| Informix Guide to SQL: Syntax SQL Statements |
|
Use the UPDATE statement to change the values in one or more columns of one or more rows in a table or view.
![]() With Dynamic Server, you can also use this statement to change the values in one or more elements in an ESQL/C collection variable.
With Dynamic Server, you can also use this statement to change the values in one or more elements in an ESQL/C collection variable. 

|
Use the UPDATE statement to update any of the following types of objects:
For information on how to update elements of a collection variable, see Collection Derived Table. The other sections of this UPDATE statement describe how to update a row in a table.
To update data in a table, you must either own the table or have the Update privilege for the table (see GRANT). To update data in a view, you must have the Update privilege, and the view must meet the requirements that are explained in Updating Rows Through a View.
If you omit the WHERE clause, all rows of the target table are updated.
If you are using effective checking, and the checking mode is set to IMMEDIATE, all specified constraints are checked at the end of each UPDATE statement. If the checking mode is set to DEFERRED, all specified constraints are not checked until the transaction is committed.
![]() In Enterprise Decision Server, if the UPDATE statement is constructed in such a way that a single row might be updated more than once, the database server returns an error. However, if the new value is the same in every update, the database server allows the update operation to take place without reporting an error.
In Enterprise Decision Server, if the UPDATE statement is constructed in such a way that a single row might be updated more than once, the database server returns an error. However, if the new value is the same in every update, the database server allows the update operation to take place without reporting an error.
![]() If you omit the WHERE clause and are in interactive mode, DB-Access does not run the UPDATE statement until you confirm that you want to change all rows. However, if the statement is in a command file, and you are running from the command line, the statement executes immediately.
If you omit the WHERE clause and are in interactive mode, DB-Access does not run the UPDATE statement until you confirm that you want to change all rows. However, if the statement is in a command file, and you are running from the command line, the statement executes immediately.
If you use the UPDATE statement to update rows of a supertable, rows from both the supertable and its subtables can be updated. To update rows from the supertable only, you must use the ONLY keyword prior to the table name, as the following example shows:
 Warning: If you use the UPDATE statement on a supertable without the ONLY keyword and without a WHERE clause, all rows of the supertable and its subtables are updated.
Warning: If you use the UPDATE statement on a supertable without the ONLY keyword and without a WHERE clause, all rows of the supertable and its subtables are updated.
You cannot use the ONLY keyword if you plan to use the WHERE CURRENT OF clause to update the current row of the active set of a cursor.
Updating Rows Through a View
You can update data through a single-table view if you have the Update privilege on the view (see GRANT). However, certain restrictions exist. For a view to be updatable, the SELECT statement that defines the view must not contain any of the following items:
In addition, if a view is built on a table that has a derived value for a column, that column is not updatable through the view. However, other columns in the view can be updated.
In an updatable view, you can update the values in the underlying table by inserting values into the view.
You can use data-integrity constraints to prevent users from updating values in the underlying table when the update values do not fit the SELECT statement that defined the view. For more information, see WITH CHECK OPTION Keywords.
Because duplicate rows can occur in a view even though the underlying table has unique rows, be careful when you update a table through a view. For example, if a view is defined on the items table and contains only the order_num and total_price columns, and if two items from the same order have the same total price, the view contains duplicate rows. In this case, if you update one of the two duplicate total price values, you have no way to know which item price is updated.
 Important: If you are using a view with a check option, you cannot update rows to a remote table.
Important: If you are using a view with a check option, you cannot update rows to a remote table.
Updating Rows in a Database Without Transactions
If you are updating rows in a database without transactions, you must take explicit action to restore updated rows. For example, if the UPDATE statement fails after updating some rows, the successfully updated rows remain in the table. You cannot automatically recover from a failed update.
If you are updating rows in a database with transactions, and you are using transactions, you can undo the update using the ROLLBACK WORK statement. If you do not execute a BEGIN WORK statement before the update, and the update fails, the database server automatically rolls back any database modifications made since the beginning of the update.
You can create temporary tables with the WITH NO LOG option. These tables are never logged and are not recoverable.
![]() In Enterprise Decision Server, tables that you create with the RAW table type are never logged. Thus, RAW tables are not recoverable, even if the database uses logging. For information about RAW tables, refer to the Informix Guide to SQL: Reference.
In Enterprise Decision Server, tables that you create with the RAW table type are never logged. Thus, RAW tables are not recoverable, even if the database uses logging. For information about RAW tables, refer to the Informix Guide to SQL: Reference.
![]() If you are updating rows in an ANSI-compliant database, transactions are implicit, and all database modifications take place within a transaction. In this case, if an UPDATE statement fails, you can use the ROLLBACK WORK statement to undo the update.
If you are updating rows in an ANSI-compliant database, transactions are implicit, and all database modifications take place within a transaction. In this case, if an UPDATE statement fails, you can use the ROLLBACK WORK statement to undo the update.
If you are within an explicit transaction, and the update fails, the database server automatically undoes the effects of the update.
When a row is selected with the intent to update, the update process acquires an update lock. Update locks permit other processes to read, or share, a row that is about to be updated but do not let those processes update or delete it. Just before the update occurs, the update process promotes the shared lock to an exclusive lock. An exclusive lock prevents other processes from reading or modifying the contents of the row until the lock is released.
An update process can acquire an update lock on a row or a page that has a shared lock from another process, but you cannot promote the update lock from shared to exclusive (and the update cannot occur) until the other process releases its lock.
If the number of rows affected by a single update is very large, you can exceed the limits placed on the maximum number of simultaneous locks. If this occurs, you can reduce the number of transactions per UPDATE statement, or you can lock the page or the entire table before you execute the statement.
Use the SET clause to identify the columns to update and assign values to each column. The clause supports the following formats:

|
Use the single-column format of the SET clause to pair a single column to a single expression.
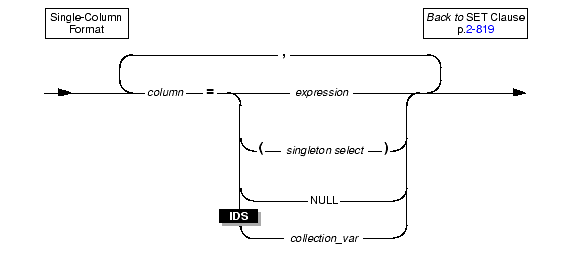
You can include any number of single-columns to single-expressions in the UPDATE statement. For information on how to specify values of a row type column in a SET clause, see Updating Row-Type Columns.
The following examples illustrate the single-column format of the SET clause.
You can update a column with the value that a subquery returns.
![]() If you are updating a supertable in a table hierarchy, the SET clause cannot include a subquery that references a subtable.
If you are updating a supertable in a table hierarchy, the SET clause cannot include a subquery that references a subtable.
If you are updating a subtable in a table hierarchy, a subquery in the SET clause can reference the supertable if it references only the supertable. That is, the subquery must use the SELECTFROM ONLY (supertable)syntax.
You can use the NULL keyword to modify a column value when you use the UPDATE statement. For example, for a customer whose previous address required two address lines but now requires only one, you would use the following entry:
You can specify the same column more than once in the SET clause. If you do so, the column is set to the last value that you specified for the column. In the following example, the user specifies the fname column twice in the SET clause. For the row where the customer number is 101, the user sets fname first to gary and then to harry. After the UPDATE statement executes, the value of fname is harry.
Use the multiple-column format of the SET clause to list multiple columns and set them equal to corresponding expressions.
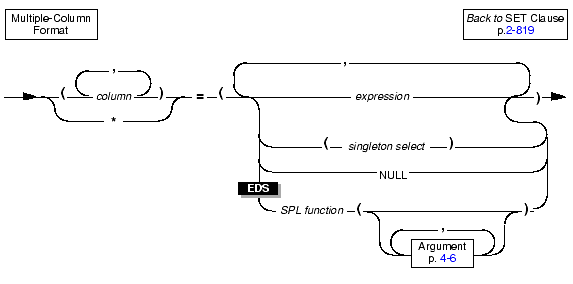
The multiple-column format of the SET clause offers the following options for listing a series of columns you intend to update:
You must list each expression explicitly, placing commas between expressions and enclosing the set of expressions in parentheses. The number of columns in the column list must be equal to the number of expressions in the expression list, unless the expression list includes an SQL subquery.
The following examples show the multiple-column format of the SET clause:
An expression list can include an SQL subquery that returns a single row of multiple values as long as the number of columns named, explicitly or implicitly, equals the number of values produced by the expression or expressions that follow the equal sign.
The following examples show the use of subqueries:
![]() If you are updating the supertable in a table hierarchy, the SET clause cannot include a subquery that references one of its subtables.
If you are updating the supertable in a table hierarchy, the SET clause cannot include a subquery that references one of its subtables.
If you are updating a subtable in a table hierarchy, a subquery in the SET clause can reference the supertable if it references only the supertable. That is, the subquery must use the SELECTFROM ONLY (supertable) syntax.
When you use an SPL function to update column values, the return values of the function must have a one-to-one correspondence with the listed columns. That is, each value that the SPL function returns must be of the data type expected by the corresponding column in the column list.
If the called SPL routine contains certain SQL statements, the database server returns an error. For information on which SQL statements cannot be used in an SPL routine that is called within a data manipulation statement, see Restrictions on an SPL Routine Called in a Data Manipulation Statement.
In the following example, the SPL function p2() updates the i2 and c2 columns of the t2 table.
In Enterprise Decision Server, you create an SPL function with the CREATE PROCEDURE statement. The CREATE FUNCTION statement is not available.
You use the SET clause to update a named row-type or unnamed row-type column. For example, suppose you define the following named row type and a table that contains columns of both named and unnamed row types:
To update an unnamed row type, specify the ROW constructor before the parenthesized list of field values. The following statement updates the name column (an unnamed row type) of the empinfo table:
To update a named row type, specify the ROW constructor before the parenthesized list of field values and use the cast operator (::) to cast the row value as a named row type. The following statement updates the address column (a named row type) of the empinfo table:
For more information on the syntax for ROW constructors, see Constructor Expressions. See also Literal Row.
![]() The row-column SET clause can only support literal values for fields. To use a variable to specify a field value, you must select the row into a row variable, use host variables for the individual field values, then update the row column with the row variable. For more information, see Updating a Row Variable.
The row-column SET clause can only support literal values for fields. To use a variable to specify a field value, you must select the row into a row variable, use host variables for the individual field values, then update the row column with the row variable. For more information, see Updating a Row Variable.
![]() You can use ESQL/C host variables to insert non-literal values as:
You can use ESQL/C host variables to insert non-literal values as:
When you use a row variable in the SET clause, the row variable must contain values for each field value. For information on how to insert values into a row variable, see Updating a Row Variable.
To update only some of the fields in a row, you can perform one of the following operations:
You can use the SET clause to update values in a collection column. For more information, see Collection Constructors.
![]() You can also use a collection variable to update values in a collection column. With a collection variable you can insert one or more individual elements in a collection. For more information, see Collection Derived Table.
You can also use a collection variable to update values in a collection column. With a collection variable you can insert one or more individual elements in a collection. For more information, see Collection Derived Table.
For example, suppose you define the tab1 table as follows:
The following UPDATE statement updates a row in tab1:
The collection column, list1, in this example has three elements. Each element is an unnamed row type with an INTEGER field and a CHAR(5) field. The first element is composed of two literal values, an integer (2) and a quoted string ('zyxwv'). The second and third elements also use a quoted string to indicate the value for the second field. However, they each designate the value for the first field with an expression rather than a literal value.
Some opaque data types require special processing when they are updated. For example, if an opaque data type contains spatial or multirepresentational data, it might provide a choice of how to store the data: inside the internal structure or, for very large objects, in a smart large object.
This processing is accomplished by calling a user-defined support function called assign(). When you execute the UPDATE statement on a table whose rows contain one of these opaque types, the database server automatically invokes the assign() function for the type. The assign() function can make the decision of how to store the data. For more information about the assign() support function, see Extending Informix Dynamic Server 2000.
In Enterprise Decision Server, you can use a join to determine which column values to update by supplying a FROM clause. You can use columns from any table that is listed in the FROM clause in the WHERE clause to provide values for the columns and rows to update.
As indicated in the diagram for UPDATE, you can use only a subset of the FROM clause. You cannot use the LOCAL keyword or the SAMPLES OF segment of the FROM clause with the UPDATE statement.
The following example shows how you can use a FROM clause to introduce tables to be joined in the WHERE clause.
For a complete description of the FROM Clause, see the FROM Clause.
The WHERE clause lets you limit the rows that you want to update. If you omit the WHERE clause, every row in the table is updated.
The WHERE clause consists of a standard search condition. (For more information, see the WHERE Clause). The following example illustrates a WHERE condition within an UPDATE statement. In this example, the statement updates three columns (state, zipcode, and phone) in each row of the customer table that has a corresponding entry in a table of new addresses called new_address.
If you update a table in an ANSI-compliant database with an UPDATE statement that contains the WHERE clause and no rows are found, the database server issues a warning. You can detect this warning condition in either of the following ways:
The database server also sets SQLSTATE and SQLCODE to these values if the UPDATE... WHERE... is a part of a multistatement prepare and the database server returns no rows.
In a database that is not ANSI compliant, the database server does not return a warning when it finds no matching rows for the WHERE clause of an UPDATE statement. The SQLSTATE code is 00000 and the SQLCODE code is zero (0). However, if the UPDATE... WHERE... is a part of a multistatement prepare, and no rows are returned, the database server does issue a warning. It sets SQLSTATE to 02000 and the SQLCODE value to 100.
Use the WHERE CURRENT OF clause to update the current row of the active set of a cursor in the current element of a collection cursor (ESQL/C only).
The UPDATE statement does not advance the cursor to the next row, so the current row position remains unchanged.
![]() You cannot use this clause if you are selecting from only one table in a table hierarchy. That is, you cannot use this option if you use the ONLY keyword.
You cannot use this clause if you are selecting from only one table in a table hierarchy. That is, you cannot use this option if you use the ONLY keyword.
![]() To use the CURRENT OF keywords, you must have previously used the DECLARE statement to define the cursor with the FOR UPDATE option.
To use the CURRENT OF keywords, you must have previously used the DECLARE statement to define the cursor with the FOR UPDATE option.
If the DECLARE statement that created the cursor specified one or more columns in the FOR UPDATE clause, you are restricted to updating only those columns in a subsequent UPDATE...WHERE CURRENT OF statement. The advantage to specifying columns in the FOR UPDATE clause of a DECLARE statement is speed. The database server can usually perform updates more quickly if columns are specified in the DECLARE statement.
![]() Before you can use the CURRENT OF keywords, you must declare a cursor with the FOREACH statement.
Before you can use the CURRENT OF keywords, you must declare a cursor with the FOREACH statement.
 Tip: You can use an update cursor to perform updates that are not possible with the UPDATE statement.
Tip: You can use an update cursor to perform updates that are not possible with the UPDATE statement.
The following ESQL/C example illustrates the CURRENT OF form of the WHERE clause. In this example, updates are performed on a range of customers who receive 10-percent discounts (assume that a new column, discount, is added to the customer table). The UPDATE statement is prepared outside the WHILE loop to ensure that parsing is done only once.
The UPDATE statement with the Collection Derived Table segment allows you to update fields in a row variable. The Collection Derived Table segment identifies the row variable in which to update the fields. For more information, see Collection Derived Table.
To update fields, follow these steps:
The UPDATE statement and the Collection Derived Table segment allow you to update a particular field or group of fields in the row variable. You specify the new field values in the SET clause. For example, the following UPDATE changes the x and y fields in the myrect ESQL/C row variable:
Suppose that after the SELECT statement, the myrect2 variable has the values x=0, y=0, length=8, and width=8. After the UPDATE statement, the myrect2 variable has field values of x=3, y=4, length=8, and width=8.
You cannot use a row variable in the Collection Derived Table segment of an INSERT statement. However, you can use the UPDATE statement and the Collection Derived Table segment to insert new field values into a row host variable, as long as you specify a value for every field in the row. For example, the following code fragment inserts new field values into the myrect row variable and then inserts this row variable into the database:
If the row variable is an untyped variable, you must use a SELECT statement before the UPDATE so that ESQL/C can determine the data types of the fields. An UPDATE of a field or fields in a row variable cannot include a WHERE clause.
The row variable stores the fields of the row. However, it has no intrinsic connection with a database column. Once the row variable contains the correct field values, you must then save the variable into the row column with one of the following SQL statements:
For more information on how to use SPL row variables, see the Informix Guide to SQL: Tutorial. For more information on how to use ESQL/C row variables, see the discussion of complex data types in the Informix ESQL/C Programmer's Manual.
Related statements: DECLARE, INSERT, OPEN, SELECT, and FOREACH
For a task-oriented discussion of the UPDATE statement, see the Informix Guide to SQL: Tutorial.
For a discussion of the GLS aspects of the UPDATE statement, see the Informix Guide to GLS Functionality.
For information on how to access row and collections with ESQL/C host variables, see the discussion of complex data types in the Informix ESQL/C Programmer's Manual.