type, you must use the CAST AS keyword or the double colon (::) operator, in conjunction with the name of the named row type, to cast the value to the named row type.
For more information on the syntax for ROW constructors, see Constructor Expressions in the Expression segment. For information on literal values for named row types and unnamed row types, see Literal Row.
![]() You can use ESQL/C host variables to insert non-literal values as:
You can use ESQL/C host variables to insert non-literal values as:
When you use a row variable in the VALUES clause, the row variable must contain values for each field value. For information on how to insert values in a row variable, see Inserting into a Row Variable.
You can insert any type of expression except a column expression into a column. For example, you can insert built-in functions that return the current date, date and time, login name of the current user, or database server name where the current database resides.
The TODAY keyword returns the system date. The CURRENT keyword returns the system date and time. The USER keyword returns a string that contains the login account name of the current user. The SITENAME or DBSERVERNAME keyword returns the database server name where the current database resides. The following example shows how to use built-in functions to insert data:
For more information, see Expression.
When you execute an INSERT statement, a null value is inserted into any column for which you do not provide a value as well as for all columns that do not have default values associated with them, which are not listed explicitly. You also can use the NULL keyword to indicate that a column should be assigned a null value. The following example inserts values into three columns of the orders table:
In this example, a null value is explicitly entered in the order_date column, and all other columns of the orders table that are not explicitly listed in the INSERT INTO clause are also filled with null values.
As indicated in the diagram for INSERT, not all clauses and options of the SELECT statement are available for you to use in an INSERT statement.
The following SELECT clauses and options are not supported:
For a complete description of SELECT syntax and usage, see SELECT.
If this statement has a WHERE clause that does not return rows, sqlca returns SQLNOTFOUND (100) for ANSI-compliant databases. In databases that are not ANSI compliant, sqlca returns (0). When you insert as a part of a multistatement prepare, and no rows are inserted, sqlca returns SQLNOTFOUND (100) for both ANSI databases and databases that are not ANSI compliant.
![]() If you are inserting values into a supertable in a table hierarchy, the subquery can reference a subtable.
If you are inserting values into a supertable in a table hierarchy, the subquery can reference a subtable.
If you are inserting values into a subtable in a table hierarchy, the subquery can reference the supertable if it references only the supertable. That is, the subquery must use the SELECTFROM ONLY (supertable)syntax.
In Enterprise Decision Server, when you create a SELECT statement as a part of a load or unload operation that involves an external table, keep the following restrictions in mind:
When you move data from a database into an external table, the SELECT statement must define all columns in the external table. The SELECT statement must not contain a FIRST, FOR UPDATE, INTO, INTO SCRATCH, or INTO TEMP clause. However, you can use an ORDER BY clause to produce files that are ordered within themselves.
In ESQL/C, you can use the INSERT statement to handle situations where you need to write code that can insert data whose structure is unknown at the time you compile. For more information, refer to the dynamic management section of the Informix ESQL/C Programmer's Manual.
You can specify the EXECUTE FUNCTION (or EXECUTE PROCEDURE) statement to insert values that a user-defined function returns.
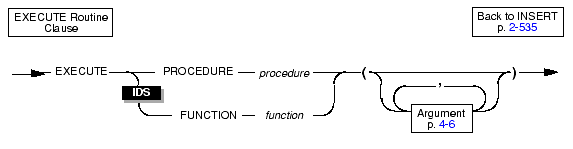
|
When you use a user-defined function to insert column values, the return values of the function must have a one-to-one correspondence with the listed columns. That is, each value that the function returns must be of the data type expected by the corresponding column in the column list.
![]() For backward compatibility, you can use the EXECUTE PROCEDURE keywords to execute an SPL function that was created with the CREATE PROCEDURE statement.
For backward compatibility, you can use the EXECUTE PROCEDURE keywords to execute an SPL function that was created with the CREATE PROCEDURE statement.
If the called SPL routine scans or updates the target table of the insert, the database returns an error. That is, the SPL routine cannot select data from the table into which you are inserting rows.
If a called SPL routine contains certain SQL statements, the database server returns an error. For information on which SQL statements cannot be used in an SPL routine that is called within a data manipulation statement, see Restrictions on an SPL Routine Called in a Data Manipulation Statement.
![]() An SPL function can return one or more values. Make sure that the number of values that the function returns matches the number of columns in the table or the number of columns that you list in the column list of the INSERT statement. The columns into which you insert the values must have compatible data types with the values that the SPL function returns.
An SPL function can return one or more values. Make sure that the number of values that the function returns matches the number of columns in the table or the number of columns that you list in the column list of the INSERT statement. The columns into which you insert the values must have compatible data types with the values that the SPL function returns.
![]() An external function can only return one value. Make sure that you specify only one column in the column list of the INSERT statement. This column must have a compatible data type with the value that the external function returns.The external function can be an iterator function.
An external function can only return one value. Make sure that you specify only one column in the column list of the INSERT statement. This column must have a compatible data type with the value that the external function returns.The external function can be an iterator function.
The following example shows how to insert data into a temporary table called result_tmp in order to output to a file the results of a user-defined function (f_one) that returns multiple rows.
 Inserting into a Row Variable
Inserting into a Row Variable The INSERT statement does not support a row variable in the Collection Derived Table segment. However, you can use the UPDATE statement to insert new field values into a row variable. For example, the following ESQL/C code fragment inserts a new row into the rectangles table (which Inserting Values into Row-Type Columns defines):
For more information, see Updating a Row Variable.
Related statements: CLOSE, CREATE EXTERNAL TABLE, DECLARE, DESCRIBE, EXECUTE, FLUSH, FOREACH, OPEN, PREPARE, PUT, and SELECT
For a task-oriented discussion of inserting data into tables and for information on how to access row and collections with SPL variables, see the Informix Guide to SQL: Tutorial.
For a discussion of the GLS aspects of the INSERT statement, see the Informix Guide to GLS Functionality.
For information on how to access row and collections with ESQL/C host variables, see the chapter on complex types in the Informix ESQL/C Programmer's Manual.