| Informix Guide to SQL: Syntax SQL Statements |
|
Use the SELECT statement to query a database or the contents of an SPL or ESQL/C collection variable.
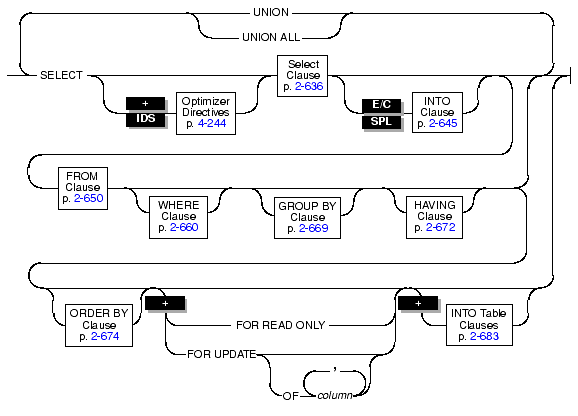
|
You can query the tables in the current database, a database that is not current, or a database that is on a different database server from your current database.
The SELECT statement includes many basic clauses. Each clause is described in the following list.
The SELECT clause contains the list of database objects or expressions to be selected, as shown in the following diagram
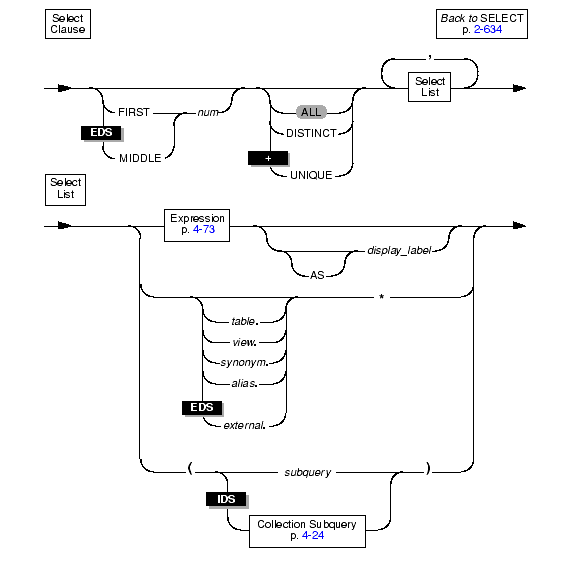
|
In the SELECT clause, specify exactly what data is being selected as well as whether you want to omit duplicate values.
The FIRST option allows you to specify a maximum number of rows to retrieve that match conditions specified in the SELECT statement. Rows that match the selection criteria, but fall outside the specified number, are not returned.
The following example retrieves at most 10 rows from a table:
When you use this option with an ORDER BY clause, you can retrieve the first number of rows according to the order criteria. For example, the following query finds the ten highest-paid employees.
![]() If you are using Enterprise Decision Server, you can also use the FIRST option to select the first rows that result from a union query. In the following example, the FIRST option is applied to the result of the UNION expression.
If you are using Enterprise Decision Server, you can also use the FIRST option to select the first rows that result from a union query. In the following example, the FIRST option is applied to the result of the UNION expression.

The FIRST option is not allowed in the following situations:

Although FiRST is a keyword, the database server can also interpret it as a column name. If an integer does not follow the keyword, the database server interprets FIRST as the name of a column. For example, if a table has columns first, second, and third, the following query would return data from the column named first:
The MIDDLE option, like the FIRST option, allows you to specify a maximum number of rows to retrieve that match conditions specified in the SELECT statement. However, whereas the FIRST option returns the first number of specified rows that match the selection criteria, the MIDDLE option returns the middle number of rows.
The syntax and restrictions for this option are the same as those for the FIRST option. For more information see Using the FIRST Option.
You can apply the ALL, UNIQUE, or DISTINCT keywords to indicate whether duplicate values are returned, if any exist. If you do not specify any keywords, all the rows are returned by default.
For example, the following query lists the stock_num and manu_code of all items that have been ordered, excluding duplicate items:
You can use the DISTINCT or UNIQUE keywords once in each level of a query or subquery. For example, the following query uses DISTINCT in both the query and the subquery:
You can use any basic type of expression (column, constant, built-in function, aggregate function, and user-defined routine), or combination thereof, in the select list. The expression types are described in Expression.
The following sections present examples of using each type of simple expression in the select list.
You can combine simple numeric expressions by connecting them with arithmetic operators for addition, subtraction, multiplication, and division. However, if you combine a column expression and an aggregate function, you must include the column expression in the GROUP BY clause.
You cannot use variable names (for example, a host variable in an ESQL/C application) in the select list by themselves. You can include a variable name in the select list, however, if an arithmetic or concatenation operator connects it to a constant.
Selecting ColumnsColumn expressions are the most commonly used expressions in a SELECT statement. For a complete description of the syntax and use of column expressions, see Column Expressions.
The following examples show column expressions within a select list:
If you include a constant expression in the select list, the same value is returned for each row that the query returns. For a complete description of the syntax and use of constant expressions, see Constant Expressions.
The following examples show constant expressions within a select list:
A built-in function expression uses a function that is evaluated for each row in the query. All built-in function expressions require arguments. This set of expressions contains the time functions and the length function when they are used with a column name as an argument.
The following examples show built-in function expressions within a select list:
An aggregate function returns one value for a set of queried rows. The aggregate functions take on values that depend on the set of rows that the WHERE clause of the SELECT statement returns. In the absence of a WHERE clause, the aggregate functions take on values that depend on all the rows that the FROM clause forms.
The following examples show aggregate functions in a select list:
User-defined functions extend the range of functions that are available to you and allow you to perform a subquery on each row that you select.
The following example calls the get_orders user-defined function for each customer_num and displays the output of the function under the n_orders label:
![]() If a called SPL routine contains certain SQL statements, the database server returns an error. For information on which SQL statements cannot be used in an SPL routine that is called within a data manipulation statement, see Restrictions on an SPL Routine Called in a Data Manipulation Statement.
If a called SPL routine contains certain SQL statements, the database server returns an error. For information on which SQL statements cannot be used in an SPL routine that is called within a data manipulation statement, see Restrictions on an SPL Routine Called in a Data Manipulation Statement.
For the complete syntax of user-defined function expressions, see User-Defined Functions.
Selecting Expressions That Use Arithmetic OperatorsYou can combine numeric expressions with arithmetic operators to make complex expressions. You cannot combine expressions that contain aggregate functions with column expressions. The following examples show expressions that use arithmetic operators within a select list:
You can select a particular field of a row-type column (named or unnamed row type) with dot notation, which uses a period (.) as a separator between the row and field names. For example, suppose you have the following table structure:
The following expressions are valid in the select list:
You can also enter an asterisk in place of a field name to signify that all fields of the row-type column are to be selected. For example, if the my_tab table has a row-type column named rowcol that contains four fields, the following SELECT statement retrieves all four fields of the rowcol column:
You can also retrieve all fields from a row-type column by specifying the column name without any dot notation. The following SELECT statement has the same effect as the preceding SELECT statement:
You can use dot notation not only with row-type columns but with expressions that evaluate to row-type values. For more information on the use of dot notation with row-type columns and expressions, see Column Expressions in the Expression segment.
You can assign a display label to any column in your select list.
![]() In DB-Access, a display label appears as the heading for that column in the output of the SELECT statement.
In DB-Access, a display label appears as the heading for that column in the output of the SELECT statement.
![]() In ESQL/C, the value of display_label is stored in the sqlname field of the sqlda structure. For more information on the sqlda structure, see the Informix ESQL/C Programmer's Manual.
In ESQL/C, the value of display_label is stored in the sqlname field of the sqlda structure. For more information on the sqlda structure, see the Informix ESQL/C Programmer's Manual.
If your display label is also an SQL reserved word, you can use the AS keyword with the display label to clarify the use of the word. If you want to use the word UNITS, YEAR, MONTH, DAY, HOUR, MINUTE, SECOND, or FRACTION as your display label, you must use the AS keyword with the display label. The following example shows how to use the AS keyword with minute as a display label:
For a list of SQL reserved words, see Appendix A, Reserved Words for Dynamic Server.
Usage Restrictions with Certain Database ObjectsIf you are creating a temporary table, you must supply a display label for any columns that are not simple column expressions. The display label is used as the name of the column in the temporary table.
If you are using the SELECT statement in creating a view, do not use display labels. Specify the desired label names in the CREATE VIEW column list instead.
Use the INTO clause in an SPL routine or an ESQL/C program to specify the program variables or host variables to receive the data that the SELECT statement retrieves. The following diagram shows the syntax of the INTO clause.
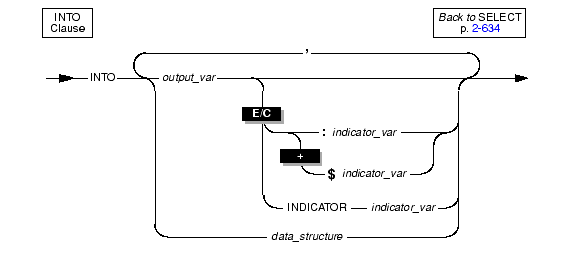
|
You must specify an INTO clause with SELECT to name the variables that receive the values that the query returns. If the query returns more than one value, the values are returned into the list of variables in the order in which you specify them.
If the SELECT statement stands alone (that is, it is not part of a DECLARE statement and does not use the INTO clause), it must be a singleton SELECT statement. A singleton SELECT statement returns only one row.
The following example shows a singleton SELECT statement in ESQL/C:
![]() In an SPL routine, if a SELECT returns more than one row, you must use the FOREACH statement to access the rows individually. The INTO clause of the SELECT statement holds the fetched values. For more information, see FOREACH.
In an SPL routine, if a SELECT returns more than one row, you must use the FOREACH statement to access the rows individually. The INTO clause of the SELECT statement holds the fetched values. For more information, see FOREACH.
In ESQL/C, if the possibility exists that data returned from the SELECT statement is null, use an indicator variable in the INTO clause. For more information about indicator variables, see the Informix ESQL/C Programmer's Manual.
If the SELECT statement returns more than one row, you must use a cursor in a FETCH statement to fetch the rows individually. You can put the INTO clause in the FETCH statement rather than in the SELECT statement, but you should not put it in both.
The following ESQL/C code examples show different ways you can use the INTO clause. As both examples show, first you must use the DECLARE statement to declare a cursor.
In ESQL/C, you cannot prepare a query that has an INTO clause. You can prepare the query without the INTO clause, declare a cursor for the prepared query, open the cursor, and then use the FETCH statement with an INTO clause to fetch the cursor into the program variable. Alternatively, you can declare a cursor for the query without first preparing the query and include the INTO clause in the query when you declare the cursor. Then open the cursor, and fetch the cursor without using the INTO clause of the FETCH statement.
In ESQL/C, if you use a DECLARE statement with a SELECT statement that contains an INTO clause, and the program variable is an array element, you can identify individual elements of the array with integer constants or with variables. The value of the variable that is used as a subscript is determined when the cursor is declared, so afterward the subscript variable acts as a constant.
The following ESQL/C code example declares a cursor for a SELECT...INTO statement using the variables i and j as subscripts for the array a. After you declare the cursor, the INTO clause of the SELECT statement is equivalent to INTOa[5],a[2].
You can also use program variables in the FETCH statement to specify an element of a program array in the INTO clause. With the FETCH statement, the program variables are evaluated at each fetch rather than when you declare the cursor.
If the data type of the receiving variable does not match that of the selected item, the data type of the selected item is converted, if possible. If the conversion is impossible, an error occurs, and a negative value is returned in the status variable, sqlca.sqlcode, SQLCODE. In this case, the value in the program variable is unpredictable.
![]() In an ANSI-compliant database, if the number of variables that are listed in the INTO clause differs from the number of items in the SELECT clause, you receive an error.
In an ANSI-compliant database, if the number of variables that are listed in the INTO clause differs from the number of items in the SELECT clause, you receive an error.
In ESQL/C, if the number of variables that are listed in the INTO clause differs from the number of items in the SELECT clause, a warning is returned in the sqlwarn structure: sqlca.sqlwarn.sqlwarn3. The actual number of variables that are transferred is the lesser of the two numbers. For information about the sqlwarn structure, see the Informix ESQL/C Programmer's Manual.
The FROM clause lists the table or tables from which you are selecting the data. The following diagrams show the syntax of the FROM clause.

|
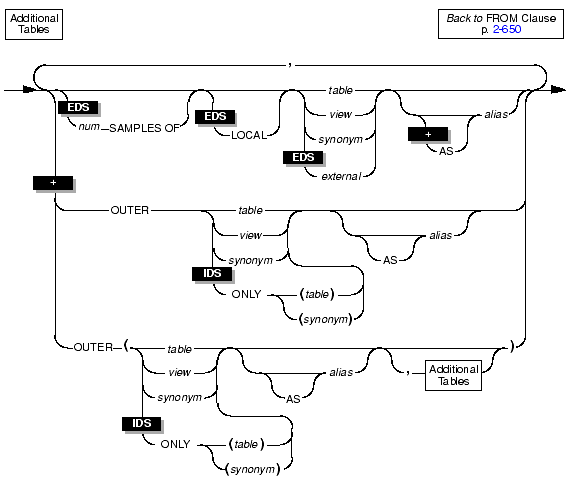
|
Use the keyword OUTER to form outer joins. Outer joins preserve rows that otherwise would be discarded by simple joins. If you have a complex outer join, that is, the query has more than one outer join, you must embed the additional outer join or joins in parentheses as the syntax diagram shows. For more information on outer joins, see the Informix Guide to SQL: Tutorial.
When one of the tables to be joined is a collection, the FROM clause cannot have a join. This restriction applies when you use a collection variable to hold your collection derived table. For more information, see Collection Derived Table.
You can supply an alias for a table name or view name in the FROM clause. If you do so, you must use the alias to refer to the table or view in other clauses of the SELECT statement. Aliases are especially useful with a self-join. For more information about self-joins, see WHERE Clause.
The following example shows typical uses of the FROM clause. The first query selects all the columns and rows from the customer table. The second query uses a join between the customer and orders table to select all the customers who have placed orders.
The following example is the same as the second query in the preceding example, except that it establishes aliases for the tables in the FROM clause and uses them in the WHERE clause:
The following example uses the OUTER keyword to create an outer join and produce a list of all customers and their orders, regardless of whether they have placed orders:
To use potentially ambiguous words as an alias for a table or view, you must precede them with the keyword AS. Use the AS keyword if you want to use the words ORDER, FOR, AT, GROUP, HAVING, INTO, UNION, WHERE, WITH, CREATE, or GRANT as an alias for a table or view.
If you do not assign an alias name to a collection derived table, the database server assigns an implementation-dependent name to it.
If you use the SELECT statement to query a supertable, rows from both the supertable and its subtables are returned. To query rows from the supertable only, you must include the ONLY keyword in the FROM clause, as shown in the following example:
In Enterprise Decision Server, when you use external tables in joins or subqueries, the following restrictions apply:
For more information on subqueries, refer to your Performance Guide.
In Enterprise Decision Server, the LOCAL table feature allows client applications to read data only from the local fragments of a table. In other words, it allows the application to read only the fragments that reside on the coserver to which the client is connected.
This feature provides application partitioning. An application can connect to multiple coservers, execute a LOCAL read on each coserver, and assemble the final result on the client machine.
You qualify the name of a table with the LOCAL keyword to indicate that you want to retrieve rows from fragments only on the local coserver. The LOCAL keyword has no effect on data that is retrieved from nonfragmented tables.
When a query involves a join, you must plan carefully if you want to extract data that the client can aggregate. The simplest way to ensure that a join will retrieve data suitable for aggregation is to limit the number of LOCAL tables to one. The client can then aggregate data with respect to that table.
The following example shows a query that returns data suitable for aggregation by the client:
The following example shows data that the client cannot aggregate:
The client must submit exactly the same query to each coserver to retrieve data that can be aggregated.
In Enterprise Decision Server, sampled queries are supported. Sampled queries are queries that are based on sampled tables. A sampled table is the result of randomly selecting a specified number of rows from the table, rather than all rows that match the selection criteria.
You can use a sampled query to gather quickly an approximate profile of data within a large table. If you use a sufficiently large sample size, you can examine trends in the data by sampling the data instead of scanning all the data. In such cases, sampled queries can provide better performance than scanning the data.
To indicate that a table is to be sampled, specify the number of samples to return in the SAMPLES OF option of the FROM clause within the SELECT statement. You can run sampled queries against tables and synonyms, but not against views. Sampled queries are not supported in the INSERT, DELETE, UPDATE, or other SQL statements.
A sampled query has at least one sampled table. You do not need to sample all tables in a sampled query. You can specify the SAMPLES OF option for some tables in the FROM clause but not specify it for other tables.
The sampling method is known as sampling without replacement. This term means that a sampled row is not sampled again. The database server applies selection criteria after samples are selected. Therefore, the database server uses the selection criteria to restrict the sample set, not the rows from which it takes the sample.
If a table is fragmented, the database server divides the specified number of samples among the fragments. The number of samples from a fragment is proportional to the ratio of the size of a fragment to the size of the table. In other words, the database server takes more samples from larger fragments.
 Important: You must run UPDATE STATISTICS LOW before you run the query with the SAMPLES OF option. If you do not run UPDATE STATISTICS, the SAMPLE clause is ignored, and all data is returned. For better results, Informix recommends that you run UPDATE STATISTICS MEDIUM before you run the query with the SAMPLES OF option.
Important: You must run UPDATE STATISTICS LOW before you run the query with the SAMPLES OF option. If you do not run UPDATE STATISTICS, the SAMPLE clause is ignored, and all data is returned. For better results, Informix recommends that you run UPDATE STATISTICS MEDIUM before you run the query with the SAMPLES OF option.
The results of a sampled query will contain a certain amount of deviation from a complete scan of all rows. However, you can reduce this expected error to an acceptable level by increasing the proportion of sampled rows to actual rows. When you use sampled queries in joins, the expected error increases dramatically; you must use larger samples in each table to retain an acceptable level of accuracy.
For example, you might want to generate a list of how many of each part is sold from the parts_sold table, which is known to contain approximately 100,000,000 rows. The following query provides a sampling ratio of one percent and returns an approximate result:
The SELECT statement in conjunction with the Collection Derived Table segment allows you to select elements from a collection variable.
The Collection Derived Table segment identifies the collection variable from which to select the elements. For more information, see Collection Derived Table.
Using Collection Variables with SELECTWhen you want to modify the contents of a collection, you can use the SELECT statement with a collection variable in different ways:
For more information, see the Collection Derived Table segment and the INSERT, UPDATE, or DELETE statements.
The SELECT statement with the Collection Derived Table segment allows you to select fields from a row variable. The Collection Derived Table segment identifies the row variable from which to select the fields. For more information, see Collection Derived Table.
To select fields, follow these steps:
The SELECT statement and the Collection Derived Table segment allow you to select a particular field or group of fields in the row variable. The INTO clause identifies the variable that holds the field value selected from the row variable. The data type of the host variable in the INTO clause must be compatible with the field type.
For example, the following code fragment puts the value of the width field into the rect_width host variable:
The SELECT statement on a row variable has the following restrictions:
You can modify the row variable with the Collection Derived Table segment of the UPDATE statements. (The INSERT and DELETE statements do not support a row variable in the Collection Derived Table segment.) The row variable stores the fields of the row. However, it has no intrinsic connection with a database column. Once the row variable contains the correct field values, you must then save the variable into the row column with one of the following SQL statements:
For more information on how to use SPL row variables, see the Informix Guide to SQL: Tutorial. For more information on how to use ESQL/C row variables, see the discussion of complex data types in the Informix ESQL/C Programmer's Manual.
Use the WHERE clause to specify search criteria and join conditions on the data that you are selecting.

|
| Element | Purpose | Restrictions | Syntax |
|---|---|---|---|
| subquery | Embedded query | The subquery cannot contain either the FIRST or the ORDER BY clause. | SELECT, p. 2-634 |
You can use the following kinds of simple conditions or comparisons in the WHERE clause:
You also can use a SELECT statement within the WHERE clause; this is called a subquery. The following list contains the kinds of subquery WHERE clauses:
Examples of each type of condition are shown in the following sections. For more information about each kind of condition, see Condition.
You cannot use an aggregate function in the WHERE clause unless it is part of a subquery or if the aggregate is on a correlated column originating from a parent query and the WHERE clause is within a subquery that is within a HAVING clause.
Relational-Operator ConditionFor a complete description of the relational-operator condition, see Relational-Operator Condition.
A relational-operator condition is satisfied when the expressions on either side of the relational operator fulfill the relation that the operator set up. The following SELECT statements use the greater than (>) and equal (=) relational operators:
For a complete description of the BETWEEN condition, see BETWEEN Condition.
The BETWEEN condition is satisfied when the value to the left of the BETWEEN keyword lies in the inclusive range of the two values on the right of the BETWEEN keyword. The first two queries in the following example use literal values after the BETWEEN keyword. The third query uses the built-in CURRENT function and a literal interval. It looks for dates between the current day and seven days earlier.
For a complete description of the IN condition, see IN Subquery.
The IN condition is satisfied when the expression to the left of the IN keyword is included in the list of values to the right of the keyword. The following examples show the IN condition:
For a complete description of the IS NULL condition, see IS NULL Condition.
The IS NULL condition is satisfied if the column contains a null value. If you use the NOT option, the condition is satisfied when the column contains a value that is not null. The following example selects the order numbers and customer numbers for which the order has not been paid:
For a complete description of the LIKE or MATCHES condition, see LIKE and MATCHES Condition.
The LIKE or MATCHES condition is satisfied when either of the following tests is true:
The following SELECT statement returns all rows in the customer table in which the lname column begins with the literal string 'Baxter'. Because the string is a literal string, the condition is case sensitive.
The following SELECT statement returns all rows in the customer table in which the value of the lname column matches the value of the fname column:
The following examples use the LIKE condition with a wildcard. The first SELECT statement finds all stock items that are some kind of ball. The second SELECT statement finds all company names that contain a percent sign (%). The backslash (\) is used as the standard escape character for the wildcard percent sign (%). The third SELECT statement uses the ESCAPE option with the LIKE condition to retrieve rows from the customer table in which the company column includes a percent sign (%). The z is used as an escape character for the wildcard percent sign (%).
The following examples use MATCHES with a wildcard in several SELECT statements. The first SELECT statement finds all stock items that are some kind of ball. The second SELECT statement finds all company names that contain an asterisk (*). The backslash (\) is used as the standard escape character for the wildcard asterisk (*). The third statement uses the ESCAPE option with the MATCHES condition to retrieve rows from the customer table where the company column includes an asterisk (*). The z character is used as an escape character for the wildcard asterisk (*).
For a complete description of the IN subquery, see IN Condition.
With the IN subquery, more than one row can be returned, but only one column can be returned. The following example shows the use of an IN subquery in a SELECT statement:
For a complete description of the EXISTS subquery, see EXISTS Subquery.
With the EXISTS subquery, one or more columns can be returned.
The following example of a SELECT statement with an EXISTS subquery returns the stock number and manufacturer code for every item that has never been ordered (and is therefore not listed in the items table). It is appropriate to use an EXISTS subquery in this SELECT statement because you need the correlated subquery to test both stock_num and manu_code in the items table.
The preceding example would work equally well if you use a SELECT * in the subquery in place of the column names because you are testing for the existence of a row or rows.
ALL, ANY, SOME SubqueryFor a complete description of the ALL, ANY, SOME subquery, see ALL, ANY, SOME Subquery.
In the following example, the SELECT statements return the order number of all orders that contain an item whose total price is greater than the total price of every item in order number 1023. The first SELECT statement uses the ALL subquery, and the second SELECT statement produces the same result by using the MAX aggregate function.
The following SELECT statements return the order number of all orders that contain an item whose total price is greater than the total price of at least one of the items in order number 1023. The first SELECT statement uses the ANY keyword, and the second SELECT statement uses the MIN aggregate function.
You can omit the keywords ANY, ALL, or SOME in a subquery if you know that the subquery returns exactly one value. If you omit ANY, ALL, or SOME, and the subquery returns more than one value, you receive an error. The subquery in the following example returns only one row because it uses an aggregate function:
You join two tables when you create a relationship in the WHERE clause between at least one column from one table and at least one column from another table. The effect of the join is to create a temporary composite table where each pair of rows (one from each table) that satisfies the join condition is linked to form a single row. You can create two-table joins, multiple-table joins, and self-joins.
The following diagram shows the syntax for a join.
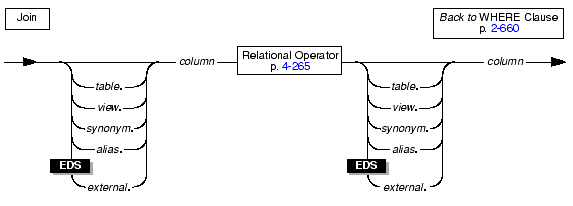
|
The following example shows a two-table join:
 Tip: You do not have to specify the column where the two tables are joined in the SELECT list.
Multiple-Table Joins
Tip: You do not have to specify the column where the two tables are joined in the SELECT list.
Multiple-Table Joins
A multiple-table join is a join of more than two tables. Its structure is similar to the structure of a two-table join, except that you have a join condition for more than one pair of tables in the WHERE clause. When columns from different tables have the same name, you must distinguish them by preceding the name with its associated table or table alias, as in table.column. For the full syntax of a table name, see Database Object Name.
The following multiple-table join yields the company name of the customer who ordered an item as well as the stock number and manufacturer code of the item:
You can join a table to itself. To do so, you must list the table name twice in the FROM clause and assign it two different table aliases. Use the aliases to refer to each of the two tables in the WHERE clause.
The following example is a self-join on the stock table. It finds pairs of stock items whose unit prices differ by a factor greater than 2.5. The letters x and y are each aliases for the stock table.
![]() If you are using Enterprise Decision Server, you cannot use a self-join with an external table.
If you are using Enterprise Decision Server, you cannot use a self-join with an external table.
The following outer join lists the company name of the customer and all associated order numbers, if the customer has placed an order. If not, the company name is still listed, and a null value is returned for the order number.
![]() If you are using Enterprise Decision Server, you cannot use an external table as the outer table in an outer join.
If you are using Enterprise Decision Server, you cannot use an external table as the outer table in an outer join.
For more information about outer joins, see the Informix Guide to SQL: Tutorial.
Use the GROUP BY clause to produce a single row of results for each group. A group is a set of rows that have the same values for each column listed

|
A GROUP BY clause restricts what you can enter in the SELECT clause. If you use a GROUP BY clause, each column that you select must be in the GROUP BY list. If you use an aggregate function and one or more column expressions in the select list, you must put all the column names that are not used as part of an aggregate or time expression in the GROUP BY clause. Do not put constant expressions or BYTE or TEXT column expressions in the GROUP BY list.
If you are selecting a BYTE or TEXT column, you cannot use the GROUP BY clause. In addition, you cannot use ROWID in a GROUP BY clause.
![]() If your select list includes a column with a user-defined data type, the type must either use the built-in bit-hashing function or have its own user-defined hash function. Otherwise, you cannot use a GROUP BY clause.
If your select list includes a column with a user-defined data type, the type must either use the built-in bit-hashing function or have its own user-defined hash function. Otherwise, you cannot use a GROUP BY clause.
The following example names one column that is not in an aggregate expression. The total_price column should not be in the GROUP BY list because it appears as the argument of an aggregate function. The COUNT and SUM keywords are applied to each group, not the whole query set.
If a column stands alone in a column expression in the select list, you must use it in the GROUP BY clause. If a column is combined with another column by an arithmetic operator, you can choose to group by the individual columns or by the combined expression using a specific number.
You can use one or more integers in the GROUP BY clause to stand for column expressions. In the following example, the first SELECT statement uses select numbers for order_date and paid_date - order_date in the GROUP BY clause. Note that you can group only by a combined expression using the select-number notation. In the second SELECT statement, you cannot replace the 2 with the expression paid_date - order_date.
Each row that contains a null value in a column that is specified by a GROUP BY clause belongs to a single group (that is, all null values are grouped together).
Use the HAVING clause to apply one or more qualifying conditions to group

|
In the following examples, each condition compares one calculated property of the group with another calculated property of the group or with a constant. The first SELECT statement uses a HAVING clause that compares the calculated expression COUNT(*) with the constant 2. The query returns the average total price per item on all orders that have more than two items. The second SELECT statement lists customers and the call months if they have made two or more calls in the same month.
You can use the HAVING clause to place conditions on the GROUP BY column values as well as on calculated values. The following example returns the customer_num, call_dtime (in full year-to-fraction format), and cust_code, and groups them by call_code for all calls that have been received from customers with customer_num less than 120:
The HAVING clause generally complements a GROUP BY clause. If you use a HAVING clause without a GROUP BY clause, the HAVING clause applies to all rows that satisfy the query. Without a GROUP BY clause, all rows in the table make up a single group. The following example returns the average price of all the values in the table, as long as more than ten rows are in the table:
Use the ORDER BY clause to sort query results by the values that are contained in one or more columns.
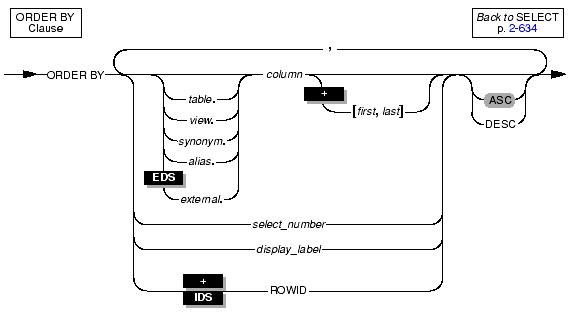
|
You can perform an ORDER BY operation on a column or on an aggregate expression when you use SELECT * or a display label in your SELECT statement.
The following query explicitly selects the order date and shipping date from the orders table and then rearranges the query by the order date. By default, the query results are listed in ascending order.
In the following query, the order_date column is selected implicitly by the SELECT * statement, so you can use order_date in the ORDER BY clause:
You can order by a column substring instead of ordering by the entire length of the column. The column substring is the portion of the column that the database server uses for the sort. You define the column substring by specifying column subscripts (the first and last parameters). The column subscripts represent the starting and ending character positions of the column substring.
The following example shows a SELECT statement that queries the customer table and specifies a column substring in the ORDER BY column. The column substring instructs the database server to sort the query results by the portion of the lname column contained in the sixth through ninth positions of the column:
Assume that the value of lname in one row of the customer table is Greenburg. Because of the column substring in the ORDER BY clause, the database server determines the sort position of this row by using the value burg, not the value Greenburg.
You can specify column substrings only for columns that have a character data type. If you specify a column substring in the ORDER BY clause, the column must have one of the following data types: BYTE, CHAR, NCHAR, NVARCHAR, TEXT, or VARCHAR.
![]() For information on the GLS aspects of using column substrings in the ORDER BY clause, see the Informix Guide to GLS Functionality.
For information on the GLS aspects of using column substrings in the ORDER BY clause, see the Informix Guide to GLS Functionality.
You can order by a derived column by supplying a display label in the SELECT clause, as shown in the following example:
You can use the ASC and DESC keywords to specify ascending (smallest value first) or descending (largest value first) order. The default order is ascending.
For DATE and DATETIME data types, smallest means earliest in time and largest means latest in time. For standard character data types, the ASCII collating sequence is used. For a listing of the collating sequence, see Collating Order for English Data.
Nulls are ordered as less than values that are not null. Using the ASC order, the null value comes before the not-null value; using DESC order, the null comes last.
If you list more than one column in the ORDER BY clause, your query is ordered by a nested sort. The first level of sort is based on the first column; the second column determines the second level of sort. The following example of a nested sort selects all the rows in the cust_calls table and orders them by call_code and by call_dtime within call_code:
In place of column names, you can enter one or more integers that refer to the position of items in the SELECT clause. You can use a select number to order by an expression. For instance, the following example orders by the expression paid_date - order_date and customer_num, using select numbers in a nested sort:
Select numbers are required in the ORDER BY clause when SELECT statements are joined by the UNION or UNION ALL keywords or compatible columns in the same position have different names.
You can specify the rowid column as a column in the ORDER BY clause. The rowid column is a hidden column in nonfragmented tables and in fragmented tables that were created with the WITH ROWIDS clause. The rowid column contains a unique internal record number that is associated with a row in a table. Informix recommends, however, that you utilize primary keys as an access method rather than exploiting the rowid column.
If you want to specify the rowid column in the ORDER BY clause, enter the keyword ROWID in lowercase or uppercase letters.
You cannot specify the rowid column in the ORDER BY clause if the table from which you are selecting is a fragmented table that does not have a rowid column.
You cannot specify the rowid column in the ORDER BY clause unless you have included the rowid column in the select list of the SELECT clause.
For further information on how to use the rowid column in column expressions, see Expression.
In ESQL/C, you cannot use a DECLARE statement with a FOR UPDATE clause to associate a cursor with a SELECT statement that has an ORDER BY clause.
When you include an ORDER BY clause in a SELECT statement, you can improve the performance of the query by creating an index on the column or columns that the ORDER BY clause specifies. The database server uses the index that you placed on the ORDER BY columns to sort the query results in the most efficient manner. For more information on how to create indexes that correspond to the columns of an ORDER BY clause, see Using the ASC and DESC Sort-Order Options under the CREATE INDEX statement.
Use the FOR UPDATE clause when you prepare a SELECT statement, and you intend to update the values returned by the SELECT statement when the values are fetched. Preparing a SELECT statement that contains a FOR UPDATE clause is equivalent to preparing the SELECT statement without the FOR UPDATE clause and then declaring a FOR UPDATE cursor for the prepared statement.
The FOR UPDATE keyword notifies the database server that updating is possible, causing it to use more-stringent locking than it would with a select cursor. You cannot modify data through a cursor without this clause. You can specify particular columns that can be updated.
After you declare a cursor for a SELECT... FOR UPDATE statement, you can update or delete the currently selected row using an UPDATE or DELETE statement with the WHERE CURRENT OF clause. The words CURRENT OF refer to the row that was most recently fetched; they replace the usual test expressions in the WHERE clause.
To update rows with a particular value, your program might contain statements such as the sequence of statements shown in the following example:
A SELECTFOR UPDATE statement, like an update cursor, allows you to perform updates that are not possible with the UPDATE statement alone, because both the decision to update and the values of the new data items can be based on the original contents of the row. The UPDATE statement cannot interrogate the table that is being updated.
A SELECT statement that uses a FOR UPDATE clause must conform to the following restrictions:
For information on how to declare an update cursor for a SELECT statement that does not include a FOR UPDATE clause, see Using the FOR UPDATE Option.
Use the FOR READ ONLY clause to specify that the select cursor declared for the SELECT statement is a read-only cursor. A read-only cursor is a cursor that cannot modify data. This section provides the following information about the FOR READ ONLY clause:
Normally, you do not need to include the FOR READ ONLY clause in a SELECT statement. A SELECT statement is a read-only operation by definition, so the FOR READ ONLY clause is usually unnecessary. However, in certain special circumstances, you must include the FOR READ ONLY clause in a SELECT statement.
![]() If you have used the High-Performance Loader (HPL) in express mode to load data into the tables of an ANSI-compliant database, and you have not yet performed a level-0 backup of this data, the database is in read-only mode. When the database is in read-only mode, the database server rejects any attempts by a select cursor to access the data unless the SELECT or the DECLARE includes a FOR READ ONLY clause. This restriction remains in effect until the user has performed a level-0 backup of the data.
If you have used the High-Performance Loader (HPL) in express mode to load data into the tables of an ANSI-compliant database, and you have not yet performed a level-0 backup of this data, the database is in read-only mode. When the database is in read-only mode, the database server rejects any attempts by a select cursor to access the data unless the SELECT or the DECLARE includes a FOR READ ONLY clause. This restriction remains in effect until the user has performed a level-0 backup of the data.
When the database is an ANSI-compliant database, select cursors are update cursors by default. An update cursor is a cursor that can be used to modify data. These update cursors are incompatible with the read-only mode of the database. For example, the following SELECT statement against the customer_ansi table fails:
The solution is to include the FOR READ ONLY clause in your select cursors. The read-only cursor that this clause specifies is compatible with the read-only mode of the database. For example, the following SELECT FOR READ ONLY statement against the customer_ansi table succeeds:
![]() DB-Access executes all SELECT statements with select cursors. Therefore, you must include the FOR READ ONLY clause in all SELECT statements that access data in a read-only ANSI-mode database. The FOR READ ONLY clause causes DB-Access to declare the cursor for the SELECT statement as a read-only cursor.
DB-Access executes all SELECT statements with select cursors. Therefore, you must include the FOR READ ONLY clause in all SELECT statements that access data in a read-only ANSI-mode database. The FOR READ ONLY clause causes DB-Access to declare the cursor for the SELECT statement as a read-only cursor.
For more information on level-0 backups, see your Backup and Restore Guide. For more information on select cursors, read-only cursors, and update cursors, see DECLARE.
![]() For more information on the express mode of the HPL, see the Guide to the High-Performance Loader.
For more information on the express mode of the HPL, see the Guide to the High-Performance Loader.
You cannot include both the FOR READ ONLY clause and the FOR UPDATE clause in the same SELECT statement. If you attempt to do so, the SELECT statement fails.
For information on how to declare a read-only cursor for a SELECT statement that does not include a FOR READ ONLY clause, see DECLARE.
Use the INTO Table clauses to specify a table to receive the data that the SELECT statement retrieves.

|
The column names of the temporary, scratch, or external table are those that are named in the SELECT clause. You must supply a display label for all expressions other than simple column expressions. The display label for a column or expression becomes the column name in the temporary, scratch or external table. If you do not provide a display label for a column expression, the table uses the column name from the select list.
The following INTO TEMP example creates the pushdate table with two columns, customer_num and slowdate:
When you use an INTO Table clause combined with the WHERE clause, and no rows are returned, the SQLNOTFOUND value is 100 in ANSI-compliant databases and 0 in databases that are not ANSI compliant. If the SELECT INTO
TEMPWHERE statement is a part of a multistatement prepare and no rows are returned, the SQLNOTFOUND value is 100 for both ANSI-compliant databases and databases that are not ANSI-compliant.
In ESQL/C, do not use the INTO clause with an INTO Table clause. If you do, no results are returned to the program variables and the sqlca.sqlcode, SQLCODE variable is set to a negative value.
Use the INTO TEMP clause to create a temporary table that contains the query results. The initial and next extents for a temporary table are always eight pages. The temporary table must be accessible by the built-in RSAM access method of the database server; you cannot specify an alternate access method.
If you use the same query results more than once, using a temporary table saves time. In addition, using an INTO TEMP clause often gives you clearer and more understandable SELECT statements. However, the data in the temporary table is static; data is not updated as changes are made to the tables used to build the temporary table.
You can put indexes on a temporary table.
A logged, temporary table exists until one of the following situations occurs:
![]() If your database does not have logging, the table behaves in the same way as a table that uses the WITH NO LOG option.
If your database does not have logging, the table behaves in the same way as a table that uses the WITH NO LOG option.
Use the WITH NO LOG option to reduce the overhead of transaction logging. (Operations on nonlogging temporary tables are not included in the transaction-log operations.)
A nonlogging, temporary table exists until one of the following situations occurs:
Because nonlogging temp tables do not disappear when the database is closed, you can use a nonlogging temp table to transfer data from one database to another while the application remains connected.
The behavior of a temporary table that you create with the WITH NO LOG option is the same as that of a scratch table.
For more information about temporary tables, see CREATE Temporary TABLE.
If you are using Enterprise Decision Server, use the INTO Scratch clause to reduce the overhead of transaction logging. (Operations on scratch tables are not included in transaction-log operations.)
A scratch table does not support indexes or constraints.
A scratch table exists until one of the following situations occurs:
Because scratch tables do not disappear when the database is closed, you can use a scratch table to transfer data from one database to another while the application remains connected.
A scratch table is identical to a temporary table that is created with the WITH NO LOG option.
For more information about scratch tables, see CREATE Temporary TABLE.
If you are using Enterprise Decision Server, use the INTO EXTERNAL clause to build a SELECT statement that unloads data from your database into an external table.
When you use the INTO EXTERNAL clause to unload data, you create a default external table description. This clause is especially useful for unloading Informix-internal data files because you can use the external table description when you subsequently reload the files.
To obtain the same effect for text tables, issue a CREATE EXTERNAL...SAMEAS statement. Then issue an INSERT INTO...SELECT statement.
Table Options

|
The following table describes the keywords that apply to unloading data. If you want to specify additional table options in the external-table description for the purpose of reloading the table later, see Table Options. In the SELECT...INTO EXTERNAL statement, you can specify all table options that are discussed in the CREATE EXTERNAL TABLE statement except the fixed-format option.
You can use the INTO EXTERNAL clause when the format type of the created data file is either DELIMITED text or text in Informix internal data format. You cannot use it for a fixed-format unload.
For more information on external tables, see CREATE EXTERNAL TABLE.
Place the UNION operator between two SELECT statements to combine the queries into a single query. You can string several SELECT statements together using the UNION operator. Corresponding items do not need to have the same name.
Several restrictions apply on the queries that you can connect with a UNION operator, as the following list describes:
To put the results of a UNION operator into a temporary table, use an INTO TEMP clause in the final SELECT statement.
If you use the UNION operator alone, the duplicate rows are removed from the complete set of rows. That is, if multiple rows contain identical values in each column, only one row is retained. If you use the UNION ALL operator, all the selected rows are returned (the duplicates are not removed). The following example uses the UNION ALL operator to join two SELECT statements without removing duplicates. The query returns a list of all the calls that were received during the first quarter of 1997 and the first quarter of 1998.
If you want to remove duplicates, use the UNION operator without the keyword ALL in the query. In the preceding example, if the combination 101 B were returned in both SELECT statements, a UNION operator would cause the combination to be listed once. (If you want to remove duplicates within each SELECT statement, use the DISTINCT keyword in the SELECT clause, as described in SELECT Clause.)
For task-oriented discussions of the SELECT statement, see the Informix Guide to SQL: Tutorial.
For a discussion of the GLS aspects of the SELECT statement, see the Informix Guide to GLS Functionality.
For information on how to access row and collections with ESQL/C host variables, see the discussion of complex data types in the Informix ESQL/C Programmer's Manual.